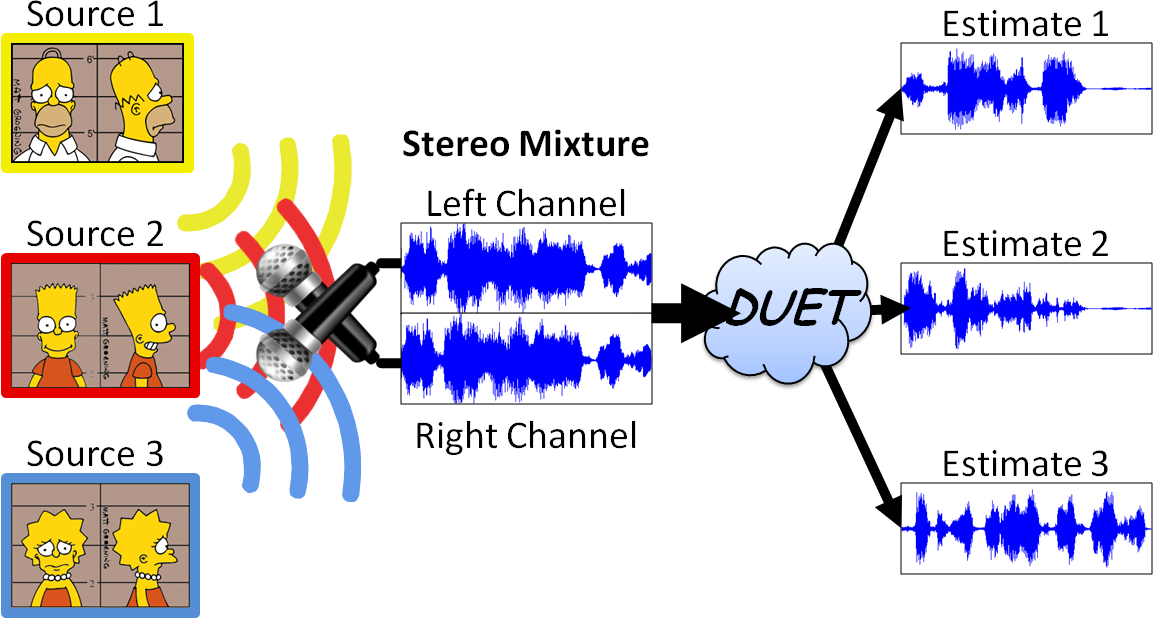
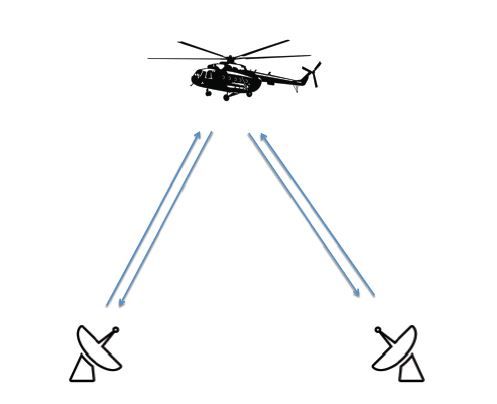
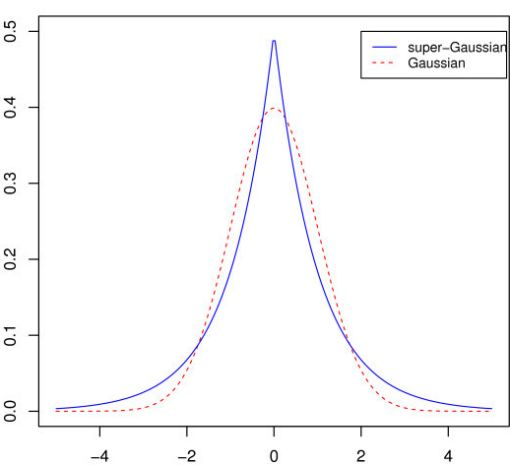
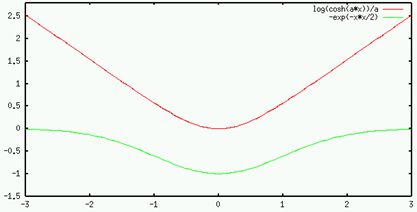
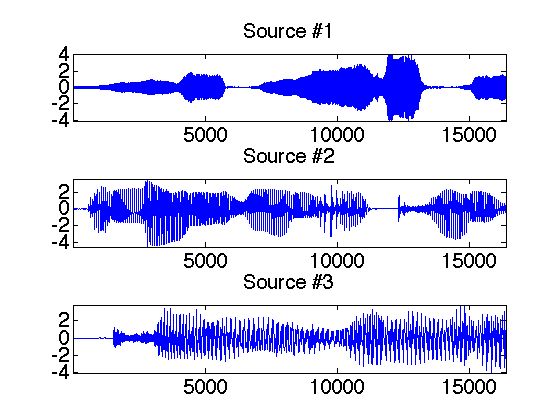
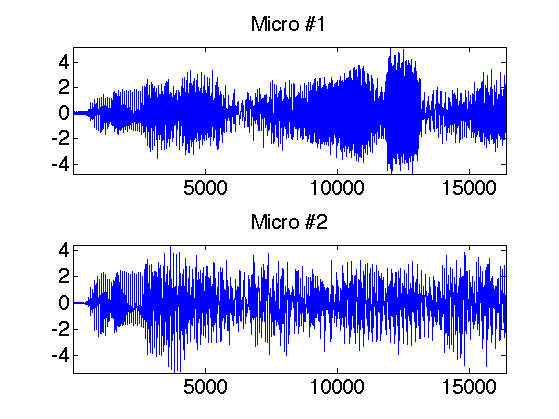
Традиционно для объяснения анализа независимых компонент приводится проблема "разделения смеси". Ну что же, не будем отступать от традиций.
Итак, пусть имеем сигналы \(x_j(t)\) от \(m\) микрофонов, которые воспроизводят \(n\) динамиков \((m\le n)\), нужно на
одном динамике восстановить один голос \(s_i(t)\).
Имеем сигналы от \(m\) микрофонов, которые нужно разложить на составляющие.
Проблема может быть сформулирована следующим образом
Дано
\[
x_i(t)=\sum_{j=1}^na_{i,j}s_j(t), (i=1,...,m)
\]
или в матричной форме
\[
\left(
\begin{array}{c}
x_1\\
\vdots \\
x_m\\
\end{array}
\right)=
\left(
\begin{array}{ccc}
a_{1,1}& \cdots & a_{1,n} \\
\vdots & \ddots & \vdots \\
a_{n,1} & \cdots & a_{m,n} \\
\end{array}
\right)
\left(
\begin{array}{c}
s_1\\
\vdots \\
s_n\\
\end{array}
\right)
\Leftrightarrow \mathbf{x}= \mathbf{A}\mathbf{s}.
\]
Нужно найти
\[
\mathbf{y}= \mathbf{A}^{-1}\mathbf{x}= \mathbf{W}\mathbf{x}.
\]
Таким образом поставленная задача распадается на две - получить
Данная задача носит название - слепое разделение источников (BSS- blind signal separation), то есть, проблема разделения сигналов линейно смешанных источников.
Слово «слепое» означает, что мы не берем на себя никаких предварительных знаний об источниках \(\mathbf{s}\) или о процессе смешения \(\mathbf{A}\),
за исключением условия, что сигналы источников \(s_i(t)\) являются статистически независимыми.
Хотя проблема BSS кажется просто неподъемной, использование анализа независмых компонент позволяет практически найти уникальные решения,
удовлетворяющие данным свойствам.
Метод ICA нашёл применение во многих приложениях, где требуется разделение независимых сигналов, например, беспроводная связь, формирование
диаграммы направленности, извлечение следов газа из гиперспектральных данных, успешно применен метод, использующий ICA комплексного сигнала для обнаружения радиолокационных целей на фоне морских шумов, изучены
пространственные и временные ICA микродоплеровских сигнатур с использованием имитации вращения и перемещения объектов, например,
ICA применяется в частотной области к спектрограммам сигналов, содержащих микродоплеровские компоненты, принадлежащие движущимся лопастям вертолета.
Мультистатическая система с двумя РЛС, освещающими вертолёт.
Одной из основных областей исследований, в которой использовались методы ICA, является обработка биомедицинских сигналов.
В медицине ICA позволяет решить множество проблем, среди которых, автоматический метод, способный справляться с сильными необычными шумами,
присутствующими почти во всех регистрах ЭКГ, обнаружение шумовых компонентов и их удаление из данных ЭКГ.
Основной областью исследования BSS является электроэнцефалография (ЭЭГ), анализ функциональной магнитно-резонансной
томографии (МРТ) и электрокардиография (ЭКГ). За этими тремя основными областями применения следуют несколько небольших областей исследований,
таких как магнитно-резонансная спектроскопия (МРС) или электромиография (ЭМГ).
ICA можно сравнить с применением анализа главных компонент (PCA) для декорреляции. Учитывая множество переменных \(\mathbf{x}\), PCA находит матрицу \(\mathbf{W}\) так,
чтобы компоненты были некоррелированы. Только в частном случае, когда \(\mathbf{y}=[y_1,y_2,\ldots,y_n]\) имеют гауссовские распределения, они также независимы.
Теоретической основой IСА является центральная предельная теорема, в которой говорится о том, что распределение суммы (среднего или линейной
комбинации) от \(N\) независимых случайных величин приближается к гауссовым при \(N\to \infty\). В частности, если \(x_i\) случайные величины
независимые друг от друга, взятые из произвольного распределения со средним \(\mu\) и дисперсией \(\sigma^2\), тогда распределение среднего
\[
\bar{x}=\frac{1}{N}\sum_{i=1}^Nx_i
\]
приближается гауссовским со средним \(\mu\) и дисперсией \(\sigma^2\). Для того, чтобы решить проблему BSS, нужно найти матрицу \(\mathbf{W}\) так, чтобы
\(\mathbf{y}=\mathbf{Wx}=\mathbf{WAs}\approx \mathbf{s}\) было как можно ближе к независимым источникам \(\mathbf{s}\).
Это можно рассматривать как обратный процесс центральной предельной теоремы.
Рассмотрим одну компоненту \(y_i=w^T_i\mathbf{As}\) из \(\mathbf{y}\), где \(w^T_i\) есть \(i\) -я строка \(\mathbf{W}\). Линейная комбинация
\(\mathbf{s}\) всех компонент \(y_i\) обязательно будет более гауссовская, чем любая из компонент, если \(\mathbf{s}\) не равно одной из них
(то есть \(w^T_i\mathbf{A}\) имеет только одну ненулевую компоненту. Другими словами, цель \(\mathbf{y}\approx \mathbf{s}\) может быть достигнута путем поиска \(\mathbf{W}\),
что максимизирует негауссовость из \(\mathbf{y}=\mathbf{Wx}=\mathbf{WAs}\) (так, что \(y\) наименее гауссовская).
В этом суть всех ICA методов. Очевидно, что если все переменные источника гауссовы, метод ICA не будет работать.
Исходя из вышеизложенного, получаем требования и ограничения для методов ICA:
Число наблюдаемых переменных \(m\) не должно быть меньше, чем число независимых источников \(n\) (в дальнейшем предположим, что \(n=m\)).
Компоненты источника стохастически независимы, и должны быть негауссовы (с возможным исключением не более одного гауссова).
Оценка \(\mathbf{A}\) и \(\mathbf{s}\) зависит только от масштабирующего коэффициента \(c_i\). Пусть \(C=diag(c_1,c_2,...,c_n)\), и
\(C^{-1}=diag(1/c_1,1/c_2,...,1/c_n)\), и \(\mathbf{A}'=\mathbf{A}C^{-1}\) и \(\mathbf{s}'=C\mathbf{s}\), тогда имеем
\(\mathbf{x}=\mathbf{As}=(\mathbf{A}C^{-1})(C\mathbf{s})=\mathbf{A's'}\).
Кроме того, коэффициент масштабирования \(c_i\) может быть положительным или отрицательным. По этой причине, мы всегда будем предполагать, что
независимые компоненты имеют единичную дисперсию \(E\left\{s_i^2\right\}=1\). Поскольку они также некоррелированы (все независимые переменные некоррелированы),
то имеем \(E\left\{s_is_j\right\}=\delta_{i,j}\), то есть \(E\left\{SS^T\right\}=I\).
Порядок независимых компонент не имеет значения. Когда порядок соответствующих элементов \(\mathbf{s}\) и \(\mathbf{A}\) меняется, то по- прежнему
имеет место \(\mathbf{x}=\mathbf{As}\).
Все методы ICA основаны на одном и том же фундаментальном подходе - найти матрицу \(\mathbf{W}\), которая максимизирует негауссовости из
\(\mathbf{s}=\mathbf{Wx}\) минимизируя тем самым независимость \(\mathbf{S}\).
Таким образом, метод IСА зависит от определенного измерения негауссовости.
Меры негауссовости
Эксцесс
Эксцесс определяются как нормализованный вид четвертого центрального момента распределения: \(kurt(x)=E\left\{x^4\right\}-3\left(E\left\{x^2\right\}\right)^2\).
Если мы предположим, что \(\mathbf{x}\) имеет нулевое среднее \(\mu_x=E\left\{x\right\}=0\) и единичную дисперсию \(\sigma_x^2=E\left\{x^2\right\}-\mu_x^2=1\), то
\(E\left\{x^2\right\}=1\) и \(kurt(x)=E\left\{x^4\right\}-3\).
Эксцесс измеряет степень пикообразности (остоконечность) распределения и она равна нулю только для
гауссовского распределения. Эксцесс любого другого распределения является либо положительным, если оно super-Gaussian (пикообразней чем гауссовское)
или отрицательное, если оно sub-Gaussian (более полого, чем гауссовское). Таким образом, абсолютное значение эксцесса или квадрата эксцесса может
быть использовано для измерения негауссовости распределения. Однако, эксцесс очень чувствителен к выбросам, что делает его ненадежным измерением негауссовости.
Дифференциальная энтропия - негэнтропия
Энтропия случайной величины \(y\) с функцией плотности \(p(y)\) определяется следующим образом
\[
H(y)=-\int_{-\infty}^{\infty}p(y)\log{p(y)}dy=-E\left\{\log{p_i(y)}\right\}.
\]
Важным свойством гауссовского распределения является то, что оно имеет максимальную энтропию среди всех распределений на всей действительной
оси \((-\infty,\infty)\) (и равномерное распределение имеет максимальную энтропию среди всех распределений над конечным диапазоном.) На основе
этого свойства, дифференциальная энтропия, которая также называется негэнтропия, определяется следующим образом
\[
J(y)=H(y_G)-H(y)\ge 0,
\]
где \(y_G\) является гауссовой переменной с той же дисперсией, что и \(y\). Так как \(J(y)\) всегда больше нуля, если y не является гауссовым, это хорошее измерение негауссовости.
Этот результат может быть обобщен от случайных величин к случайным векторам, таким как \(\mathbf{y}=[y_1,...,y_m]^T\), и мы хотим, чтобы
найти матрицу \(\mathbf{W}\) так, чтобы \(\mathbf{y}=\mathbf{Wx}\) имело максимальную негэнтропию \(J(y)=H(y_G)-H(y)\), т.е. \(\mathbf{y}\)
было наиболее негауссово. Однако, точное значение \(J(\mathbf{y})\) трудно получить, так как для его расчета требуется функция распределения
плотности \(p(y)\).
Аппроксимация негэнтропии.
Негэнтропия может быть аппроксимирована следующим образом
\[
J(y)\approx \frac{1}{12}E\left\{y^3\right\}+\frac{1}{48}kurt(y)^2
\]
Тем не менее, это приближение также страдает от неробастости из-за функции эксцесса. Лучшее приближение
\begin{equation}\label{p}
J(y)\approx \sum_{i=0}^pk_i\left[E\left\{G_i(y)\right\}-E\left\{G_i(g)\right\}\right]^2,
\end{equation}
где \(k_i\) некоторые положительные константы, \(y\), как предполагается, имеет нулевое среднее и единичную дисперсию, и \(g\) является
гауссовой переменной также с нулевым средним и единичной дисперсией. \(G_i\) некоторые функции, такие как
\[
G_1(y)=\frac{1}{a}\log{\cosh(ay)}, G_2(y)=-\exp\left(-\frac{y^2}{2}\right)
\]
где \(1\le a\le 2\) некоторая подходящая константа. Хотя это приближение не может быть точным, но всегда больше нуля, за исключением,
когда \(\mathbf{x}\) гауссовское. В частности, если в (\ref{p}) число слагаемых \(p=1\), тогда имеем
\[J(y)=\left[E\left\{G(y)\right\}-E\left\{G(g)\right\}\right]^2.\]
Поскольку второе слагаемое является константой, мы хотим максимизируя \(E\left\{G(y)\right\}\), максимизировать \(J(y)\).
Минимизация взаимной информации
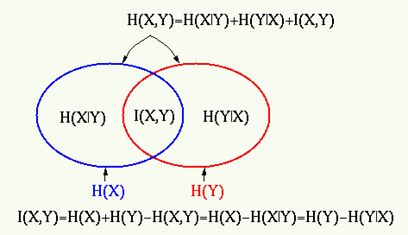
Взаимная информация \(I(x,y)\) двух случайных величин \(x\) и \(y\) определяется как
\[
I(x,y)=H(x)+H(y)-H(x,y)=H(x)-H(x|y)=H(y)-H(y|x).
\]
Очевидно, что если \(x\) и \(y\) являются независимыми, то есть, \(H(y|x)=H(y)\) и \(H(x|y)=H(x)\) их взаимная информация \(I(x,y)\) равна нулю.
Аналогично взаимная информация \(I(y_1,...,y_n)\) набора \(n\) переменных \(y_i(i=1,...,n)\) определяется как
\[
I(y_1,...,y_n)=\sum_{i=1}^nH(y_i)-H(y_1,...,y_n).
\]
Если случайный вектор \(\mathbf{y}=[y_1,...,y_n]^T\) является линейным преобразованием другого случайного вектора \(\mathbf{x}=[x_1,...,x_n]^T\):
\(y_i=\sum_{j=1}^n\omega_{i,j}x_j\) или \(\mathbf{y}=\mathbf{Wx}\), то энтропия \(\mathbf{y}\) связана с \(\mathbf{x}\):
\[
H(y_1,...,y_n):H(x_1,...,x_n)+E\left\{\log J(x_1,...,x_n)\right\}:H(x_1,...,x_n)+\log \det \mathbf{W},
\]
где \(J(x_1,...,x_n)\) якобиан преобразования:
\[
J(x_1,...,x_n)=
\left(
\begin{array}{ccc}
\frac{\partial y_1}{\partial x_1}& \cdots & \frac{\partial y_1}{\partial x_n} \\
\vdots & \ddots & \vdots \\
\frac{\partial y_n}{\partial x_1} & \cdots & \frac{\partial y_n}{\partial x_n} \\
\end{array}
\right)=\det \mathbf{W}.
\]
При этом взаимная информация может быть записана в виде
\[
I(y_1,...,y_n):\sum_{i=1}^nH(y_i)-H(y_1,...,y_n): \sum_{i=1}^nH(y_i)-H(x_1,...,x_n)-\log \det \mathbf{W}.
\]
Кроме того, учитывая предположение, что \(y_i\) декоррелированы с единичной дисперсией, имеем, что ковариационная матрица \(y\) равна
\[
E\left\{yy^T\right\}=\mathbf{W}E\left\{xxT\right\}=I
\]
и ее определитель
\[
\det I=1=(\det \mathbf{W})\left(\det E\left\{xx^T\right\}\right)\left(\det \mathbf{W}^T\right).
\]
Это означает, что \(\det \mathbf{W}\) постоянная ( то же самое для любого \(\mathbf{W}\)). Кроме того, второй член в выражении взаимной
информации \(H(x_1,...,x_n)\) также является постоянной (инвариантной относительно \(\mathbf{W}\)), и мы имеем
\[
I(y_1,...,y_n)=\sum_{i=1}^nH(y_i)+const,
\]
т.е. минимизация взаимной информации \(I(y_1,...,y_n)\) достигается за счет минимизации энтропии
\[
H(y_i)=-\int{p_i(y_i)\log{p_i(y_i)}dy_i}=-E\left\{\log{p_i(y_i)}\right\},
\]
так как гауссовская плотность имеет максимальную энтропию, сведение к минимуму энтропии эквивалентно минимизации гауссовости.
Кроме того, поскольку все \(y_i\) имеют одинаковую единичную дисперсию, их негэнтропия равна
\[
J(y_i)=H(y_G)-H(y_i)=C-H(y_i)
\]
где \(C=H(y_G)\) это энтропия гауссовой величины с единичной дисперсией, одинаковой для всех \(y_i\).
Подставляя \(H(y_i)=C-J(y_i)\) в выражение взаимной информации, с учетом сказанного, получаем
\[
I(y_1,...,y_n)=const -\sum_{i=1}^nJ(y_i),
\]
где \(const\) постоянная (включающая в себя \(C, H(x), \log \det \mathbf{W} \)), которая является одинаковой для матрицы \(\mathbf{W}\)
любого линейного преобразования. Это фундаментальное соотношение между взаимной информацией и негэнтропией переменных \(y_i\).
Если взаимная информация из набора переменных уменьшается ( то есть переменные менее зависимы), то негэнтропия будет увеличена, и
переменная \(y_i\) менее гауссова. Мы хотим найти матрицу \(\mathbf{W}\) линейного преобразования для минимизации взаимной информации
\(I(y_1,...,y_n)\), или, что то же самое, чтобы максимизировать негэнтропию (в предположении, что \(y_i\) некоррелированы).
Предварительная обработка для ICA
Анализ независимых компонент предполагает некоторую предварительную обработку сигналов, эти этапы были рассмотрены в разделе, посвященном
препроцессингу.
Но для упрощения понимания алгоритмов ICA, проведем эти этапы:
Центрирование.
Вычтем среднее \(E\left\{x\right\}\) из наблюдаемой переменной \(\mathbf{x}=\mathbf{As}\), тогда будем иметь нулевое среднее значение. Поступая
таким образом, источник \(\mathbf{s}\) стал иметь нулевое среднее значение, потому что \(E\left\{x\right\}=\mathbf{A}\), \(E\left\{\mathbf{s}\right\}=0\).
Когда матрица смешивания \(\mathbf{A}\) доступна, \(E\left\{\mathbf{s}\right\}\) может быть оценена \(\mathbf{A}^{-1}E\left\{x\right\}\).
Отбеливание.
Под этим термином понимают преобразование наблюдаемых переменных \(\mathbf{x}\), так чтобы они были не коррелированы и имели единичную дисперсию.
Сначала мы получаем собственные числа \(\lambda_i\) и соответствующие им собственные векторы \(\phi_i\) матрицы ковариации \(E\left\{xx^T\right\}\) и
сформируем диагональную матрицу собственных значений \(\Lambda=diag(\lambda_1,...,\lambda_m)\) и ортогональную матрицу собственных векторов
\(\Phi=[\phi_1,...,\phi_m]\) \((\Phi^{-1}=\Phi^T)\). Тогда
\[
E\left\{xx^T\right\}\Phi=\Phi\Lambda, \mbox{ и }\Lambda^{-1/2}\Phi^TE\left\{xx^T\right\}\Phi\Lambda^{-1/2}=I.
\]
Если провести линейное преобразование \(T=\Lambda^{-1/2}\Phi^T\) так, что \(x'=Tx=(\Lambda^{-1/2}\Phi^T)x\) то ковариационная матрица \(x'\) будет
\[
E\left\{x'x'^T\right\}:E\left\{\left(\Lambda^{-1/2}\Phi^Tx\right)\left(\Lambda^{-1/2}\Phi^Tx\right)^T\right\}=E\left\{\Lambda^{-1/2}\Phi^Txx^T\Phi\Lambda^{-1/2}\right\}:
\Lambda^{-1/2}\Phi^TE\left\{xx^T\right\}\Phi\Lambda^{-1/2}=I.
\]
После преобразования \(T=\Lambda^{-1/2}\Phi^T\), получаем процесс смешивания \(x'=Tx=T\mathbf{As}=\mathbf{A's}\).
Новая матрица \(\mathbf{A'}=T\mathbf{A}\) смешивания ортогональна, так как она удовлетворяет условию:
\[
E\left\{x'x'^T\right\}=I=\mathbf{A'}E\left\{ss^T\right\}\mathbf{A'^T},
\]
заметим, что \(E\left\{ss^T\right\}=I\).
Точно так же мы знаем, что матрица \(\mathbf{W}\) также ортогональна
\[
E\left\{ss^T\right\}-I=\mathbf{W}E\left\{x'x'^T\right\}\mathbf{W}^T=\mathbf{WW}^T.
\]
Процесс отбеливания уменьшает количество независимых переменных и, кроме того, может также уменьшить размерность задачи, игнорируя компоненты, соответствующие очень малым собственным значениям (PCA).
Алгоритмы ICA.
Далее рассмотрим основные алгоритмы ICA. Это следующие:
Fast Independent Component Analysis (FastICA). FastICA был введен A.Hyvärinen, E.Oja и
имеет несколько модификаций, основанных на разных целевых функциях.
Fourth-Order Blind Identification (FOBI). Был предложен Cardoso J.F. , алгоритм
FOBI имеет ограничение, в соответствии с которым все компоненты должны иметь разный эксцесс.
Joint Approximate Diagonalization of Eigen matrices (JADE).
Алгоритм JADE является расширением
FOBI и, по всей видимости, является самым популярным алгоритмом ICA.
Algorithm for Multiple Unknown Source Extraction based on EVD (AMUSE).
Алгоритма AMUSE основан на предварительном знании структуры данных - данные являются
сигналами, зависящими от времени.
Second-Order Blind Identification (SOBI).
Алгоритм SOBI является обобщением AMUSE, он использует более одного временного интервала.
Последние два не в полной мере соответствуют алгоритмам ICA, потому что они используют только статистику второго порядка для оценки источника.
Они оценивают источники без независимости, но, тем не менее, они решают проблему BSS.
Алгоритм FastICA.
Резюмируя сказанное ранее, видим, что общая цель максимизации функции \(\sum_iE\left\{G(y_i)\right\}\), где \(y_i=w_i^Tx\) компоненты \(y=\mathbf{W}x\)
\[
\sum_iE\left\{G(y_i)\right\}=\sum_iE\left\{G\left(w_i^Tx\right)\right\}
\]
где \(w_i^T\) вектор \(i\)-й строки матрицы \(\mathbf{W}\). Сначала мы рассмотрим один конкретный компонент (с индексом i).
Это задача оптимизации, которая может быть решена с помощью метода множителей Лагранжа
\[
L(w)=E\left\{G\left(w_i^Tx\right)\right\}-\lambda (w^Tw-1)/2.
\]
Второй член является ограничением, представляющий тот факт, что строки и столбцы ортогональной матрицы \(\mathbf{W}\) нормированы \(w^Tw=1\).
Выпишем условие экстремума, приравняв производную к нулю
\[
F(w)=\frac{\partial L(w)}{\partial w}=E\left\{xg\left(w_i^Tx\right)\right\}-\lambda w=0,
\]
где \(g(z)=\frac{dG(z)}{dz}\) является производной функции \(G(z)\) . Эта алгебраическая система уравнение может быть решено итерационно методом
Ньютона-Рафсона: \(w\Leftarrow w-J^{-1}_F(w)F(w)\), где \(J_F(w)\) -якобиан функции \(F(w)\):
\[
J_F(w)=\frac{\partial F}{\partial w}=E\left\{xx^Tg'\left(w^Tx\right)\right\}-\lambda I.
\]
Первый член в правой части может быть аппроксимирован
\[
E\left\{xx^Tg'\left(w^Tx\right)\right\}\approx E\left\{xx^T\right\}E\left\{g'\left(w^Tx\right)\right\}=E\left\{g'\left(w^Tx\right)\right\}I,
\]
и якобиан становится диагональным
\[
J_F(w)=\left[E\left\{g'\left(w^Tx\right)\right\}-\lambda\right]I,
\]
тогда итерации Ньютона-Рафсона примут вид:
\[
w\Leftarrow w-\frac{1}{E\left\{g'\left(w^Tx\right)\right\}-\lambda}\left[E\left\{xg'\left(w^Tx\right)\right\}-\lambda w\right]I.
\]
Умножив обе стороны на скаляр \(\lambda - E\left\{g'\left(w^Tx\right)\right\}\) получаем
\[
w\Rightarrow E\left\{xg'\left(w^Tx\right)\right\}-E\left\{g'\left(w^Tx\right)\right\}w.
\]
Алгоритм FastICA:
Если не выполняется условие сходимости, перейти к шагу 2.
FOBI
Рассмотрим квадратично взвешенную ковариационную матрицу:
\begin{equation}\label{3.8}
\Omega = E\left\{xx^T\|x\|^2\right\}
\end{equation}
где \(x\) - предварительно отбеленные данные.
Учитывая что данные, предварительно отбеленные по модели ICA, получаем:
\begin{equation}\label{3.9}
Ω = E\left\{VAss^T (VA)^T \|VAs\|^2\right\} = W^T E\left\{ss^T\|s\|^2\right\}W,
\end{equation}
где \(VA\) ортогональна и \(W = (VA)^T\). Используя независимость и единичную дисперсию (что не влияет на свойство независимости сигналов) \(s_i\)
матрицы Ω, что означает:
\[
Ω = W diag \left(E\left\{s^2_i\|s\|^2\right\}\right) W = W diag \left(E\left\{s^2_i\sum_{j=1}^ns^2_j\right\}\right) W =
W diag \left(E\left\{s^2_i\left(s^2_i+\sum_{j=1,j\ne i}^ns^2_j\right)\right\}\right) W =
\]
\begin{equation}\label{3.10}
W diag \left(E\left\{s^4_i\right\}+\sum_{j=1,j\ne i}^nE\left\{s^2_i\right\}E\left\{s^2_j\right\}\right) W =
W diag \left(E\left\{s^4_i\right\}+n-1\right) W.
\end{equation}
Последнее уравнение показывает, что матрицу W можно получить с помощью разложения по собственным значениям матрицы Ω, которая разложена на
диагональную матрицу, состоящую из кумулянтов четвертого порядка \(s_i\) и ортогональной матрицы W.
Этот алгоритм является наиболее эффективным алгоритмом вычисления ICA.
FOBI имеет ограничение, в соответствии с которым алгоритм работает, а именно, все компоненты должны иметь разный эксцесс.
JADE
Этот алгоритм является обощением FOBI.
Для отбеленных данных мы можем записать:
\begin{equation}\label{3.11}
F (M) = E\left\{ \left(x^T Mxxx^T\right) \right\} - 2M - tr (M) I,
\end{equation}
где M - собственная матрица кумулянта, \(x\) - отбеленные данные, I - единичная матрица, tr (M) - след матрицы, определяемый как:
\begin{equation}\label{3.12}
tr (M) = \sum_{i}^nm_{i,i}.
\end{equation}
Используя (\ref{3.11}) отбеленные корреляционные матрицы можно записать в виде:
\begin{equation}\label{3.13}
Ω = F (I) = E\left\{\|x\|^2xx^T \right\} - (n + 2) I.
\end{equation}
Таким образом, можем взять матрицу M и заменить матрицу I в алгоритме FOBI. Эта матрица имела бы линейные комбинации кумулянтов независимых
компонентов в качестве собственных значений. Теперь берем несколько матриц, совместно диагонализируя их и находим лучший результат.
AMUSE
Алгоритм, основан на предварительном знании структуры данных - данные являются сигналами, зависящих от времени.
Рассмотрим временную ковариационную матрицу:
\begin{equation}\label{3.14}
C^x_τ = E\left\{x (t) x^T (t - τ) \right\},
\end{equation}
где x - вектор сигналов в момент времени t, а τ - время запаздывания. Проблема состоит в том, что отбеливание данных не делает данные независимыми.
Ключом к решению этой проблемы дает временная матрица ковариации, ее можно использовать вместо статистики высокого порядка.
Использование запаздывающей ковариационной матрицы дает дополнительную информацию для оценки модели, при определенных условиях
(образцы сигналов должны приниматься в одно и то же время, а задержки корреляций между различными выходными сигналами равны нулю),
и при этом не требуется информация высокого порядка. AMUSE использует простейший случай с одним временным запаздыванием τ. В основном τ равно 1.
Рассмотрим отбеленные данные \(x\), тогда можем написать для разделения матрицы W:
\begin{equation}\label{3.15}
Wx (t) = s (t); Wx (t - τ) = s (t - τ),
\end{equation}
где s - образцы сигналов в заданное время. Далее рассмотрим запаздывающую ковариационную матрицу:
\begin{equation}\label{3.16}
C^x_τ = \frac{1}{2}\left( C_τ^x + (C_τ^x)^T\right).
\end{equation}
Подставляя \(x\) из (\ref{3.15}), получим:
\begin{equation}\label{3.17}
C^x_τ = \frac{1}{2}W^T \left(E\left\{s (t) s^T (t - τ) \right\} + E\left\{s (t - τ) s^T (t) \right\}\right) W = W^TC_τ^sW .
\end{equation}
Из-за независимости сигналов \(s_i (t)\) ковариационная матрица \(C_τ^s\) диагональна, назовем ее D и перепишем предыдущее уравнение:
\begin{equation}\label{3.18}
C^x_τ = W^TDW .
\end{equation}
Из предыдущего можно построить следующий алгоритм:
Отбелим данные х.
Вычислить разложение на собственные значения \(C_τ^x\).
Строки матрицы W задаются собственными векторами.
SOBI
Алгоритм является обощением алгоритма AMUSE - он использует более одного временного интервала τ.
Необходима диагонализация всех соответствующих ковариационных матриц.
Поскольку матрицы ковариации получили разные собственные значения, необходима формулировка функций, выражающих степень диагонализации матриц.
Простой функцией для измерения степени диагонализации матрицы M является:
\begin{equation}\label{3.19}
off (M) = \sum_{i\ne j}m_{i,i},
\end{equation}
являющаяся суммой недиагональных элементов. Желательно минимизировать сумму недиагональных элементов в нескольких матрицах.
Обозначая S, набор выбранных временных интервалов τ для минимизации получаем:
\begin{equation}\label{3.20}
J (W) = \sum_{τ\in S}off (WC^x_τ W^T)^2,
\end{equation}
где J (W) - целевая функция, W - разделительная матрица,\( C^x_τ\) - ковариационная матрица запаздывающих данных x.
Минимизация под этим ограничением дает метод оценки и выполняется методом градиентного спуска или одновременной оценкой разложения собственных
значений для нескольких матриц.
Замечание.
Кумулянты распределения вероятностей представляют собой набор величин, которые обеспечивают альтернативу моментам распределения.
Моменты определяют кумулянты в том смысле, что любые два распределения вероятностей, моменты которых одинаковы, будут иметь одинаковые кумулянты.
Подробнее о кумулянтах.
Первый кумулянт - представляет собой среднее, второй кумулянт - дисперсия, а третий кумулянт - тот же, что и третий центральный момент.
Но кумулянты четвертого и высшего порядка не равны центральным моментам.
В некоторых случаях использование кумулянтов проще, чем использование моментов.
В частности, если две или более случайные величины статистически независимы, то кумулянт n- го порядка их суммы равен сумме их кумулянтов n- го
порядка. Кроме того, кумулянты третьего и высшего порядка нормального распределения равны нулю, и это единственное распределение,
обладающее этим свойством.