Временной ряд – это совокупность наблюдений какого-либо показателя \(Y_t=\{y_{t_0},..., y_{t_{T-1}}\}\) за несколько последовательных моментов или
периодов времени.
Традиционно временные ряды раскладываются на множество компонентов, некоторые из которых могут отсутствовать в том или ином конкретном случае.
Cреди этих компонентов наиболее часто используемыми являются -
Тренд – это долговременная тенденция изменения исследуемого временного ряда. Тренды могут быть описаны различными
уравнениями – линейными, логарифмическими, степенными и так далее.
Цикличность – периодически колебания, наблюдаемые на временных рядах. В случае исследования процессов, завязанных на календарные изменения,
используют сезонную компоненту, как частный, но важный случай цикличности.
Случайная компонента, которая отражает составляющую временного ряда, которую мы не можем объяснить.
Таким образом, пусть \(\{Y_t\}\) - последовательность наблюдений, которые можно записать в следующем виде
\begin{equation}\label{1.1}
Y_t = T_t + C_t + S_t + \varepsilon_t,
\end{equation}
где
\(T_t\) - глобальный тренд,
\(C_t\) - цикличный компонент,
\(S_t\) - сезонная составляющая,
а \(\varepsilon_t\) - нерегулярный компонент.
Такое представление называется аддитивной моделью. В случае, если
\[
Y_t = T_t \cdot C_t \cdot S_t \cdot \varepsilon_t,
\]
модель называется мультипликативной.
Заметим, что мультипликативная модель сводится к аддитивной логарифмированием, поэтому нет необходимости рассмотривать отдельно обе модели, достаточно
исследовать только первый случай.
Анализ временных рядов преследует две цели
Первая цель - дать описание основных компонентов временных рядов.
Достаточно часто нерегулярные и циклические (сезонные) компоненты временного ряда, скрывают те фундаментальные причины, которые породили именно
такой данный ряд, поэтому очистка данных, позволяющая выделить тренд (тенденцию), может помочь в понимании исследуемого процесса.
Другая цель разложения временного ряда - предсказать его будущие значения. Для каждого компонента временного рядов существует свой подходящий конкретный метод
прогнозирования.
Объединив все эти отдельные предсказания компонентов, можно получить прогноз, который по качеству будет превосходить прогноз, полученный
для каждой компоненты в отдельности.
Под детерминированной (закономерной) составляющей временного ряда понимается числовая последовательность \(d_{t_0},..., d_{t_{T-1}}\), элементы
которой вычисляются по определенному правилу как функция времени \(t\).
Если исключить из ряда детерминированную составляющую, то оставшаяся часть будет выглядеть хаотично.
Ее называют случайной компонентой \(\varepsilon_{t_0},..., \varepsilon_{t_{T-1}}\). Таким образом, \(d_{t}=T_{t} + C_{t} + S_{t}\).
При написании данной части использованы примеры из книги D.S.G. Pollock.
Тренды временных рядов
Существует два основных способа извлечения трендов из временных рядов,
первым из которых является применение к ряду разнообразных методов, которые аннулируют (или хотя бы уменьшают влияние) все компоненты, которые не
рассматриваются как тенденции.
Часто для такой цели используют скользящую среднюю, которая охватывает несколько точек данных и придает свой вес каждому значению в них.
При этом сумма весов должна быть равна единице -
\[
y_{t,k}=\frac{\sum_{i=1-k}^{k-1}(k-|i|)y_{t+i}}{\sum_{i=1-k}^{k-1}(k-|i|)} (k=1,2,...).
\]
В частности, если есть данные, которые регистрируют ежеквартальные показатели, то для устранения годового цикла можно использовать соотношение
\[
y_{t,4}=\frac{\sum_{i=-3}^{3}(4-|i|)Y_{t+i}}{16}=\frac{1}{16}(y_{t-3}+2y_{t-2}+3y_{t-1}+4y_{t}+3y_{t+1}+2y_{t+2}+y_{t+3}).
\]
Если исследуемый ряд не завязан на известные и критические календарные или временные изменения, то для этой цели можно использовать
методы сглаживания данных, подробно рассмотренные в разделе, посвященном предобработке данных.
Для того, чтобы принять решение о необходимости сглаживания данных, нужно иметь веские основания, потому что сглаживание представляет собой
положительный оператор и его использование приводит к безвозвратно теряемой части информации.
Одним из таких характеристик является критерий Ирвина.
Согласно этому критерию значение временного ряда является аномальным, если его отличие от предыдущего больше среднеквадратичного отклонения, то есть если
\[
\lambda_i=\frac{|y_t-y_{t-1}|}{\sigma}, \sigma=\sqrt{\frac{\sum_{t=0}^{T-1}\left(y_t-\frac{1}{T}\sum_{\tau=0}^{T-1}y_\tau\right)^2}{T-1}},
\]
то при \(\lambda_i\gt \Lambda\) точка будет аномальной и
T
10
20
30
50
100
200
500
1000
Λ (α=0.05)
1.46
1.27
1.20
1.11
1.02
0.95
0.87
0.83
Λ (α=0.01)
2.03
1.8
1.70
1.60
1.47
1.38
1.28
1.22
Для расчета критических значений критерия Ирвина, с учетом уровня ошибки α, можно использовать следующие соотношения
Альтернативный способ извлечения тренда из имеющихся данных состоит в использовании некоторой функции, которая способна адаптироваться к
форме тренда анализируемого ряда.
Основой этого метода является теорема, доказанная Карлом Вейерштрассом в 1885 году, которая утверждает, что для непрерывных на отрезке
вещественной прямой функций, существует возможность их равномерно приблизить последовательностью многочленов, хотя, следовало бы больше сослаться
на теорему Вейерштрасса — Стоуна, но ее утверждение выходит за рамки нашего обзора.
Таким образом, для выделения тренда подходят дифференцируемые функции.
Более того, как только получим функцию, описывающую тенденции временного ряда, ее можно использовать для экстраполяции, то есть, для получения
прогноза.
Самым популярным средством моделирования тренда, является алгебраический полином r-й степени (см. теорему Вейерштрасса),
аргументом которого является индекс t:
\[
p(t) =a_0 + a_1t + ... +a_r t^r
\]
для распространенных случаев
\(r=1\) - линейная функция,
\(r=2\) - квадратичная функция,
\(r=3\) - кубическая функция.
По сути, это есть описание данных усеченным рядом Тейлора.
Особенностью полиномиальной функции является тот факт, что ее ветви достаточно быстро стремятся к бесконечности, что нежелательно
для функции, которая должна использоваться в экстраполяционном прогнозировании. Именно поэтому степень используемых полиномов невелика, как
правило, ограничена тройкой.
Подробно задача моделирования тренда полиномиальными и некоторыми другими дифференцируемыми функциями рассмотрена в разделе, посвященном
методу наименьших квадратов.
В разного рода экономических задачах широко используются логистические модели. Истоки этой модели лежат в моделировании роста популяции животных в
среде с ограниченными продовольственными ресурсами. Нетрудно видеть обобщение на случай продаж и других задач, связанных с органиченностью ресурсной базы.
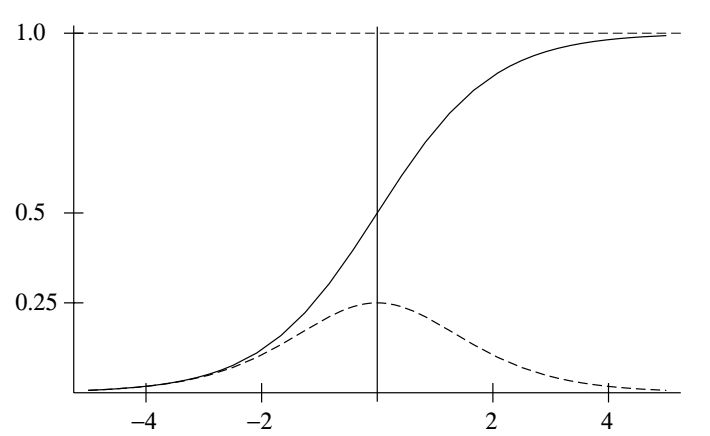
Логистическая функция \(\frac{e^x}{1+e^x}\) и ее производная.
Подробно задача построения логистической и экспоненциальной модели рассмотрена в разделе, посвященном
методу наименьших квадратов.
Выбор функции, аппроксимирующей тренд, как правило, диктуется физической или экономической природой исследуемого процесса.
В случае, если такой информации нет, существуют две крайности - первая из которых состоит в использовании линейной зависимости (делаем хоть как-то), вторая, в
использовании аппарата, позволяющего описать достаточно сложные непрерывные процессы - полиномиальные сплайны, что подробно раcсмотрено в разделе,
посвященном сплайн-регрессионным моделям.
И все же, как выбрать модель тренда, если нет никакой дополнительной информации о его природе. Можно использовать эмпирический подход.
Например, можно построить некие характеризующие данные, по поведению которых можно установить модель тренда исходных данных.
Идея состоит в том, что достаточно просто получить линейную регрессию и оценить качество полученной аппроксимации и по полученным
характеристикам установить какой-же тренд нужно получить.
Положим \(\Delta y_t=\frac{y_{t+1}-y_{t-1}}{2}\) - первая разность и \(\Delta^2 y_t=\frac{\Delta y_{t+1}-\Delta y_{t-1}}{2}\) - вторая разность.
Пусть
Характеризующие данные
Регрессия характеризующих данных
Регрессия исходных данных
Δyt
Постоянная
Линейная регрессия
Δyt
Линейная регрессия
Параболическая регрессия
Δ2yt
Постоянная
Кубическая регрессия
Δyt/yt
Постоянная
Экспоненциальная регрессия
lnΔyt/y2t
Линейная регрессия
Логистическая регрессия
Предложенные модели тренда определяются исходя из гипотезы, что эти тренды существуют. Как проверить так ли это?
Для этого существует несколько подходов, рассмотрим наиболее популярные из них.
Критерий Неймана.
Этот простой критерий основан на вариации последовательных по времени значений выборки, которые принадлежат к нормально распределенной генеральной совокупности
и базируется на дисперсии и среднем квадрате разностей
\[
\sigma^2=\frac{1}{T-1}\sum_{t=0}^{T-1}(y_t-\bar{y})^2,
\bar{y}=\frac{1}{T-1}\sum_{t=0}^{T-1}y_t,
\Delta^2=\frac{1}{T-1}\sum_{t=0}^{T-2}(y_t-y_{t+1})^2.
\]
В основе критерия лежит нуль-гипотеза о том, что последовательные значения тренда независимы, которой противостоит альтернативная гипотеза - значения
взаимосвязаны и, как следствие, существует тренд.
Альтернативная гипотеза принимается в случае, если выполняется условие
\[
\gamma=\frac{\Delta^2}{\sigma^2}=\frac{\sum_{t=0}^{T-2}(y_t-y_{t+1})^2}{\sum_{t=0}^{T-1}(y_t-\bar{y})^2}\le \gamma_\alpha(T),
\]
где \(\alpha-\) уровень значимости и значение правой части затабулировано. Для \(\alpha=0.05\) эти значения равны
Рассмотрим пример.
Пусть есть данные результатов деятельности предприятия
Среднее значение доли рынка равно , дисперсия равна и среднее значение квадрата разностей
.
Тогда
Рассмотрим колебания цен.
Среднее значение цены равно , дисперсия равна и среднее значение
квадрата разностей .
Тогда
Фазо-частотный критерий Уоллиса и Мура.
Этот критерий, в отличие от критерия Неймана, не зависит от распределения \(y_t\). Суть его состоит в выявлении отличия ряда от чисто случайной последовательности.
Если значения временного ряда образуют случайную последовательность, то \(\textrm{sign}(y_{t+1}-y_t)\) представляет собой случайную величину. В этом
суть нуль-гипотезы. Альтернативная гипотеза - последовательность знаков (+ и -) значимо отличается от случайной. Последовательность одинаковых
знаков называется "фазой". В случае, если соседние значения равны между собой, то эта разность не рассматривается.
Если \(\mathcal{L}\) - общее число фаз (без начальной и конечной), и
\[
z=\sqrt{\frac{90}{16T-29}}\left(\left|\mathcal{L}-\frac{2T-7}{3}\right|-0.5\right),
\]
то при \(z\gt z_{0.05}=1.96 (\alpha=5\%)\) статистика распределена нормально, то есть, нуль-гипотеза неверна и тренд существует.
Для нашего примера
Тогда число фаз для доли рынка равна \(\mathcal{L}=\) и z=, то есть,
Для колебаний цены число фаз равно \(\mathcal{L}=\) и z=, то есть,
Метод проверки разностей средних уровней.
Разобъем данный временной ряд из \(T\) значений на два, примерно с одинаковым числом значений, \(n_1\) и \(n_2\) (\(n_1+n_2=T\)) и найдем
для каждой части среднее значение и дисперсию
\[
\tilde{y}_1=\frac{1}{n_1}\sum_{t=0}^{n_1-1}y_t, \sigma_1^2=\frac{1}{n_1-1}\sum_{t=0}^{n_1-1}\left(y_t-\tilde{y}_1\right)^2,
\]
\[
\tilde{y}_2=\frac{1}{n_2}\sum_{t=n_1}^{T-1}y_t, \sigma_1^2=\frac{1}{n_2-1}\sum_{t=n_1}^{T-1}\left(y_t-\tilde{y}_2\right)^2.
\]
Следующим шагом будет проверка гипотезы однородности дисперсий, для чего найдем
\[
F=\left\{
\begin{array}{lll}
\frac{\sigma^2_1}{\sigma^2_2}, & \hbox{ если }& \sigma^2_1\gt \sigma^2_2,\\
\frac{\sigma^2_2}{\sigma^2_1}, & \hbox{ если }& \sigma^2_2\gt \sigma^2_1.
\end{array}
\right.
\]
Если \(F\lt F_{tab}\), то гипотеза однородности дисперсий принимается, иначе этот метод не дает ответа о наличии или отсутствии тренда.
Значения критерия Фишера для 5% уровня ошибки приведены в таблице
T
10
20
30
50
100
Ftab
2.98
2.12
1.84
1.44
1.26
Окончательная проверка существования тренда проводится с использованием t-критерия Стьюдента
\[
t=\frac{|\tilde{y}_1-\tilde{y}_2|}{\tilde{\sigma}\sqrt{\frac{n_1+n_2}{n_1n_2}}},
\]
где \(\sigma-\) среднеквадратичное отклонение разности средних
\[
\tilde{\sigma}=\sqrt{\frac{(n_1-1)\sigma^2_1+(n_2-1)\sigma^2_2}{n_1+n_2-2}}.
\]
Если полученное значение \(t\lt t_{tab}\), то гипотеза принимается, то есть, тренда нет, иначе, тенденция временного ряда существует.
Для определения табличного значения число степеней свободы равно \(n=n_1+n_2-2\).
Значения статистик Стьюдента для уровня ошибки \(\alpha\) приведены в таблице
n
10
20
30
50
100
ttab(α=0.01)
3.1698
2.8453
2.75
2.6778
2.626
ttab(α=0.05)
2.228
2.086
2.042
2.009
1.984
ttab(α=0.1)
1.833
1.725
1.697
1.676
1.66
ttab(α=0.25)
1.221
1.185
1.173
1.164
1.157
Для рассмотренного примера, в случае исследования доли рынка, разобъем весь временной ряд на две части - первая из которых от 1 до \(n_1\), вторая - все остальные,
где \(n_1=18\) и \(n_2=18\). Тогда имеем \(\tilde{y}_1=\), \(\sigma^2_1=\) и
\(\tilde{y}_2=\), \(\sigma^2_2=\). Отсюда получаем \(F=\) . Критерий Фишера для 5%
уровня ошибки позволяет дать заключение о возможности существовании тренда.
Для разброса цен имеем \(\tilde{y}_1=\), \(\sigma^2_1=\) и
\(\tilde{y}_2=\), \(\sigma^2_2=\). Как и в предыдущем случае, критерий Фишера для 5% уровня ошибки
позволяет дать заключение о возможности существовании тренда.
Далее, используя критерий Стьюдента, проведем уточнение.
Для доли рынка \(\tilde{\sigma}=\) и \(t=\). Тренд не существует.
Для цены \(\tilde{\sigma}=\) и \(t=\). Тренд есть.
Метод Фостера-Стьюарта.
Данный метод позволяет более точно ответить на вопрос о существовании тренда временного ряда и, кроме того, дает возможность выяснить наличие тренда у дисперсии.
Отсутствие тренда дисперсии говорит о том, что разброс уровней ряда постоянен, иначе он увеличивается или уменьшается. Эта информация достаточно важна при исследовании временного ряда.
Проведем сравнение каждого уровня ряда с предыдущим и рассмотрим бинарные последовательности
\[
k_t=
\left\{
\begin{array}{ll}
1, & \hbox{ если } y_t \hbox{ больше всех предыдущих уровней},\\
0 & \hbox{ в противном случае},
\end{array}
\right.
\]
\[
l_t=
\left\{
\begin{array}{ll}
1, & \hbox{ если } y_t \hbox{ меньше всех предыдущих уровней},\\
0 & \hbox{ в противном случае},
\end{array}
\right.
\]
где \(t=1,2,3,...,T-1.\)
Найдем величины \(s\) и \(d\), характеризующие изменение временного ряда и дисперсии
\[
s=\sum_{t=1}^{T-1}(k_t+l_t),
d=\sum_{t=1}^{T-1}(k_t-l_t).
\]
Величина \(s\) характеризует изменение временного ряда, она может принимать значение от 0 (когда все уровни ряда равны) до \(T – 1\)
(ряд монотонный). Величина \(d\) характеризует изменение дисперсии временного ряда и изменяется от \(-(T – 1)\)
(ряд монотонно убывает) до \(T – 1\) (ряд монотонно возрастает). Эти величины являются случайными с математическим ожиданием µ для значения s и 0
для значения d.
Проверим гипотезы о случайности отклонения величины s от ее математического ожидания µ и о случайности отклонения величины d от нуля с помощью
критерия Стьюдента для среднего и для дисперсии:
\[
t_s=\frac{|s-\mu|}{\sigma_1},\sigma_1=\sqrt{2\ln{T}-3.4253},
\]
\[
t_d=\frac{|d-0|}{\sigma_2},\sigma_2=\sqrt{2\ln{T}-0.8456},
\]
где \(\mu=\sigma^2_2\) – математическое ожидание величины s для случайного временного ряда; \(\sigma_1\) – среднеквадратичное
отклонение s для случайного временного ряда; \(\sigma_2\)– среднеквадратичное отклонение d для случайного временного ряда.
Полученные значения \(t_s, t_d\) необходимо сравнить с табличными значениями критерия Стьюдента \(t_{tab}\). Если \(t_{tab}\)
больше расчетного значения, то соответствующий тренд отсутствует: т.е., если \(t_s\gt t_{tab}\) (тренд дисперсии существует), а \(t_d\lt t_{tab}\),
то тренд ряда отсутствует.
T
10
15
20
25
30
35
40
45
50
ts
1.964
2.153
2.279
2.373
2.447
2.509
2.561
2.606
2.645
td
1.288
1.521
1.677
1.791
1.882
1.956
2.019
2.072
2.121
Критические значения постоянных критерия Фостера-Стюарта.
Для приведенного примера.
Относительно данных по доле рынка имеем
Отсюда \(s=\) и \(d=\) и \(t_s=\), \(\sigma_1=\), и,
кроме того, \(t_d=\), \(\sigma_2=\). Оба расчетных значения, как \(t_s\), так и \(t_d\) меньше
табличных, то есть, тренда нет, как у данных, так и у дисперсии.
А для цены, соответственно, получаем
соответственно, \(s=\) и \(d=\) и \(t_s=\), \(\sigma_1=\), и,
кроме того, \(t_d=\), \(\sigma_2=\). Так как расчетные значения \(t_s\) и \(t_d\) меньше
табличных, то тренда нет,ни у данных, ни у дисперсии.
Распространенным случаем является наличие тренда как результата накопления небольших стохастических флуктуаций, которые не имеют
систематической основы. Самым распространенным случаем является валютный курс или курс акций на участке стабильности.
В этом случае есть некоторые четко определенные способы удаления тенденции из данных, для экстраполяции ее в будущее.
Простейшей моделью, отражающей стохастический тренд, является так называемое случайное блуждание.
Пусть \(\{y_t\}\) - последовательность случайных величин. Тогда значение в момент времени t получается из предыдущего значения через соотношение
\begin{equation}\label{1.18}
y_t=y_{t-1}+\varepsilon_t,
\end{equation}
где \(\varepsilon_t\) является элементом последовательности белого шума, то есть
\begin{equation}\label{1.19}
E\{\varepsilon_t\}=0,V\{\varepsilon_t\}=\sigma^2, \forall t.
\end{equation}
Отсюда следует
\begin{equation}\label{1.20}
y_t=y_{0}+\varepsilon_1+\varepsilon_2+..+\varepsilon_{t-1}+\varepsilon_t.
\end{equation}
Получаем \(y_t\) как сумму начального значения \(y_0\) и накопления стохастических приращений.
Пример последовательности белого шума.
Если \(y_0\) имеет фиксированное значение, то из (\ref{1.20}) и (\ref{1.19}) среднее и дисперсия \(y_t\) определяются следующим образом
\begin{equation}\label{1.21}
E\{y_t\}=0,V\{y_t\}=t\times \sigma^2.
\end{equation}
Если же исходная точка находится в неопределенном прошлом, а не в момент времени \(t = 0\), то среднее и дисперсия не определены.
Чтобы свести случайное блуждание к стационарному стохастическому процессу, рассмотрим первые разности.
\begin{equation}\label{1.22}
y_t-y_{t-1}=\varepsilon_t,
\end{equation}
Заметим, что если дисперсия белого шума мала, то и значения стохастических приращений также будут малы.
Является спорным, заслуживает ли результат такого процесса быть названным тенденцией.
Предсказание (прогноз) на \(h\) шагов вперед \(\hat{y}_{t+h}\), сделанное в момент \(t\) обозначим через \(\hat{y}_{t+h|t}\).
Нет лучшего способа предсказать результат случайного блуждания, чем взять последнее наблюдаемое значение и экстраполировать его на
бесконечность в будущее. То есть, в качестве ожидаемых значений можно взять
\begin{equation}\label{1.23}
y_{t+h}=y_{t+h-1}+\varepsilon_{t+h}.
\end{equation}
Предсказания \(\hat{y}\), которые обусловлены информацией о множестве \(I = \{y_t,y_{t-1},...\}\), содержащем наблюдения по ряду до момента времени t,
можно обозначить следующим образом:
\begin{equation}\label{1.24}
E\{y_{t+h|I_t}\}=
\left\{
\begin{array}{ll}
\hat{y}_{t+h|t}, & \hbox{ если }h\gt 0, \\
y_{t+h}, & \hbox{ если } h\le 0
\end{array}
\right.
\end{equation}
и, соответственно, если \(h\gt 1\), то можно получить предсказание на шаг вперед
\[
E\{y_{t+h|I_t}\}=\hat{y}_{t+h|t}=\hat{y}_{t+h-1|t},\\
E\{y_{t+1|I_t}\}=\hat{y}_{t+1|t}=y_{t}.
\]
В первом случае из (\ref{1.23}) получаем \(E\{y_{t+h|I_t}\}=0\). Во втором, который исходит из прогноза (\ref{1.22}), используем тот факт, что
\(y_t\) уже известно.
Случайное блуждание первого порядка или просто случайное блуждание — математическая модель процесса случайных изменений в
дискретные моменты времени. При этом предполагается, что изменение на каждом шаге не зависит от предыдущих и от времени.
Случайное блуждание второго порядка формируется путем накопления значений процесса первого порядка.
Таким образом, если \(\{\varepsilon_t\}\) и \(\{y_t\}\) соответственно являются белым шумом и последовательностью случайного блуждания, то
\begin{equation}\label{1.26}
z_{t}=z_{t-1}+y_{t}=z_{t-1}+y_{t-1}+\varepsilon_t=2z_{t-1}-z_{t-2}+\varepsilon_t
\end{equation}
будет случайным блужданием второго порядка.
Случайное блуждание второго порядка и масштабированное соответствующее блуждание первого порядка.
Естественно, что \(y_{t-1}=z_{t-1}-z_{t-2}.\)
Характер процесса случайного блуждания второго порядка можно понять, признав, что он представляет собой тенденцию, для которой
наклон (производная) соответствует порождающему его случайному блужданию.
Если случайное блуждание изменяется медленно, то наклон этого тренда тоже может измениться только постепенно.
Покажем, что предсказание, использующее случайное блуждание второго порядка сводится к линейной аппроксимации.
Из (\ref{1.26}) имеем
\[
E\{z_{t+h|I_t}\}=\hat{z}_{t+h|t}=2\hat{z}_{t+h-1|t}-\hat{z}_{t+h-2|t},\\
E\{z_{t+1|I_t}\}=\hat{z}_{t+1|t}=2z_{t}-z_{t-1},
\]
что позволяет построить простую итерационную схему
\[
\hat{z}_{t+h|t}=\alpha+\beta h, \hbox{ где }\alpha=z_t,\beta=z_t-z_{t-1},
\]
что и генерирует линейный тренд.
Этот подход можно обобщить, построив случайные блуждания высших порядков. Таким образом, случайное блуждание третьего порядка
формируется путем накопления значений процесса второго порядка и при этом, процесс третьего порядка приведет к возникновению
локальных квадратичных тенденций, а соответствующий способ прогнозирования его значений - квадратичная экстраполяция.
Стохастическая тенденция случайных блужданий может быть обобщена путем добавления нерегулярной составляющей.
Простая модель состоит из случайного блуждания первого порядка с добавленной компонентой белого шума.
Модель задается уравнениями
\begin{equation}\label{1.30}
y_t=\xi_t+\zeta_t, \xi_t=\xi_{t-1}+\eta_t,
\end{equation}
где \(\zeta_t\) и \(\eta_t\) генерируются двумя взаимно независимыми белыми шумовыми процессами.
Отсюда получаем
\[
y_t-y_{t-1}=\xi_{t}-\xi_{t-1}+\zeta_t-\zeta_{t-1}=\eta_t+\zeta_t-\zeta_{t-1}.
\]
Последнее выражение перепишем в виде
\[
\eta_t+\zeta_t-\zeta_{t-1}=\varepsilon_t-\mu\varepsilon_{t-1},
\]
где \(\varepsilon_t\) и \(\varepsilon_{t-1}\) являются элементами последовательности белого шума и \(\mu\) является параметром
соответствующего значения. Таким образом, комбинация случайного блуждания и белого шума приводит к единственному уравнению
\begin{equation}\label{1.33}
y_t=y_{t-1}+\varepsilon_t-\mu\varepsilon_{t-1}.
\end{equation}
Прогноз на h шагов вперед, который получается из соотношения
\[
y_{t+h}=y_{t+h-1}+\varepsilon_{t+h}-\mu\varepsilon_{t+h-1}
\]
позволяет записать
\[
E\{y_{t+h|I_t}\}=\hat{y}_{t+h|t}=\hat{y}_{t+h-1|t}.
\]
Получаем прогноз на один шаг вперед
\begin{equation}\label{1.35}
E\{y_{t+1|I_t}\}=\hat{y}_{t+1|t}=y_{t}-\mu\varepsilon_t=y_t-\mu(y_t-\hat{y}_{t|t-1})=(1-\mu)y_t+\mu\hat{y}_{t|t-1}.
\end{equation}
Отсюда получаем
\begin{equation}\label{1.36}
\hat{y}_{t+1|t}=(1-\mu)(y_t+\mu y_{t-1}+...+\mu^{t-1}y_1)+\mu^t\hat{y}_{0}
\end{equation}
и в случае, если стартовое значение не определено, то
\[
\hat{y}_{t+1|t}=(1-\mu)(y_t+\mu y_{t-1}+\mu^{2}y_{t-1}+...).
\]
Полученное равенство называется экспоненциально-взвешенной скользящей средней и является основой широко используемой процедуры
прогнозирования, известной как экспоненциальное сглаживание.
Нетрудно видеть, что экспоненциальное среднее скользящее считает более поздние данные более важными, что является критичным во многих, как
технических, так и экономических задачах.
Сезонные и цикличные компоненты во временных рядах
Те или иные регулярные явления в природе, технике, в нашей жизни, встречаются постоянно - это времена года, это сон-бодрствование, все что
связано с переменным током, так или иначе завязано на 50 или 60 Гц (60 Гц — это принято в США и Канаде), в экономике, это
циклы Кондратьева и так далее.
В чистом, рафинированном виде (без ускорения и помех) циклические изменения можно зависать в виде
\begin{equation}\label{2.1}
x(t) = \rho \cos (\omega t -\theta),
\end{equation}
где
\(\rho\) - амплитуда,
\(\omega\)- угловая скорость или частота,
θ - смещение фазы.
Здесь величина \(2\pi/\omega\) равна периоду цикла, а фазовое смещение указывает угол сдвига вдоль временной оси.
Таким образом, максимальное значение процесса, описываемого соотношением (\ref{2.1}) имеет при значении аргумента \(t = \theta/\omega+2\pi k, k=0,\pm 1,...\).
Используя формулу косинуса разности углов
\(\cos (A-B) = \cos A\cos B + \sin A\sin B,\) можем переписать уравнение (\ref{2.1}) в виде
\begin{equation}\label{2.2}
x = \rho \cos \theta \cos (\omega t) + \rho \sin \theta \sin (\omega t)=\alpha\cos(\omega t)+\beta \sin(\omega t),
\end{equation}
где
\begin{equation}\label{2.3}
\alpha=\rho \cos \theta,
\beta=\sin \theta ,
\alpha^2+\beta^2=\rho^2.
\end{equation}
Нахождение циклического компонента является важным элементом анализа числовых рядов.
Циклический компонент может быть извлечен из последовательности данных путем простого применения метода
линейной регрессии. Уравнение регрессии можно записать в виде
\begin{equation}\label{2.4}
y_t=\alpha c_t(\omega)+\beta s_t(\omega)+e_t, t=0,1,...,T-1,
\end{equation}
где \(c_t(\omega) = \cos (\omega t)\) и \(s_t (\omega) = \sin (\omega t)\).
В матричном виде уравнение (\ref{2.4}) примет вид
\begin{equation}\label{2.5}
y=\left[
\begin{array}{cc}
c & s \\
\end{array}
\right]
\left[
\begin{array}{c}
\alpha \\
\beta \\
\end{array}
\right]+e,
\end{equation}
где \(c=\left[\begin{array}{ccc}c_0 &...& c_{T-1} \\ \end{array}\right]^T\) и \(s = [s_0 ... s_{T-1}]^T \) и \(e = [e_0 ... e_{T-1}] \)
вектора из пространства размерности \(T\).
Параметры \(\alpha,\beta\) можно найти, применяя метод наименьших квадратов, что обеспечивает наименьшее значение суммы квадратов ошибки.
Такая методика может быть использована для извлечения сезонного компонента из экономического временного ряда. В этом случае, мы заранее знаем,
какую важность имеет значение \(\omega\), поскольку сезонность экономической деятельности связана, в конечном счете, с почти идеальными
закономерностями фукционирования солнечной системы, которые отражаются в годовом календаре.
В рассматриваемом случае имеет место необоснованное ожидание, что идеализированный сезонный цикл может быть представлен простой синусоидой.
Волновые формы более сложного характера могут быть синтезированы с использованием ряда синусоидальных и косинусных
функций, частоты которых являются целыми, кратными основной сезонной частоте. Если есть \(s = 2n\) равномерных наблюдений в год, то общая модель
сезонных изменений будет содержать частоты
\begin{equation}\label{2.6}
\omega_j=\frac{2\pi j}{s},j=0,...,n=\frac{s}{2},
\end{equation}
которые равномерно расположены на интервале \([0,\pi]\). Такая серия частот описывается как гармоническая шкала.
В этом случае модель сезонных изменений, включающая полный набор гармонически связанных частот, будет иметь вид
\begin{equation}\label{2.7}
y_t=\sum_{j=0}^n\left\{\alpha_j\cos(\omega_jt)+\beta_j\sin(\omega_jt)\right\}+e_t,
\end{equation}
где \(e_t\) - остаточный элемент, который может представлять собой нерегулярную составляющую белого шума процесса, лежащего в основе
имеющихся данных.
Рисунок 2.1. Тригонометрические функции с частотой \(\omega =\pi/2\) и \(\omega =\pi\).
На первый взгляд, кажется, что в сумме есть s + 2 компонента. Однако, в случае, если s четно, имеем
\[\sin (\omega_0t) = \sin (0) = 0;\\
\cos (\omega_0t) = \cos (0) = 1; \\
\sin (\omega_nt) = \sin (\pi t) = 0; \\
\cos (\omega_nt) = \cos (\pi t) = (-1)^t.
\]
Следовательно, определены только s ненулевых коэффициентов.
Пусть есть четыре наблюдения в год \(\omega_0 = 0, \omega_1 =\pi/2\) и
\(\omega_2=\pi\) тогда
\begin{equation}\label{2.9}
y_t=\alpha_0+\alpha_1\cos\left(\frac{\pi t}{2}\right)+\beta_1\sin\left(\frac{\pi t}{2}\right)+\alpha_2(-1)^t+e_t,
\end{equation}
что в матричном виде
\begin{equation}\label{2.10}
\left[
\begin{array}{c}
y_{\tau_0} \\
y_{\tau_1} \\
y_{\tau_2} \\
y_{\tau_3} \\
\end{array}
\right]=
\left[
\begin{array}{cccc}
1 & 1 & 0 & 1 \\
1 & 0 & 1 & -1 \\
1 & -1 & 0 & 1 \\
1 & 0 & -1 & -1 \\
\end{array}
\right]
\left[
\begin{array}{c}
\alpha_{0} \\
\alpha_{1} \\
\beta_{1} \\
\alpha_{2} \\
\end{array}
\right]
+
\left[
\begin{array}{c}
e_{\tau_0} \\
e_{\tau_1} \\
e_{\tau_2} \\
e_{\tau_3} \\
\end{array}
\right].
\end{equation}
В случае, если данные состоят из наблюдений \(T = 4p\), которые охватывают p лет, коэффициенты уравнения можно определить в следующем виде.
\[
\alpha_0=\frac{1}{T}\sum_{t=0}^{T-1}y_t,
\alpha_1=\frac{2}{T}\sum_{\tau=1}^{p}(y_{\tau_0}-y_{\tau_2}),
\beta_1=\frac{2}{T}\sum_{\tau=1}^{p}(y_{\tau_1}-y_{\tau_3}),
\alpha_2=\frac{1}{T}\sum_{\tau=1}^{p}(y_{\tau_0}-y_{\tau_1}+y_{\tau_2}-y_{\tau_3}).
\]
Альтернативная модель сезонности, которая чаще всего используется экономистами, имеет для каждого сезона свою переменную.
Так, вместо уравнения (\ref{2.10}), можем взять
\begin{equation}\label{2.12}
\left[
\begin{array}{c}
y_{\tau_0} \\
y_{\tau_1} \\
y_{\tau_2} \\
y_{\tau_3} \\
\end{array}
\right]=
\left[
\begin{array}{cccc}
1 & 0 & 0 & 0 \\
0 & 1 & 0 & 0 \\
0 & 0 & 1 & 0 \\
0 & 0 & 0 & 1 \\
\end{array}
\right]
\left[
\begin{array}{c}
\delta_{0} \\
\delta_{1} \\
\delta_{2} \\
\delta_{3} \\
\end{array}
\right]
+
\left[
\begin{array}{c}
e_{\tau_0} \\
e_{\tau_1} \\
e_{\tau_2} \\
e_{\tau_3} \\
\end{array}
\right].
\end{equation}
где
\[
\delta_j=\frac{4}{T}\sum_{\tau=1}^py_{\tau_j}, j=0,1,2,3.
\]
Используя соотношения (\ref{2.10}) и (\ref{2.12}), легко найти обратное
\begin{equation}\label{2.14}
\left[
\begin{array}{c}
\alpha_0 \\
\alpha_1 \\
\beta_1\\
\beta_2\\
\end{array}
\right]=
\frac{1}{4}
\left[
\begin{array}{cccc}
1 & 1 & 1 & 1 \\
2 & 0 & -2 & 0 \\
0 & 2 & 0 & -2 \\
1 & -1 & 1 & -1 \\
\end{array}
\right]
\left[
\begin{array}{c}
\delta_{0} \\
\delta_{1} \\
\delta_{2} \\
\delta_{3} \\
\end{array}
\right].
\end{equation}
Заметим, что все вышесказанное относится к случаю, когда известна периодическая составляющая временного ряда.
К сожалению, в реальных задачах даже при условии наличия информации о периоде цикла, заменить циклическую компоненту синусоидой
(даже с фазовым сдвигом) не представляется возможным.
Например, известны температурные значения, приведенные в таблице
Графически этот временной ряд выглядит следующим образом
Как видно, даже на этом примере, сезонные изменения достаточно нерегулярны. Чтобы получить модель сезонных изменений, достаточно
модифицировать уравнение гармонического движения (\ref{2.1}), наложив на него возмущающий член, который влияет на амплитуду.
Чтобы смоделировать цикл, который в большей степени определяется случайностью, нужно построить модель, которая имеет случайные эффекты как в
фазе, так и в амплитуде.
Для начала представим себе еще раз точку на окружности окружности радиуса \(\rho\), которая движется с угловой скоростью \(\omega\).
В момент t = 0, когда точка создает положительный угол θ с горизонтальной осью, координаты даются выражением
\begin{equation}\label{2.16}
(\alpha,\beta ) = (\rho \cos\theta, \rho \sin \theta).
\end{equation}
Чтобы определить координаты точки после поворота на угол \(\omega\) за один период времени мы можем рассмотреть компоненты векторов отдельно
\[
(\alpha,0)\stackrel{\mathrm{\omega}}{\longrightarrow} (\alpha\cos\omega,\alpha\sin\omega),\\
(0,\beta)\stackrel{\mathrm{\omega}}{\longrightarrow} (-\beta\sin\omega,\beta\cos\omega).
\]
или совместно, сложив их
\[
(\alpha,\beta)\longrightarrow{\omega} (y,z)=(\alpha\cos\omega-\beta\sin\omega,\alpha\sin\omega+\beta\cos\omega).
\]
В матричном виде получаем следующее преобразование
\begin{equation}\label{2.19}
\left[
\begin{array}{c}
y \\
z \\
\end{array}
\right]=
\left[
\begin{array}{cc}
\cos\omega & -\sin\omega \\
\sin\omega & \cos\omega \\
\end{array}
\right]
\left[
\begin{array}{c}
\alpha \\
\beta \\
\end{array}
\right]
\end{equation}
По сути, это преобразования вращения вокруг начала координат.
Чтобы ввести соответствующие нарушения в движение, можем на каждом шаге добавить случайное нарушение для каждого из его компонентов.
\begin{equation}\label{2.20}
\left[
\begin{array}{c}
y_t \\
z_t \\
\end{array}
\right]=
\left[
\begin{array}{cc}
\cos\omega & -\sin\omega \\
\sin\omega & \cos\omega \\
\end{array}
\right]
\left[
\begin{array}{c}
y_{t-1} \\
z_{t-1} \\
\end{array}
\right]
+\left[
\begin{array}{c}
\xi_{t} \\
\zeta_{t} \\
\end{array}
\right]
\end{equation}
Теперь характер движения радикально изменяется. При такой постановке не существует ограничений на амплитуды, которые компоненты могли бы
приобрести в долгосрочной перспективе, а также тенденция к тому, чтобы фазы их циклов менялись без ограничений.
Тем не менее, в отсутствие необычайно больших возмущений, траектории у и z в течение ограниченного периода времени могут быть похожи на
траектории простых гармонических движений.
Первое из уравнений в матричном выражении можно записать в виде
\begin{equation}\label{2.21}
y_t=cy_{t-1}-sz_{t-1}+\xi_t,
\end{equation}
второе, со сдвижкой на один период, дает
\begin{equation}\label{2.22}
z_{t-1}-cz_{t-2}=sy_{t-2}+\zeta_{t-1}.
\end{equation}
Из (\ref{2.21}) получаем
\[
cy_{t-1}=c^2y_{t-2}-csz_{t-2}+\xi_{t-2}
\]
и из (\ref{2.22}), исключая z, получаем
\begin{equation}\label{2.23}
y_t-cy_{t-1}=cy_{t-1}-c^2y_{t-2}-sz_{t-1}+csz_{t-2}+\xi_{t}-c\xi_{t-1}=
cy_{t-1}-c^2y_{t-2}-s^2y_{t-2}-s\zeta_{t-1}+\xi_t-c\xi_{t-1}.
\end{equation}
Замечая, что \(c^2y_{t-2}+s^2y_{t-2}=y_{t-2}\), то есть (\(\sin^2\omega+\cos^2\omega=1\)), и введя новую переменную
\(\varepsilon_t=\xi_t-s\zeta_{t-1}-c\xi_{t-1}\), получаем
\begin{equation}\label{2.24}
y_t=2\cos\omega y_{t-1}-y_{t-2}+\varepsilon_t.
\end{equation}
Пример псевдоциклической последовательности (\ref{2.24}) при \(\omega=\pi/6.\)
Нужно сказать, что в этом случае \(\{\varepsilon_t\}\) не обязательно является белым шумом. Записывая
\begin{equation}\label{2.25}
\left[
\begin{array}{c}
\xi_t \\
\zeta_t \\
\end{array}
\right]=
\left[
\begin{array}{c}
-\sin\omega \\
\cos\omega \\
\end{array}
\right]
\eta_t,
\end{equation}
можно утверждать, что \(\{\eta_t\}\) есть последовательность из значений белого шума, элементы которой взаимно некоррелированы.
Разложение Фурье временного ряда
Несмотря на то, что описание временного ряда тригонометрическими функциями не является точным средством моделирования циклической
составляющей, есть основание для их использования. Это основание имеет свое название - теорема Дирихле, которая утверждает, что
если функция f(x) имеет конечное количество точек строгого экстремума и может иметь не более чем конечное количество точек разрыва,
причем только первого рода, тогда такая функция разлагается в ряд Фурье. Проблема только в том, что ряд не является конечной
последовательностью и практически вместо ряда нужно использовать конечную сумму
\begin{equation}\label{2.26}
y_t=\sum_{j=0}^n\left\{\alpha_j\cos(\omega_jt)+\beta_j\sin(\omega_jt)\right\}.
\end{equation}
Положим T = 2n четно, эта сумма содержит T функций, и частоты
\[
\omega_j=\frac{2\pi j}{T},j=0,...,n=\frac{T}{2}
\]
которые соответствуют равноотстоящим точкам на промежутке \([0,\pi]\).
При этом в сумме (\ref{2.26}) два значения равны нулю \(\sin(\omega_0t)=\sin 0 \) и \(\sin(\omega_nt)=\sin (\pi t) \).
Отсюда следует, что отображение значений выборок в коэффициенты представляет собой взаимно однозначное обратимое преобразование.
Тот же вывод получаем и в случае, когда Т нечетно.
Угловая скорость \(\omega_j = 2 \pi j/ T\) относится к паре тригонометрических компонентов, которые выполняют j циклов c периодом T.
Наибольшая скорость \(\omega_n = \pi\) соответствует так называемой частоте Найквиста (Nyquist).
Если в сумму в (\ref{2.26}) была включена компонента с частотой, превышающей \(\pi\), то ее эффект был бы неотличим от компонента с
частотой в диапазоне \([0; \pi]\). Чтобы продемонстрировать этот факт, рассмотрим случай косинусной волны с единичной амплитудой и
нулевой фазой, частота которой \(\omega\) лежит в интервале \(\omega\in (\pi,2\pi)\) и пусть \(\hat{\omega}=\pi-\omega\), тогда
\[
\cos(\omega t)=\cos(2\pi-\hat{\omega})t=\cos(2\pi)\cos(\hat{\omega t})+\sin(2\pi)\sin(\hat{\omega t})=\cos(\hat{\omega}t),
\]
то есть, \(\omega\) и \(\hat{\omega}\), наблюдаемо неотличимы.
Периодограмма.
Пусть \(c_j = [c_{0,j},...,c_{T-1,j}]^T\) и \(s_j = [s_{0,j},...,s_{T-1,j}]^T \) - векторы T-мерного пространства, представляющие собой значения
\(\cos(\omega_jt)\) и \(\sin(\omega_jt)\), соответственно. Тогда имеют место условия ортогональности
\[
c^T_ic_j=0, i\ne j;
s^T_is_j=0, i\ne j;
c^T_is_j=0, \forall i,j.
\]
Кроме того,
\[
c^T_0c_0=c^T_nc_n=T;
s^T_0s_0=s^T_ns_n=0;
c^T_jc_j=c^T_jc_j=\frac{T}{2}.
\]
Тогда коэффициенты Фурье можно записать в виде
\[
\alpha_0=\frac{1}{T}\sum_ty_t=\bar{y},
\]
\[
\alpha_j=(c^T_jc_j)^{-1}c^T_jy=\frac{2}{T}\sum_ty_t\cos\omega_jt,
\]
\[
\beta_j=(s^T_js_j)^{-1}s^T_jy=\frac{2}{T}\sum_ty_t\sin\omega_jt.
\]
Отсюда следует
\[
y^Ty=\bar{y}^T\bar{y}+\sum_j\alpha^2_jc^T_jc_j+\sum_j\beta^2_js^T_js_j,
\]
где \(\bar{y}^T=[\bar{y},...,\bar{y}]\) - вектор из повторяющихся средних значений.
Тогда, замечая, что \(y^Ty-\bar{y}^T\bar{y}=(y-\bar{y})^T(y-\bar{y})\), получаем
\begin{equation}\label{2.35}
(y-\bar{y})^T(y-\bar{y})=\frac{T}{2}\sum_j\left(\alpha^2_j+\beta^2_j\right)=\frac{T}{2}\sum_j\rho^2_j.
\end{equation}
Вычисляя дисперсию, получаем
\begin{equation}\label{2.36}
\frac{1}{T}\sum_{t=0}^{T-1}(y_t-\bar{y})^2=\frac{1}{2}\sum_j\left(\alpha^2_j+\beta^2_j\right)=
\frac{2}{T^2}\sum_j\left(\left(\sum_ty_t\cos\omega_jt\right)^2+\left(\sum_ty_t\sin\omega_jt\right)^2\right).
\end{equation}
Доля дисперсии, которая относится к компоненту на частоте \(\omega_j\) равна \(\left(\alpha^2_j+\beta^2_j\right)/2=\rho^2_j/2\), где \(\rho_j\)
- амплитуда компонента.
Число частот Фурье возрастает с той же скоростью, что и размер выборки Т, поэтому, если дисперсия исходных данных остается слабой,
и если в процессе генерации данных нет регулярных гармонических составляющих, то можно ожидать, что доля дисперсии, приписываемой отдельным
частотам, будет уменьшаться по мере увеличения размера выборки.
Если в процессе существует такой регулярный компонент, то можем ожидать, что доля отклонения, приписываемого ему, будет сходиться к
неограниченному значению по мере увеличения размера выборки.
Масштабированное разложение выборочной дисперсии называется периодограммой
\[
I(\omega_j)=T\frac{\alpha^2_j+\beta^2_j}{2}.
\]
Есть много примеров, где оценка перидограммы показала наличие регулярных гармонических составляющих в серии данных,
которые в противном случае могли бы пройти незамеченными. Но, к сожалению, использование периодограммы не есть панацея, в случае наличия
большого количества пиков, использование периодограммы может показать наличие неправильных периодов, что, естественно, приведет к
неправильным результатам анализа временного ряда.
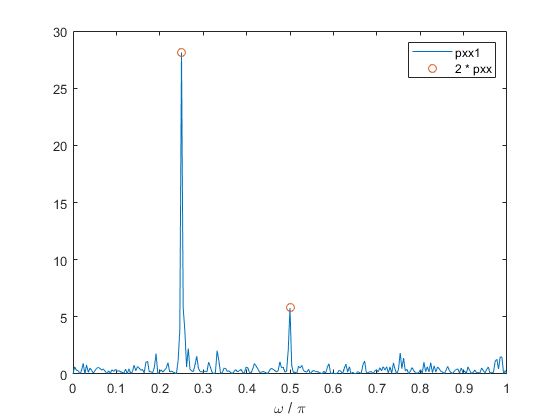
Исходные значения
Периодограмма
Эмпирические автоковариации
Естественным способом представления зависимости элементов последовательности данных является оценка их автоковариаций.
Эмпирическая автоковариация с запаздыванием \(\tau\) определяется следующим образом
\begin{equation}\label{2.37}
c_\tau=\frac{1}{T}\sum_{t=\tau}^{T-1}(y_t-\bar{y})(y_{t-\tau}-\bar{y}).
\end{equation}
Эмпирическая автокорреляция с запаздыванием \(\tau\) равна \(r_\tau = c_\tau/c_0\), где \(c_0\) является автоковариацией отставания 0,
и, по сути, является дисперсией последовательности. Автокорреляция обеспечивает измерение связей точек данных, которые разделены на периоды.
Несложно установить связь между периодограммой и последовательностью автоковариантов.
Периодограмма может быть записана в виде
\begin{equation}\label{2.38}
I(\omega_j)=
\frac{2}{T}\left(\left(\sum_{t=0}^{T-1}(y_t-\bar{y})\cos\omega_jt\right)^2+\left(\sum_{t=0}^{T-1}(y_t-\bar{y})\sin\omega_jt\right)^2\right).
\end{equation}
Заметим, что из равенства \(\sum_t\cos(\omega_jt)=0,\forall j\) получаем \(\sum_t(y_y-\bar{y})\cos(\omega_jt)=\sum_ty_t\cos(\omega_jt)\) и
соотношение (\ref{2.38}) примет вид
\begin{equation}\label{2.39}
I(\omega_j)=
\frac{2}{T}\left(\sum_{t=0}^{T-1}\sum_{\nu=0}^{T-1}(y_t-\bar{y})(y_\nu-\bar{y})\cos\omega_jt\cos\omega_j\nu\right)+
\frac{2}{T}\left(\sum_{t=0}^{T-1}\sum_{\nu=0}^{T-1}(y_t-\bar{y})(y_\nu-\bar{y})\sin\omega_jt\sin\omega_j\nu\right).
\end{equation}
Отсюда и из \(\cos A\cos B+\sin A\sin B=\cos(A-B)\), сразу получаем
\[
I(\omega_j)=
\frac{2}{T}\left(\sum_{t=0}^{T-1}\sum_{\nu=0}^{T-1}(y_t-\bar{y})(y_\nu-\bar{y})\cos\left(\omega_j(t-\nu)\right)\right).
\]
Полагая \(\tau=t-\nu\) и \(c_\tau=\frac{1}{T}\sum_t(y_t-\bar{y})(y_{t-\tau}-\bar{y})\), получаем
\[
I(\omega_j)=
2\sum_{\tau=1-T}^{T-1}\cos\left(\omega_j\tau\right)c_\tau.
\]
преобразование Фурье последовательности эмпирических автоковариаций.
Рассмотрим метод нахождения циклической компоненты с использованием дискретного тригонометрического преобразования со свободным фазовым сдвигом.
Идея алгоритма состоит в следующем - угол фазового сдвига выбирается из условия наилучшего восстановления данных при условии обнуления одного из
частотных коэффициентов, причем на каждом периоде значение квази-периодической функции находятся адаптивно к входным данным на данном интервале.
В основе метода лежит следующее утверждение Теорема А. Пусть \(\varphi\in\left(0,\frac{\pi}{2}\right)\), тогда для произвольных \(\{h_m\}_{m=0}^{N-1}\) таких, что \(-\infty\lt h_m\lt \infty\),
\(m=0,1,...,N-1\) обозначим
\begin{equation}\label{2_1}
H_k=\sum_{m=0}^{N-1}h_m\cos\left(\frac{2\pi m k}{N}-\varphi\right).
\end{equation}
Тогда имеет место равенство
\begin{equation}\label{2_2}
h_n=\frac{2}{N\sin(2\varphi)}\sum_{k=0}^{N-1}H_k\sin\left(\frac{2\pi m k}{N}+\varphi\right).
\end{equation}Доказательство. Покажем, что все это действительно так. Подставим во второе соотношение значения \(H_k\) из первого равенства, тогда получим
\[
\frac{2}{N\sin(2\varphi)}\sum_{k=0}^{N-1}\sum_{m=0}^{N-1}h_m\cos\left(\frac{2\pi m k}{N}-\varphi\right)\sin\left(\frac{2\pi m k}{N}+\varphi\right)
=\frac{2}{N\sin(2\varphi)}\sum_{m=0}^{N-1}h_m\sum_{k=0}^{N-1}\cos\left(\frac{2\pi m k}{N}-\varphi\right)\sin\left(\frac{2\pi m k}{N}+\varphi\right)
=\frac{1}{N\sin(2\varphi)}\sum_{m=0}^{N-1}h_m\sum_{k=0}^{N-1}\left(\sin\left(\frac{2\pi k(n+m)}{N}\right)+
\sin\left(\frac{2\pi k(n-m)}{N}+2\varphi\right)\right).
\]
Далее нам понадобится следующая формула ((Двайт Г.Б. Таблицы интегралов и другие математические формулы / Г.Б.Двайт .— М: Наука, 1973 .— 228 с. ) стр. 82.)
\begin{equation}\label{2_3}
\sum_{\nu=0}^{N-1}\sin(\alpha+\nu\beta)=\frac{1}{\sin\frac{\beta}{2}}\sin\left(\alpha+\frac{N-1}{2}\beta\right)\sin\frac{N\beta}{2}.
\end{equation}
Пусть сначала, \(n+m\ne N\), тогда из (\ref{2_1}) получим,
\[
\sum_{k=0}^{N-1}\sin\left(\frac{2\pi k(n+m)}{N}\right)=\frac{1}{\sin\left(\frac{2\pi (n+m)}{2N}\right)}\sin\left(\frac{2\pi (N-1)(n+m)}{2N}\right)
\sin\left(\frac{2\pi N(n+m)}{2N}\right).
\]
Из условия \(n+m\ne N\) получаем
\[
\sin\left(\frac{2\pi (n+m)}{N}\right)\ne 0,
\]
а, с другой стороны,
\[
\sin\left(\frac{2\pi N(n+m)}{2N}\right)=\sin(\pi(n+m))=0.
\]
Таким образом, для \(n+m\ne N\)
\[
\sum_{k=0}^{N-1}\sin\left(\frac{2\pi k(n+m)}{N}\right)=0.
\]
Если же \(n+m=N\), тогда
\[
\sum_{k=0}^{N-1}\sin\left(\frac{2\pi k(n+m)}{N}\right)=
\sum_{k=0}^{N-1}\sin\left(\frac{2\pi kN}{N}\right)=
\sum_{k=0}^{N-1}\sin\left(2\pi k\right)=0.
\]
Таким образом, для всех \(n,m=0,...,N-1\)
\[
\sum_{k=0}^{N-1}\sin\left(\frac{2\pi k(n+m)}{N}\right)=0.
\]
Рассмотрим теперь,
\[
\sum_{k=0}^{N-1}\sin\left(\frac{2\pi k(n-m)}{N}+2\varphi\right).
\]
Используя (\ref{2_1}), имеем
\[
\sum_{k=0}^{N-1}\sin\left(\frac{2\pi k(n-m)}{N}+2\varphi\right)=\frac{1}{\sin\left(\frac{2\pi (n-m)}{2N}\right)}
\sin\left(\frac{2\pi (N-1)(n-m)}{2N}+2\varphi\right)
\sin\left(\frac{2\pi N(n-m)}{2N}\right).
\]
Далее, отметим, что так как \(n,m=0,...,N-1\), то \(n-m\ne N\). Пусть теперь \(n\ne m\), тогда получается, что
\[
\sin\left(\frac{\pi (n-m)}{N}\right)\ne 0,
\]
но, при этом
\[
\sin\left(\frac{2\pi N(n-m)}{2N}\right)=
\sin\left(\pi (n-m)\right)=0.
\]
для всех \(n,m=0,...,N-1\) и для \(n\ne m\), в том числе.
И наконец, пусть \(n=m\), тогда
\[
\sum_{k=0}^{N-1}\sin\left(\frac{2\pi k(n-m)}{N}+2\varphi\right)=
\sum_{k=0}^{N-1}\sin\left(0+2\varphi\right)=N\sin(2\varphi).
\]
Таким образом имеем
\[
\sum_{k=0}^{N-1}\left(\sin\left(\frac{2\pi k(n+m)}{N}\right)+\sin\left(\frac{2\pi k(n-m)}{N}+2\varphi\right)\right)=
\left\{
\begin{array}{ll}
N\sin(2\varphi), & \hbox{ } n=m, \\
0, & \hbox{ }n,m=0,1,...,N-1,n\ne m.
\end{array}
\right.
\]
Отсюда получим соотношение
\[
\frac{1}{N\sin(2\varphi)}\sum_{m=0}^{N-1}h_m\sum_{k=0}^{N-1}\left(\sin\left(\frac{2\pi k(n+m)}{N}\right)+
\sin\left(\frac{2\pi k(n-m)}{N}+2\varphi\right)\right)=
\left\{
\begin{array}{ll}
h_n, & \hbox{ } n=m, \\
0, & \hbox{ }n,m=0,1,...,N-1,n\ne m,
\end{array}
\right.
\]
что и завершает доказательство теоремы.
Основной результат опирается на следующее утверждение.
Теорема. Для любых \(\{h_m\}_{m=0}^{N-1}\) таких, что \(-\infty\lt h_m\lt \infty\),
\(m=0,1,...,N-1\) обозначим
\[
H_k=\sum_{m=0}^{N-1}h_m\cos\left(\frac{2\pi m k}{N}-\varphi\right)
\]
и
\[
\varphi=\textrm{arctg}\frac{\sum_{m=0}^{N-1}h_m\cos\frac{2\pi m }{N}}{\sum_{m=0}^{N-1}h_m\sin\frac{2\pi m }{N}}.
\]
Тогда имеет место равенство
\begin{equation}\label{2_21}
h_n=\frac{2}{N\sin(2\varphi)}\sum_{k=0}^{N-2}H_k\sin\left(\frac{2\pi m k}{N}+\varphi\right).
\end{equation}
Таким образом, количество слагаемых в (\ref{2_21}), отличие от (\ref{2_2}) сократилось за счет выбора угла \(\varphi\).
Доказательство. Из теоремы А получается, что для произвольного \(\varphi\in\left(0,\frac{\pi}{2}\right)\) и \(n=0,1,...,N-1\)
справедливо соотношение
\begin{equation}\label{2_4}
h_n=\frac{2}{N\sin(2\varphi)}\sum_{k=0}^{N-1}\sum_{m=0}^{N-1}h_m\cos\left(\frac{2\pi m k}{N}-\varphi\right)\sin\left(\frac{2\pi m k}{N}+\varphi\right)
\end{equation}
Пусть \(H_{N-1}=0\), тогда, если угол \(\varphi\) такой, что соотношение (\ref{2_2}) восстанавливает все значения \(\{h_m\}_{m=0}^{N-1}\), то есть
\[
h_n=\frac{2}{N\sin(2\varphi)}\sum_{k=0}^{N-2}H_k\sin\left(\frac{2\pi m k}{N}+\varphi\right),
\]
то это эквивалентно соотношению
\[
h_n=\frac{2}{N\sin(2\varphi)}\left(\sum_{k=0}^{N-1}H_k\sin\left(\frac{2\pi m k}{N}+\varphi\right)-
H_{N-1}\sin\left(\frac{2\pi m (N-1)}{N}+\varphi\right)\right),
\]
или, что то же,
\[
h_n=\frac{2}{N\sin(2\varphi)}\sum_{k=0}^{N-1}\left(\sum_{m=0}^{N-1}h_m\cos\left(\frac{2\pi m k}{N}-\varphi\right)-\sum_{m=0}^{N-1}h_m\cos\left(\frac{2\pi m (N-1)}{N}-\varphi\right)\right)
\sin\left(\frac{2\pi m k}{N}+\varphi\right)=
\]
\[
\frac{2}{N\sin(2\varphi)}\sum_{k=0}^{N-1}\left(\sum_{m=0}^{N-1}h_m\cos\left(\frac{2\pi m k}{N}-\varphi\right)
\right)\sin\left(\frac{2\pi m k}{N}+\varphi\right)
-
\frac{2}{N\sin(2\varphi)}\sum_{k=0}^{N-1}\left(\sum_{m=0}^{N-1}h_m\cos\left(\frac{2\pi m (N-1)}{N}-\varphi\right)
\right)\sin\left(\frac{2\pi m k}{N}+\varphi\right).
\]
Используя равенство (\ref{2_3}), получаем, что для всех \(n=0,1,...,N-1\) имеет место соотношение
\begin{equation}\label{2_5}
\sum_{k=0}^{N-1}\left(\sum_{m=0}^{N-1}h_m\cos\left(\frac{2\pi m (N-1)}{N}-\varphi\right)
\right)\sin\left(\frac{2\pi m k}{N}+\varphi\right)=0.
\end{equation}
Опять же, используя соотношение (\ref{2_3}), получим
\[
\sum_{k=0}^{N-1}\sin\left(\frac{2\pi n k}{N}+\varphi\right)=\frac{1}{\sin\left(\frac{2\pi n}{2N}\right)}
\sin\left(\frac{2\pi n (N-1)}{N}+\varphi\right)\sin\left(\frac{2\pi n N}{N}\right)=
\]
\[
\frac{1}{\sin\left(\frac{\pi n}{N}\right)}
\sin\left(-\frac{2\pi n }{N}+\varphi\right)\sin\left(\pi n \right)=
\left\{
\begin{array}{ll}
0, & \hbox{ }n\ne 0, \\
N\sin \varphi, & \hbox{ } n=0.
\end{array}
\right.
\]
Тогда соотношение (\ref{2_5}) можно записать в виде
\[
\sum_{m=0}^{N-1}h_m\cos\left(\frac{2\pi m (N-1)}{N}-\varphi\right)\sin\varphi=0,
\]
а так как \(\varphi\in\left(0,\frac{\pi}{2}\right)\), то \(\sin\varphi\ne 0\) и, очевидно, что
\[
\sum_{m=0}^{N-1}h_m\cos\left(\frac{2\pi m (N-1)}{N}-\varphi\right)=0,
\]
или, что то же
\[
\sum_{m=0}^{N-1}h_m\cos\left(\frac{2\pi m }{N}+\varphi\right)=
\sum_{m=0}^{N-1}h_m\left(\cos\frac{2\pi m }{N}\cos\varphi-\sin\frac{2\pi m }{N}\sin\varphi\right)=0.
\]
Отсюда получаем
\[
\sum_{m=0}^{N-1}h_m\left(\cos\frac{2\pi m }{N}-\sin\frac{2\pi m }{N}\textrm{tg}\varphi\right)=0.
\]
таким образом,
\[
\sum_{m=0}^{N-1}h_m\cos\frac{2\pi m }{N}=\textrm{tg}\varphi\sum_{m=0}^{N-1}h_m\sin\frac{2\pi m }{N}
\]
и
\[
\textrm{tg}\varphi=\frac{\sum_{m=0}^{N-1}h_m\cos\frac{2\pi m }{N}}{\sum_{m=0}^{N-1}h_m\sin\frac{2\pi m }{N}}.
\]
Наконец, получаем значение угла, при котором будут точно восстановлении все \(\{h_m\}_{m=0}^{N-1}\), при условии, что \(H_{N-1}=0\)
\[
\varphi=\textrm{arctg}\frac{\sum_{m=0}^{N-1}h_m\cos\frac{2\pi m }{N}}{\sum_{m=0}^{N-1}h_m\sin\frac{2\pi m }{N}}.
\]
Используем полученный результат для фильтрации периодических данных.
Пусть имеется псевдо-периодический сигнал с неизвестным периодом, необходимо найти период.
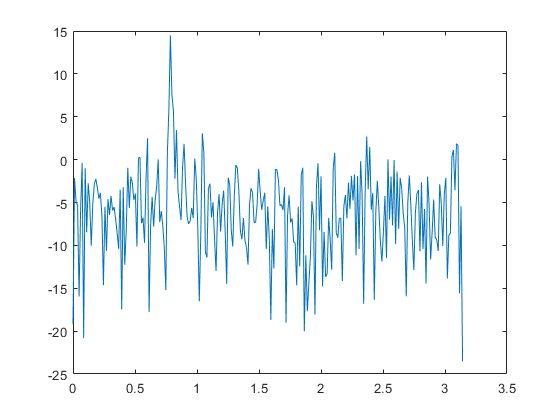
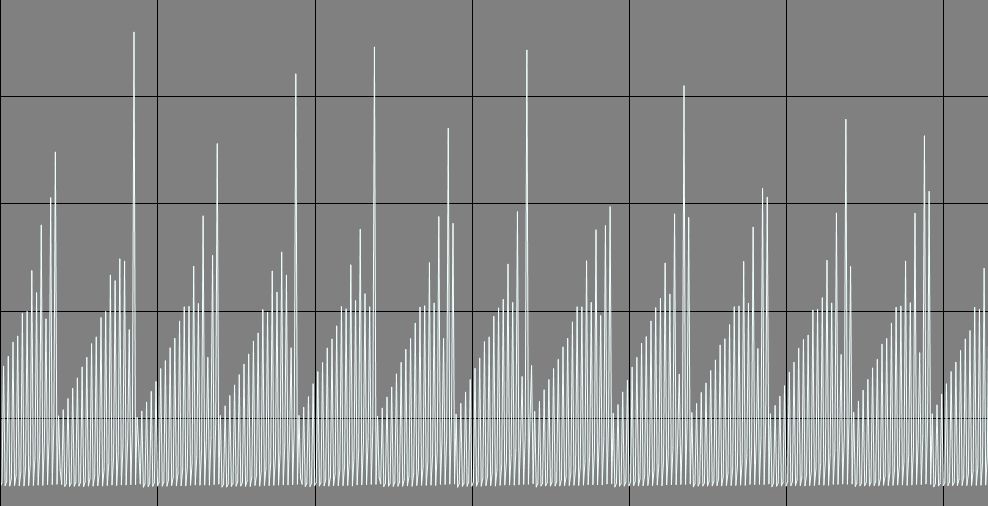
Спектрограмма разрыва почвенного пласта при оползне (г.Каменское) представляет собой временной ряд с почти-периодической составляющей.
Для множества данных \(y_t (t=0,1,...,T-1)\) выберем число \(N\ll T\), тогда пусть \(K=[T/N]\) (где [•] - целая часть числа).
Найдем множество углов \(\{\varphi_{i,N}\}_{i=0}^{K-1}\) таких, что
\[
\varphi_{i,N}=\textrm{arctg}\frac{\sum_{m=0}^{N-1}y_{m+iN}\cos\frac{2\pi m }{N}}{\sum_{m=0}^{N-1}y_{m+iN}\sin\frac{2\pi m }{N}} (i=0,1,...,K-1).
\]
Тогда \(\bar{\varphi}=\frac{1}{K}\sum_{i=0}^{K-1}\varphi_{i,N}\)- среднее значение множества углов \(\{\varphi_{i,N}\}_{i=0}^{K-1}\), а
\(\sigma^2_N=\frac{1}{K}\sum_{i=0}^{K-1}\left(\varphi_{i,N}-\bar{\varphi}\right)^2\)- значение дисперсии (мера отклонения значений случайной величины от центра распределения).
Таким образом, значение \(\bar{N}\), для которого выполняется соотношение \(\min_N\sigma^2_N=\sigma^2_{\bar{N}}\) будет отвечать наиболее вероятному
периода сигнала, значение которого будет соответствовать
\[
\frac{2}{\bar{N}\sin(2\bar{\varphi})}\sum_{k=0}^{\bar{N}-2}\sum_{m=0}^{\bar{N}-1}y_{m+i\bar{N}}\cos\left(\frac{2\pi m k}{\bar{N}}-
\bar{\varphi}\right)\sin\left(\frac{2\pi m k}{\bar{N}}+\bar{\varphi}\right) (i=0,1,...,\bar{K}-1),
\]
где \(\bar{K}=[T/\bar{N}]\).
Используя приведенные ранее данные по среднемесячной температуре в Киеве, найти прогноз на ноябрь и декабрь 2018 года. Выбрать наиболее адекватную модель предсказания.
Задача 2.
Отфильтровать периодические данные на приведенной выше спектрограмме разрыва почвенного пласта при оползне (г.Каменское).
Задача 3.
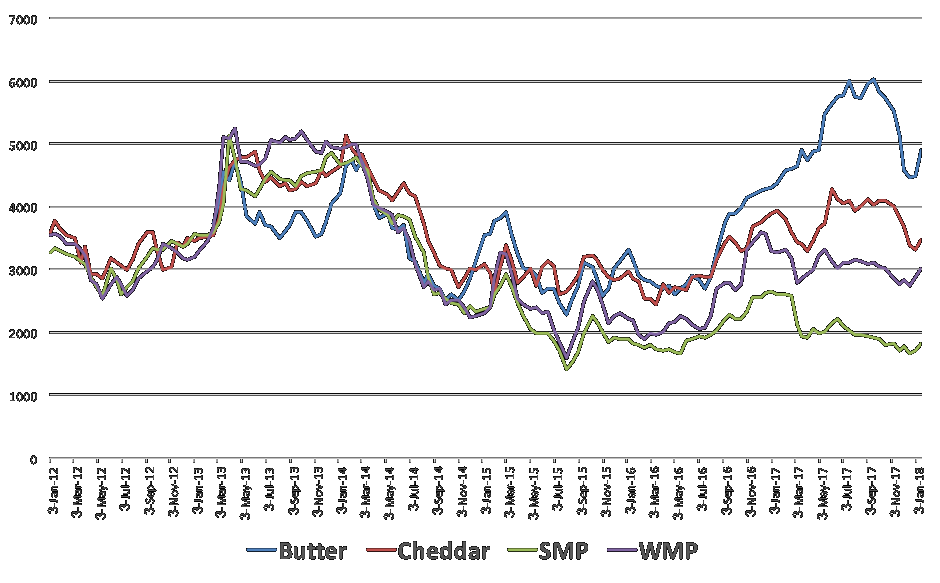
Динамика цен на основные биржевые товары молочного рынка, в долларах США за тонну. Здесь SMP - сухое обезжиренное молоко, WMP - цельное сухое молоко.
Проанализировать временной ряд и сделать прогноз на будущее.
Задача 4.
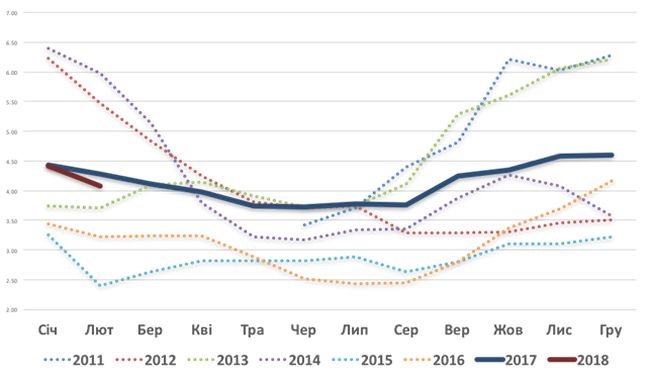
Динамика индекса условной доходности молока в Украине.
Проанализировать временной ряд и сделать прогноз на 2018 год.
Задача 5.
Динамика цен на топливо в Украине (данные в формате JSON).
Проанализировать временные ряды и сделать прогноз на 2019 год.