Cōgitō ergō sum - «я мыслю, следовательно, я существую». Это логическое утверждение Рене Декарта отражает сущность человеческой цивилизации в целом и нас, каждого в отдельности, именно логическое.
Мы используем логику, логические конструкции, чтобы пояснить собеседнику как мы видим те или иные вещи с нашей точки зрения.
Даже если мы не всегда действуем в соответствии с этим, логика естественна — по крайней мере, для людей.
Логика - одна из главных причин, почему люди так долго жили на планете, населенной множеством других существ, которые больше, быстрее, многочисленнее и свирепее и чем это всем им помогло?
Человечество всех их перемололо за время своего существования.
И поскольку логика является частью нашей жизни, она работает везде, куда бы мы ни посмотрели.
Логика дает инструменты для работы с тем, что уже известно (предпосылки), чтобы подвести к следующему шагу (выводу). Логика помогает обнаружить недостатки в аргументах — несостоятельность, скрытые
предположения или просто некорректное мышление.
Логика-одна из немногих дисциплин, изучаемых студентами двух разных специальностей: математика и философия, что обусловлено историческими предпосылками: логика была основана Аристотелем и развивалась
философами на протяжении веков. Но полтора века назад математики обнаружили, что логика является незаменимым инструментом для обоснования их деятельности.
Результатом деятельности математиков на поприще развития логики является формальная логика, которая берет идеи из философской логики и предельно формализуя их, применяет их в математических конструкциях.
Хотелось бы сказать, что мы живем в лучшем из миров, который полностью подчиняется логике. Жаль, но это не так. Для этого достаточно просто посмотреть телевизор, но недолго, так как это вредно для психического здоровья.
Мы живем в нелогичном мире.
Приведу пример из последнего похода на рынок.
Покупатель - взвесьте мне два килограмма яблок.
Продавец - а если будет больше?
Покупатель - ну, если немного.
"Немного" это сколько? Здесь что-то не так с логикой, и тем не менее, оба участника процесса купли-продажи друг друга замечательно поняли.
Давайте разберемся с логикой, как с формальной (четкой), так и с нечеткой (размытой, размазаной) логикой.
Замечание. Если встречается текст выделенный красным цветом, то далее рассматривается пример с данными, изменяемыми пользователем, то есть, щелкнув по данному полю курсором мыши,
можно ввести свои данные и посмотреть как в этом случае изменяется решение и результат (в том числе и графики).
Давайте попробуем мыслить логически.
Логика является важной составляющей познания. Нам это присуще с самого момента рождения. Появление ребенка с первых мгновений его жизни связано с познанием окружающего мира.
Мама, ее запах, ее голос, что может быть роднее? И ребенок сразу строит логическую схему: мама-еда-жизнь.
Большинство детей от природы любопытны, они "почемучки". Им интересно все, почему небо голубое, почему облака белые, а тучи темные, почему после молнии следует гром, почему, почему, почему...
Конструкция почему-потому, что... естественна для познания, по сути, это переход от незнания к пониманию, вот она главная причина возникновения логики!
Логика выросла из врожденной человеческой потребности осмыслить мир и, насколько это возможно, получить некоторый контроль над ним, а понимание причины и следствия является
одним из способов понять мир.
По мере взросления, мы начинаем ставить в соответствие то, что одно событие вызывает другое.
С формальной точки зрения связи между причиной и следствием могут быть описаны конструкцией если-то (if-else).
Например,
если лизнуть сахар, то во рту будет сладко,
если порезать пальчик, то из ранки пойдет кровь,
если чихнешь, то закроешь глаза
и т.д.
Вся прелесть логики в том, что конструкцию если-то можно усложнять, например, условие если может быть составным, например,
если идет дождь и температура воздуха ниже нуля, то на улице скользко.
или к условию если добавить антогонизм иначе если мы в северном полушарии, то можем увидеть полярную звезду, иначе - нет.
Взрослея, мы открываем новые конструкции - для всех (каждый), тогда найдется (существует), что делает возможность строить более сложные связи между причиной и следствием, классифицируя объекты
на множества, а те, в свою очередь на подмножества.
Можно пойти в спортивную секцию: тяжелая атлетика, легкая атлетика, шашки. Если записаться в секцию легкой атлетики, то можно выбрать бег,
ходьба, прыжки. Если выбрать бег, то спринт, бег на средние дистанции, марафон.
Со временем мы начинаем осознавать такие понятия как наложение множеств, называемое пересечением или их объединение, например,
все бегуны, которые пробегут марафон - марафонцы, а все, кто занимается бегом, спортивной ходьбой, метанием - легкоатлеты.
Заметим, что появляется понятие пустого моножества, например, среди всех членов нашей шахматной секции нет ни одного марафонца.
Когда говорят: "давайте будем логичными", по отношению к данной ситуации или проблеме, обычно имеют в виду следующее:
Есть некоторые предпосылки, то есть, факты, утверждения, которые вы знаете (или твердо верите) как истинные.
Наличие набора предпосылок является первым шагом к решению проблемы.
Иногда аргумент - это просто набор посылок, за которыми следует вывод.
Во многих случаях аргумент также включает промежуточные шаги, которые показывают как предпосылки постепенно приводят к этому выводу.
Следующим этапом является формирование заключения (вывод).
Вывод - это результат вашей аргументации. Если вы написали промежуточные шаги в четкой последовательности, вывод должен быть довольно очевидным.
Если вывод не очевиден или не имеет смысла, что-то может быть не так с вашей аргументацией. В некоторых случаях аргумент может быть неверным.
В других случаях у вас могут отсутствовать предпосылки, которые вам нужно будет добавить.
Решение о том, является ли аргумент действительным после того, как вы построили аргументацию, вы должны быть в состоянии решить, является ли он
действительным, то есть это хороший аргумент.
Чтобы проверить обоснованность аргумента, предположим, что все предпосылки истинны,а затем посмотрим, следует ли из них автоматически вывод. Если
вывод следует автоматически, вы знаете, что это верный аргумент. Если нет, то аргумент недействителен.
В качестве основы для понимания логики, математик и философ Бертран Рассел (1872-1970) установил три закона мышления. Все эти законы основаны на идеях, восходящих к
Аристотелю, основателю классической логики более 2300 лет назад.
Все три закона просты и понятны. Но самое главное, что эти законы позволяют делать логические выводы о высказываниях, даже если вы не знакомы с реальными обстоятельствами, которые они обсуждают.
Закон тождества
Закон тождества утверждает, что каждое отдельное утверждение тождественно само себе.
Например:
Бертран Рассел - это Бертран Рассел.
Земля - планета, на которой мы живем. Мы живем на планете Земля.
Закон тождества говорит, что любое утверждение вида “Х есть Х” должно быть истинным.
Закон исключенного среднего
Закон исключенного среднего утверждает, что каждое утверждение либо истинно, либо ложно. Третьего не дано.
Например, рассмотрим эти два утверждения:
Земля круглая.
Земля плоская.
Не имея никакой информации о мире, вы логически знаете, что каждое из этих утверждений либо истинно, либо ложно. По закону исключенного среднего
третий вариант невозможен — другими словами, утверждения не могут быть частично истинными или ложными.
В логике каждое утверждение либо полностью истинно, либо полностью ложно.
Закон непротиворечивости
Закон непротиворечивости гласит, что при наличии утверждения и его противоположности одно из них истинно, а другое ложно.
Например:
Земля плоская.
Земля не плоская.
Даже если мы ничего не знаем о форме Земли, исходя только из логики, мы уверены, что одно из этих утверждений истинно, а другое ложно. Другими словами, из
закона непротиворечивости Земля не может быть одновременно и плоской и неплоской.
Говоря о логике, нельзя обойтись без примеров, причем для этой цели отлично подходят примеры из математики.
Это связано, прежде всего, с тем, что примеры из окружающего нас мира могут быть субъективны или спорны.
Например,
Париж - столица Франции.
Париж - город, комфортный для жизни.
С первым утверждением не поспоришь, что правда, то правда. А вот со вторым, могут быть разнотолкования. Думаю, далеко не все согласятся с этим утверждением.
Теперь рассмотрим другой пример.
2+2=4.
3>4.
Очевидно, что нет никаких сомнений в том, что первое утверждение истинно, а второе ложно.
Законы Бертрана Рассела полностью основаны на черно-белом мышлении. Здесь нет полутонов. А что может быть более черно-белым чем математика?
Утверждение может быть доказано или нет. Теорема справедлива, если существует ее доказательство.
Математика построена на логике, как дом на фундаменте. Вся математика основана на том, что существует некоторый набор очевидных фактов, называемых аксиомами, а затем использует
логику для формирования интересных и сложных выводов, называемых теоремами.
Древние греки приложили руку к открытию почти всего естественнонаучного, и логика не является исключением. Например, Фалес и Пифагор применяли логические аргументы к математике.
Сократ и Платон применяли сходные типы рассуждения к философским вопросам. Но истинным основателем классической логики был Аристотель.
До Аристотеля (384-322 до н. э.) логические аргументы применялись интуитивно там, где это было уместно, в математике и философии.
Аристотель был первым, кто признал, что сам инструмент может быть исследован и разработан. В шести трудах по логике, позже собранных в
единую работу под названием "Органон", что означает "инструмент", он проанализировал, как функционирует логика как инструмент познания.
Аристотель надеялся, что логика, согласно его новой формулировке, послужит инструментом мышления, который поможет философам лучше понять мир.
Аристотель считал целью философии научное познание, и рассматривал структуру научного знания как логическую.
Аристотель ввел понятие силлогизма. В силлогизме посылки и выводы согласуются друг с другом таким
образом, что, приняв посылки как истинные, вы должны принять и то, что
заключение также истинно — независимо от содержания фактического аргумента
Вот, например, самый известный силлогизм Аристотеля:
Предпосылки:
Все люди смертны.
Сократ-это человек.
Вывод:
Сократ смертен.
Следующий аргумент аналогичен по форме первому. И именно форма
аргумента, а не содержание, делает его неоспоримым. Как только вы принимаете
предпосылки как истинные, вывод следует как столь же истинный.
Евклид (ок. 325-265 до н. э.) не был строго логиком, но его вклад в логику был неоспорим.
Евклид наиболее известен своими работами в области геометрии, которая до сих пор в его честь называется евклидовой
геометрией. Его величайшим достижением здесь была логическая
организация геометрических принципов в аксиомы и теоремы.
Евклид начал с пяти аксиом (также называемых постулатами) - истинных утверждений, которые
он считал их простыми и самоочевидными. Исходя из этих аксиом, он использовал логику для
доказательства теорем — истинных утверждений, которые были более сложными и не
сразу очевидными. Таким образом, ему удалось доказать обширную геометрию, логически вытекающую только из пяти аксиом. Математики до сих пор используют эту
логическую организацию высказываний в аксиомы и теоремы.
После греков логика отправилась в очень долгий отпуск, почти в кому.
Во всей Римской Империи и средневековой Европе на протяжении более тысячи лет логикой часто пренебрегали.
Готфрид Лейбниц (1646-1716) был величайшим логиком эпохи Возрождения.
Подобно Аристотелю, Лейбниц видел в логике потенциал стать незаменимым инструментом познания мира. Он был первым логиком, который взял
работы Аристотеля и значительно продвинулся вперед, превратив логические утверждения в символы, которыми затем можно было манипулировать, как числами и уравнениями.
Результатом стала первая попытка построения символической логики.
Лейбниц надеялся, что логика превратит философию, политику и
даже религию в чистый расчет, предоставив надежный метод объективного ответа на все
тайны жизни. В известной цитате из "искусства открытий" (1685) он говорит:
Единственный способ исправить наши рассуждения - сделать их такими же осязаемыми, как
рассуждения математиков, чтобы мы могли с первого взгляда обнаружить нашу ошибку,
а когда между людьми возникают споры, мы можем просто сказать:
"Давайте без лишних слов посчитаем, кто прав.”
К сожалению, его мечта о преобразовании всех сфер жизни в расчет
не была осуществлена поколением, которое последовало за ним. Его идеи настолько опередили
свое время, что не были признаны важными. После его смерти,
труды Лейбница о логике как символическом вычислении пылились почти 200 лет. К тому времени, когда они были вновь открыты, логики уже
догнали эти идеи и превзошли их.
К концу 19-го века математики разработали формальную логику -также называемую символической логикой, в которой символы обозначают понятия и утверждения.
Три ключевых участника формальной логики:
Джордж Буль, Георг Кантор и Готлоб Фреге.
Булева алгебра
Названная в честь своего изобретателя Джорджа Буля (1815-1864), булева алгебра является первой полностью развитой системой, которая обрабатывает логику как вычисление.
По этой причине именно Джордж Буль считается основоположником формальной логики.
Булева алгебра похожа на стандартную арифметику в том, что она использует как числовые значения, так и знакомые операции сложения и умножения.
В отличие от арифметики, используются только два числа: 0 и 1, которые означают ложь и истину соответственно.
Например:
Пусть A = самый длинный день 21 июня.
Пусть B = Самая короткая ночь 22 декабря.
Поскольку первое утверждение истинно, а второе ложно, то используя формализм булевой алгебры, можно сказать
\[
A = 1, B = 0.
\]
В булевой алгебре сложение интерпретируется как ИЛИ, поэтому утверждение
"Самый длинный день 21 июня ИЛИ Самая короткая ночь 22 декабря" можно записать в виде
\[
A + B = 1 + 0 = 1.
\]
Поскольку булево уравнение имеет значение 1, утверждение истинно. Аналогично,
умножение интерпретируется как И, поэтому утверждение
"Самый длинный день 21 июня И Самая короткая ночь 22 декабря" можно записать в виде
\[
A × B = 1 × 0 = 0.
\]
В этом случае булево уравнение принимает значение 0, поэтому утверждение ложно.
Как видите, вычисление значений удивительно похоже на арифметику.
Но смысл этих чисел-чистая логика.
Теория множеств Кантора
Теория множеств, впервые созданная Георгом Кантором в 1870-х годах, была еще одним предзнаменованием формальной логики, но с гораздо более широким влиянием, чем булева
алгебра.
В широком смысле множество-это просто набор вещей, которые могут иметь или не иметь что-то общее.
С точки зрения Кантора «множество — это большое количество элементов, которое позволяет воспринимать себя как одно».
Вот несколько примеров:
{1, 2, 3, 4, 5, 6}
{Лондон, Париж, Киев}
{Дуб, Кирпич, Облако, Окунь}.
Одно из фундаментальных преимуществ теории множеств произрастает не из какой-то конкретной теории, а из созданного ею языка.
\(B\subset A\) - подмножество (subset) — B является подмножеством A, множество B включено во множество A;
\[B=\{ карп, лещ\}\subset A.\]
\(B\subseteq A\) - собственное (истинное) подмножество — B является подмножеством A, но B не равно A.
Заметим, что A является подмножеством самого себя, но не является собственным (истинным) подмножеством.
Пусть \(A\subset U\), где \(U\) универсум (универсальное множество), то есть множество, включающее все множества, участвующие в рассматриваемой задаче.
Отрицанием множества А называется множество \(\bar{A}\), элементов U, которые не входят в А:
\[\bar{A}=\{x\in U:x\notin A\}\]
Несмотря на свою кажущуюся простоту — или, скорее, благодаря ей — теория множеств стала основой логики и, в конечном счете, самой формальной математики.
Формальная логика Фреге
Готтлоб Фреге (1848-1925) изобрел первую реальную систему формальной логики.
Система, которую он изобрел, на самом деле является одной логической системой, встроенной в другую.
Меньшая система, сентенциальная логика, также известная как пропозициональная логика, использует буквы для обозначения простых утверждений, которые затем связываются вместе с помощью
символов для пяти ключевых понятий: НЕ, И, ИЛИ, ЕСЛИ, и ИСКЛЮЧАЮЩЕЕ ИЛИ.
Фреге видел возможность того, что сама математика может быть выведена из логики и теории множеств. Начав с нескольких аксиом о множествах, он показал, что числа и, в конечном счете, вся математика логически вытекают из этих аксиом.
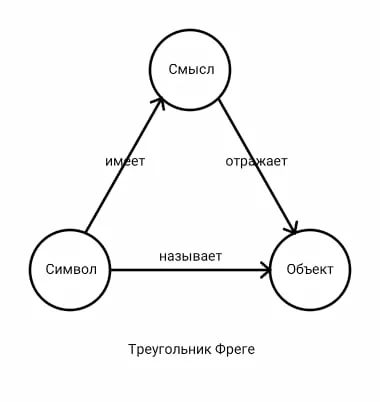
Фреге ввел различие между смыслом (нем. Sinn) и значением (нем. Bedeutung) понятия, обозначаемого определенным именем (так называемый треугольник Фреге или семантический треугольник: знак (символ)—смысл—значение(объект)).
Под значением в рамках его системы представлений понималась предметная область, соотнесенная с неким именем.
Под смыслом подразумевается определенный аспект рассмотрения этой предметной области.
Это диаграмма составных частей знака — главного объекта изучения семиотики. Знак состоит из трёх компонентов:
Объект — то, что составляет саму сущность знака, некоторый предмет или явление объективной действительности. Например, пусть это будет водоплавающая птица, которая ходит, переваливаясь.
Символ — то, что называет наш объект. В рассматриваемом примере это слово «утка», произнесённое или написанное — это пока неважно. Символ называет объект и имеет смысл.
Смысл — то, что мы понимаем под символом, весь комплекс нейронов и их ассоциаций, которые возбуждаются тогда, когда мы либо видим объект, либо наблюдаем символ, который называет объект.
Смысл отражает объект внутри нашей головы, в составе нашей символьной системы.
Проект сведения математики и логики к короткому списку аксиом открывает интересный вопрос: Что произойдет, если начнем с другого набора аксиом?
Одна из возможностей, например, состоит в том, чтобы позволить утверждению быть чем-то иным, чем истинным или ложным. Другими словами, можно позволить высказыванию нарушить закон исключенного среднего.
В 1917 году Ян Лукасевич (1978-1956) стал пионером первой многозначной логики, в которой утверждение может быть не только истинным или ложным, но и возможным.
Эта система была
бы полезна для классификации такого утверждения, как это:
В 2100 году "и на Марсе будут яблоки рости".
Введение категории возможного в пантеон истинного и ложного было первым радикальным отходом от классической логики в новую область, называемую неклассической логикой.
Однако логику ждали и другие сюрпризы.
С математикой, определенной в терминах набора аксиом, возник вопрос о том, является
ли эта новая система одновременно последовательной и полной. То есть можно ли было с помощью логики вывести из этих аксиом все истинные утверждения о математике, а не ложные?
В 1931 году Курт Гедель показал, что бесконечное число математических утверждений истинно, но не может быть доказано с учетом аксиом. Он также
показал, что любая попытка свести математику к непротиворечивой системе аксиом
приводит к одному и тому же результату: бесконечному числу математических истин, называемых
неразрешимые утверждения, которые не доказуемы в рамках этой системы.
Этот результат, названный теоремой неполноты, установил Геделя как одного из величайших математиков 20-го века.
В некотором смысле теорема Геделя о неполноте дала ответ на
надежду Лейбница на то, что логика когда-нибудь даст метод для вычисления ответов на
все загадки жизни. Ответом, к сожалению, было категорическое "нет!”
Многозначная логика
Правило исключенного среднего, то есть, утверждение либо истинно, либо ложно, без промежуточного, является важным допущением логики, и на протяжении тысячелетий оно хорошо служило логике.
Однако не все в мире так хорошо сочетается. Да и не должно.
Все в мире относительно. Во время Карибского кризиса на Кубу приехала делегация советской молодежи, среди которых был мой старый товарищ Николай. Все происходило зимой. По приезду вся группа высыпала на
берег океана и тут же запрыгнула в воду. Температура воды была 22-23С. Для нашего народа вода почти как компот, а аборигены на все это смотрели с ужасом - это не холодно, а ХОЛОДНО!
А попробовали бы они у нас на крещение прыгнуть в полынью!
Вот и имеем недопонимание - вода холодная это ложь или правда?
Классическая логика черно-белая, и не справляется с оттенками серого, так вода с температурой 23С относительно кубинца холодная, а относительно эскимоса, почти как в бане.
Закон исключенного среднего был краеугольным камнем логики от Аристотеля до 20-го века. Но в 1917 году польский математик Ян Лукасевич начал задаваться вопросом, что произойдет,
если добавить третье значение, не являющееся ни истинным, ни ложным. Он назвал это значение возможным и заявил, что оно может быть присвоено утверждениям, истинность которых неубедительна, таким как
прогноз погоды или гадание на кофейной гуще о том, кто победит на следующих выборах.
Возможное, существует где-то между истинным и ложным. По этой причине,
Лукасевич начал с логического представления 1 для истинного и 0 для ложного и добавил третье значение, 1⁄2, для возможного значения.
В результате получилась трехзначная логика. Трехзначная логика использует те же операторы, что и классическая логика, но с новыми определениями для покрытия нового значения. Например, вот таблица
истинности для отрицания \(\overline{x}\):
x
\(\overline{x}\)
1
0
1⁄2
1⁄2
0
1
Тепрь легко создать логическую систему с более чем одним промежуточным значением — фактически, с любым числом, которое вы выберете.
Например, система с 11 значениями от 0 до 1 с приращениями 1/10 между ними выглядит следующим образом
0
1/10
2/10
3/10
4/10
5/10
6/10
7/10
8/10
9/10
1
Эта система является примером многозначной логики.
Правила многозначной логики достаточно просты:
\(\overline{x}\)- правило (логическое ОТРИЦАНИЕ): означает 1-x.
\(x \& y\)- правило (логическое И): означает выбор меньшего значения.
\( x \vee y\)-правило (логическое ИЛИ): означает выбор большего значения,
Эти три правила могут показаться странными,но они работают.
Например:
Многозначная логика неоднозначная и вообще с ней все неоднозначно.
Сомнения многозначной логики в ее полезности для описания возможных будущих событий имеют под собой основания.
Для примера сравним многозначную логику и теорию вероятностей в качестве инструмента для прогноза.
Например, пусть вероятность морозной погоды на 31 декабря равна 25/31, а вероятность солнечной погоды в этот день равна 1/10.
Согласно теории вероятностей, то что на Новый Год будет солнечно и морозно, имеет вероятность 1/10 × 25/31 = 25/310, а многозначная логика дает значение 1/10,
то есть, по сути, если солнечно, то и морозно.
Однако в 1960-х годах математик Лотфи Заде увидел потенциал многозначной логики для представления не того, что возможно истинно, а того, что частично истинно.
Рассмотрим следующее утверждение:
Я голоден.
После того, как вы плотно поедите, это утверждение, скорее всего, будет ложным. Однако если вы не будете есть в течение нескольких часов, в конце концов это снова станет правдой.
Большинство людей, не воспринимает это изменение как черно-белое, а скорее как оттенки серого.
То есть они обнаруживают, что утверждение становится более истинным (или ложным) с течением времени.
Если мы посмотрим мир вокруг нас, то обнаружим, что большинство так называемых противоположностей-высокие или низкие, горячие или холодные, счастливые или грустные,
толстые или худые и так далее — не разделены резкой линией.
Вместо этого они являются концами отрезка, который соединяет тонкие оттенки. В большинстве случаев оттенки этих типов достаточно субъективны.
Ответ Л.Заде на эти вопросы - нечеткая логика, которая является продолжением и расширением многозначной логики.
Как и в случае многозначной логики, нечеткая логика допускает значения 0 для полностью ложных, значения 1 для полностью истинных и промежуточные значения для описания оттенков истины.
Но, в отличие от многозначной логики, разрешены все значения между 0 и 1.
Рассмотрим пример.
В замечательном фильме Леонида Гайдая присутствует такой тост:
Мой прадед говорит: имею желание купить дом, но не имею возможности. Имею возможность купить козу, но не имею желания.
Так выпьем за то, чтобы наши желания совпадали с нашими возможностями.
С точки зрения двузначной логики если финансовые возможности не совпадают с нашими желаниями, то проблема неразрешима. Но если подходить к решению с точки зрения нечеткой логики, то всегда можно найти компромис.
Не нужно думать, что нечеткая логика это придумка "яйцеголовых", которая интересна только с точки зрения заумных математических построений. Это не так.
Нечеткая логика в современном мире настолько распространена, что наверняка, у вас найдется несколько устройств, реализованых на принципах нечеткой логики, ну, например, свч-печь или стиральная машина автомат, котел или холодильник, робот-пылесос или посудомоечная машина.
Если эта техника производства Японии или Кореи, то наверняка это так.
В приведенной таблице приведены несколько примеров, которые показывают, как известные компании используют нечеткую логику в своих продуктах.
Сфера использования
Компания
Нечеткая логика
Антиблокировочная система тормозов
Nissan
Использование нечеткой логики для управления тормозами в опасных случаях зависит от скорости автомобиля, ускорения, скорости колеса и ускорения
Автоматическая коробка передач
NOK / Nissan
Нечеткая логика используется для управления впрыском топлива и зажиганием на основе настройки дроссельной заслонки, температуры охлаждающей воды, об / мин и т.д.
Авто двигатель
Honda, Nissan
Используется для выбора режима в зависимости от нагрузки двигателя, стиля вождения и дорожных условий.
Копировальная машина
Canon
Используется для регулировки напряжения барабана в зависимости от плотности изображения, влажности и температуры.
Круиз-контроль
Nissan, Isuzu, Mitsubishi
Используется для настройки дроссельной заслонки, чтобы установить скорость и ускорение автомобиля
Посудомоечная машина
Matsushita
Использование для регулировки цикла очистки, стратегий полоскания и стирки зависит от количества посуды и количества пищи, подаваемой на посуду.
Управление лифтом
Fujitec, Mitsubishi Electric, Toshiba
Используется, чтобы сократить время ожидания в зависимости от пассажиропотока
Гольф диагностическая система
Маруман Гольф
Выбирает гольф-клуб, основываясь на умениях и телосложении гольфиста.
Фитнес управление
Omron
Нечеткие правила, используемые для проверки работоспособности своих сотрудников.
Контроль печи
Nippon Steel
Смеси цементные
Микроволновая печь
Mitsubishi Chemical
Устанавливает силу излучения и стратегию приготовления
Планшет
Hitachi, Sharp, Sanyo, Toshiba
Распознает рукописные символы
Плазменное травление
Mitsubishi Electric
Устанавливает время травления и режим работы
Степенью принадлежности к множеству \(\Omega\) будем называть функцию \(\mu_\Omega(\omega)\), равную 1, если элемент принадлежит множеству \(\Omega\) и нулю, если не принадлежит
\[
\mu_\Omega(\omega)=
\left\{
\begin{array}{ll}
1, & \hbox{ } \omega \in \Omega,\\
0, & \hbox{ } \omega \notin \Omega.
\end{array}
\right.
\]
Заметим, что связь между множеством \(\Omega\) и его функцией принадлежности \(\mu_\Omega\) в обе стороны (взаимно однозначная)
\begin{equation} \label{eq1}
\Omega=\{(\omega,\mu_\Omega(\omega))|\omega\in\Omega,\mu_\Omega(\omega)\in [0,1]\}.
\end{equation}
Лотфи Заде (1968) ввел следующие обозначения, связывающие нечеткое множество и его функцию принадлежности:
\begin{equation}\label{dfuzzy}
\Omega=\left\{\frac{\mu_\Omega(\omega_1)}{\omega_1}+\frac{\mu_\Omega(\omega_2)}{\omega_2}+...\right\}=\left\{\sum_i\frac{\mu_\Omega(\omega_i)}{\omega_i}\right\}
\end{equation}
для дискретного случая и
\begin{equation}\label{cfuzzy}
\Omega=\left\{\int\frac{\mu_\Omega(\omega)}{\omega}\right\}
\end{equation}
для непрерывного.
В обоих обозначениях горизонтальная черта не является частным, а скорее символ принадлежности, где числитель указывает на значение членства в наборе \(\Omega\).
В первом соотношении (\ref{dfuzzy}) символ суммирования не предназначен для алгебраического суммирования, а скорее обозначает совокупность или агрегацию каждого элемента,
следовательно, знаки «+» в первой записи не являются алгебраическим «сложением», а являются оператором агрегирования.
Во втором обозначении знак интеграла - это не алгебраический интеграл, а непрерывный теоретико-функциональный оператор агрегирования непрерывных переменных.
Приведем пример действий над нечеткими множествами в терминологии Л.Заде:
\[
A=\left\{\frac{1}{2}+\frac{0.5}{3}+\frac{0.3}{4}+\frac{0.2}{5}\right\},\\
B=\left\{\frac{0.5}{2}+\frac{0.7}{3}+\frac{0.2}{4}+\frac{0.4}{5}\right\}.
\]
Тогда
\[
\bar{A}=\left\{\frac{1}{1}+\frac{0}{2}+\frac{0.5}{3}+\frac{0.7}{4}+\frac{0.8}{5}\right\},\\
\bar{B}=\left\{\frac{1}{1}+\frac{0.5}{2}+\frac{0.3}{3}+\frac{0.8}{4}+\frac{0.6}{5}\right\},
\]
\[
A\cup B=\left\{\frac{1}{2}+\frac{0.7}{3}+\frac{0.3}{4}+\frac{0.4}{5}\right\},\\
A\cap B=\left\{\frac{0.5}{2}+\frac{0.5}{3}+\frac{0.2}{4}+\frac{0.2}{5}\right\},
\]
\[
A|B=A\cap \bar{B}=\left\{\frac{0.5}{2}+\frac{0.3}{3}+\frac{0.3}{4}+\frac{0.2}{5}\right\},\\
B|A=B\cap \bar{A}=\left\{\frac{0}{2}+\frac{0.5}{3}+\frac{0.2}{4}+\frac{0.4}{5}\right\}.
\]
Заметим, что так как символ "+" не несет нагрузки арифметической операции, то его можно заменить, например, на ",".
Нужно только определиться какую смысловую нагрузку несет "," не перечисление, а агрегацию.
Поэтому, чтобы не допускать разнотолкование, вместо символа "+" будет "," и вместо (\ref{dfuzzy}) будем использовать обозначение
\begin{equation}\label{dfuzzy1}
\Omega=\left\{\frac{\mu_\Omega(\omega_1)}{\omega_1},\frac{\mu_\Omega(\omega_2)}{\omega_2},...\right\}.
\end{equation}
Рассмотрим пример. С точки зрения Всемирной организации здравоохранения, рост людей можно описать следующим образом
Итак, известен средний рост людей по группам
Классификация
Рост (см.)
Мужчины
Женщины
Низкий
Карликовая
До 129.9
До 120.9
Очень малая
130-149.9
121-139.9
Малая
150-159.9
140-148.9
Средний
Ниже средней
160-163.9
149-152.9
Средняя
164-166.9
153-155.9
Выше средней
167-169.9
156-158.9
Высокий
Большая
170-179.9
159-167.9
Очень большая
180-199.9
168-186.9
Гигантская
От 200 и выше
От 187 и выше.
Понятно, что это разделения очень условно, и зависит не только от нации, но и от условий проживания, питания и пр., например, даже в рамках одной нации могут быть существенные отличия, так
в Северной Корее средний рост мужчин -166 см., женщин -157 см., а в Южной Корее, мужчины - 174 см., а женщины - 161 см.
Но будем отталкиваться от этих средних данных.
Мужчины (\(\mu_M\))
Женщины (\(\mu_W\))
На одном графике это будет выглядеть так:
Тогда применяя правила логики (&-правило и \(\vee\)- правило)
\[
\mu_A(\omega)\& \mu_B(\omega)=\mu_{A\cap B}(\omega)=\min\{\mu_A(\omega),\mu_B(\omega)\},
\]
\[
\mu_A(\omega)\vee\mu_B(\omega)=\mu_{A\cup B}(\omega)=\max\{\mu_A(\omega),\mu_B(\omega)\},
\]
получаем
\(\mu_M \& \mu_W\)
\(\mu_M \vee \mu_W\)
Понятно, что предложенное описание на основе четкой (классической) логики описывает принадлежность людей к той или иной группе достаточно грубо.
Применим для этой цели нечеткую логику.
Нечеткие множества были Лотфи Заде (1921–2017) в 1965 году.
В отличие от четких множеств, нечеткое множество допускает частичную принадлежность к набору, что определяется степенью принадлежности, обозначаемой µ,
которая может принимать любое значение от 0 (элемент вообще не принадлежит набору) до 1 (элемент принадлежит полностью в комплект).
Очевидно, что если мы удалим все значения принадлежности, кроме 0 и 1, нечеткое множество превратится в четкое множество.
Рассмотрим самый простой случай, когда частичная принадлежность определяется линейно.
Выделим в каждой гуппе (Низкий, Средний, Высокий) среднее значение
Классификация
Рост (см.)
Мужчины
Женщины
Низкий
135
130
Средний
165.5
154.5
Высокий
185.5
177.5
и соединим ломаной
Как и в многозначной логике,
& - операторы в нечеткой логике обрабатываются как меньшее из двух значений,
\[
\mu_A(\omega)\& \mu_B(\omega)=\mu_{A\cap B}(\omega)=\min\{\mu_A(\omega),\mu_B(\omega)\},
\]
а \(\vee\)-операторы обрабатываются как большее из двух значений
\[
\mu_A(\omega)\vee\mu_B(\omega)=\mu_{A\cup B}(\omega)=\max\{\mu_A(\omega),\mu_B(\omega)\}.
\]
\(\mu_M \& \mu_W\)
\(\mu_M \vee \mu_W\)
Понятно, что это не единственный подход к построению нечетких функций принадлежности.
Давайте получим более точное соответствие множеству людей со средним ростом.
Сделаем, например, так, все же люди, принадлежащие группе среднего роста, они уже точно имеют средний рост, а вот из соседних групп, люди имеющий малый рост принадлежат группе
от низких до средних, а имеющий большой рост - в группе от средних до высоких.
В этом случае имеем следующее
Соответственно,
\(\mu_M \& \mu_W\)
\(\mu_M \vee \mu_W\)
Теория нечеткой логики не является нечетко определенной теорией. Это строгая математическая теория, которая для того, чтобы иметь дело с неоднозначностями, использует количественные описания в точных методах.
Объект-это неопределенность, но метод не является неопределенным.
Таким образом, понятия нечеткой логики осуществляется строго научным способом.
Общепринятые теории основаны на принципе Декарта, объекты которого ограничены тем, что может быть объективно определено.
Неопределенное, таким образом, исключается из списка тем исследования.
Даже если она изучается, представление вынуждено быть либо 0, либо 1, даже если оно кажется несовместимым с нашими чувствами.
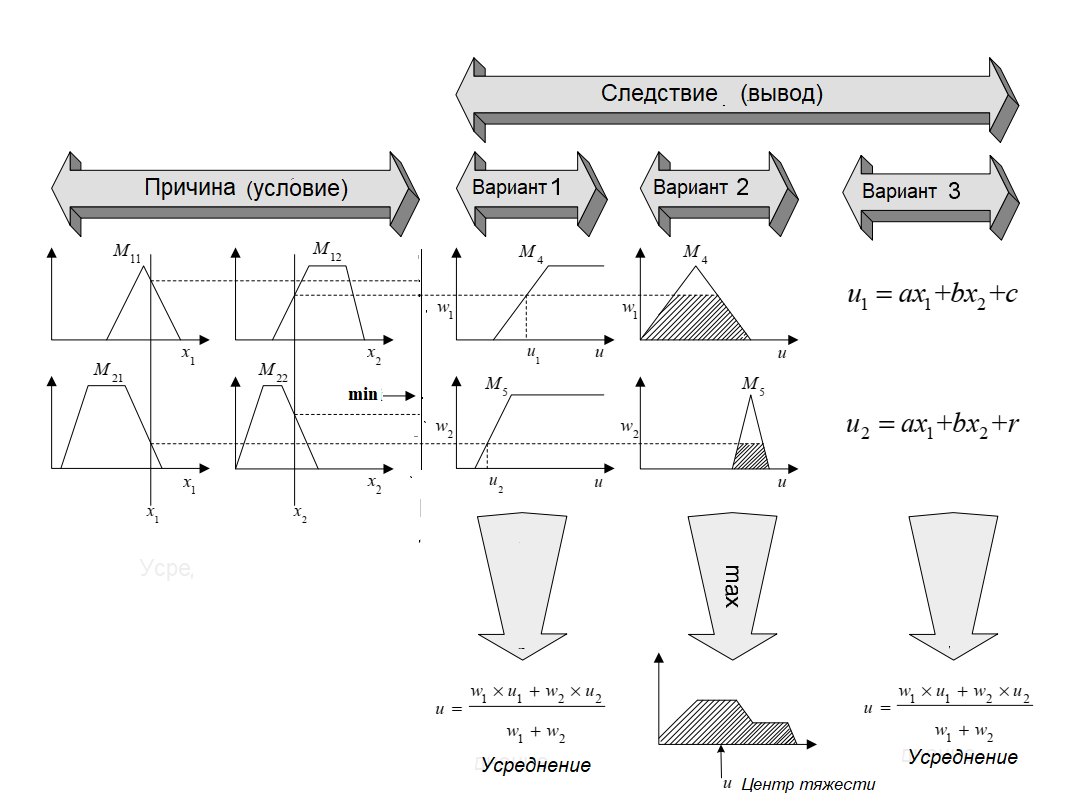
Поэтому, в нечетких методах используются понятия фаззификации и дефаззификации, то есть, перевод четких понятий в нечеткие и наоборот, из нечетких в четкие.
В конце концов, мы должны принять четкое решение: покупать- не покупать, включать - не включать, открыть - закрыть и пр.
Традиционно фаззификация состоит в переводе четкого понятия, которое представимо в виде единичной ступеньки в треугольную или трапецевидную форму, как это было сделано выше.
Процесс дефаззификации преобразует нечеткие контрольные значения в четкие величины, то есть связывает одну точку с нечетким множеством, учитывая, что эта точка из нечеткого множества.
Существует множество техник дефаззификации, наиболее известными из которых являются определение центра тяжести
\[
\hat{x}=\frac{\sum_i x_i\mu(x_i)}{\sum_i \mu(x_i)}
\]
или среднего из максимумов.
В теории нечетких вычислений операции с множествами проводятся через операции с их функциями принадлежности. Рассмотрим основные операции, без которых мы не сможем проводить никакие действия с нечеткими множествами.
Заметим, что все эти операции интуитивно понятные и нужны нам для четкого определения, чтобы не было разнотолкования. Кроме того, большая их часть была определена ранее, а сейчас давайте их соберем в кучу.
Следуя определению (\ref{eq1})
\[
A=\{(x,\mu_A(x)),\mu_A(x)\in [0,1]\},
\]
\[
B=\{(x,\mu_B(x)),\mu_B(x)\in [0,1]\}.
\]
Равенство. Нечеткие множества А и В из универсума U называются равными (А=В), если для всех \(x\in U\) выполняется равенство
\[\mu_A(x)=\mu_B(x).\]
Включение. Нечеткое множество A входит (включается, принадлежит) в нечеткое множество B, обозначаемое \(A \subseteq B\), если для
каждого \(x \in U\)
\[
µ_A (x) ≤ µ_B (x),
\]
в этом случае A называется подмножеством B.
Собственное подмножество.
Нечеткое множество A называется собственным подмножеством нечеткого множества B и обозначается
\(A \subset B\), если A является подмножеством B и \(A \neq B\), то есть
\[
µ_A (x) ≤ µ_B (x) \hbox{ }для \hbox{ }каждого\hbox{ } x \in U;\\
µ_A (x) \lt µ_B (x) \hbox{ }по\hbox{ } крайней \hbox{ }мере\hbox{ } для \hbox{ }одного\hbox{ } x \in U.
\]
Дополнения.
Нечеткие множества А и \(\bar{A}\) взаимно дополняют друг друга
\[
\mu_A(x)+\mu_{\bar{A}}(x)=1
\]
или, что то же,
\[
\mu_{\bar{A}}(x)=1-\mu_A(x);
\]
Функция принадлежности \(µ_\bar{A}(x)\) симметрична \(µ_A (x)\) относительно прямой µ = 0.5.
Пересечение.
Пересечение множеств A и B обозначается как \(А\cap B \) и определяется
\[
\mu_{A\cap B}(x)=\min\{\mu_A(x),\mu_B(x)|x\in\ U\}.
\]
Объединение.
Объединение множеств A и B обозначается как \(А\cup B \) и определяется
\[
\mu_{A\cup B}(x)=\max\{\mu_A(x),\mu_B(x)|x\in\ U\}.
\]
Приведем простой пример.
Пусть универсум состоит из пяти элементов \(U=\{x_1,x_2,x_3,x_4,x_5\}\). Эти элементами могут быть цены на те или иные товары, результаты анализов, температура воздуха в разное время и вообще,чем угодно, что может быть описано нечетким множеством.
Тогда
\[
\begin{array}{c|c|c|c|c|c}
x & x_1 & x_2 & x_3& x_4& x_5\\ \hline
\mu_A(x) & 0 & 0.3 & 0.5& 0.8& 1\\ \hline
\mu_\bar{A}(x) & 1 & 0.7 & 0.5& 0.2& 0\\ \hline
\mu_{A\cap \bar{A}}(x) & 0 & 0.3 & 0.5& 0.2& 0\\ \hline
\mu_{A\cup\bar{A}}(x) & 1 & 0.7 & 0.5& 0.8& 1\\ \hline
\end{array}
\]
Треугольные числа.
Согласен, на первый взгляд звучит дико. Что дальше - соленая радуга?
С другой стороны, мы уже чисто интуитивно рассматривали функцию принадлежности треугольной формы. В конце концов, треугольное число это просто термин, который отражает
частичную принадлежность и ничего большего.
Треугольное нечеткое число A или просто треугольное число с функцией принадлежности \(µ_A (x)\) определяется на R (на множестве действительных чисел) следующим образом
\begin{equation}\label{eq2}
\mu_A(x)=
\left\{
\begin{array}{ll}
\frac{x-x_1}{x_A-x_1}, & \hbox{ для } x_1\le x\le x_A,\\
\frac{x-x_2}{x_A-x_2}, & \hbox{ для } x_A\le x\le x_2,\\
0, & \hbox{ в противном случае.}
\end{array}
\right.
\end{equation}
где \([x_1; x_2]\) - опорный интервал, а точка \((x_A; 1) \)- вершина. Третья строка неинформативна, и при записи может быть отброшена.
Часто в приложениях точка \(x_A\in (x_1; x_2) \) находится в середине опорного интервала, т.е.
\[ x_A=\frac{x_1+x_2}{2} .\] Тогда подставляя это значение в (\ref{eq2}), получим
\begin{equation}\label{eq3}
\mu_A(x)=
\left\{
\begin{array}{ll}
2\frac{x-x_1}{x_2-x_1}, & \hbox{ для } x_1\le x\le \frac{x_1+x_2}{2},\\
2\frac{x-x_2}{x_1-x_2}, & \hbox{ для } \frac{x_1+x_2}{2}\le x\le x_2,\\
0, & \hbox{ в противном случае.}
\end{array}
\right.
\end{equation}
Треугольные нечеткие числа обозначаются посредством последовательного перечисления проекций вершин на ось переменных \(А=(x_1; x_A ; x_2)\).
Среди треугольных чисел есть два важных частных случая: это левое треугольное число \(A_l=(x_A ; x_A; x_2)\)
и правое треугольное число \(A_r=(x_1 ; x_A; x_A).\)
Трапециевидные нечеткие числа.
После того, как вы смирились с треугольными числами, трапециевидными числами уже не удивить.
\begin{equation}\label{eq4}
\mu_A(x)=
\left\{
\begin{array}{ll}
\frac{x-x_1}{a_1-x_1}, & \hbox{ для } x_1\le x\le a_1,\\
1, & \hbox{ для } a_1\le x\le a_2,\\
\frac{x-x_2}{a_2-x_2}, & \hbox{ для } a_2\le x\le x_2,\\
0, & \hbox{ в противном случае.}
\end{array}
\right.
\end{equation}
Графически получаем
Если \(a_1 = a_2 = x_A\), то трапециевидное число сводится к треугольному нечеткому числу и обозначается \((x_1; x_A ; x_A; x_2)\),
т.е. \((x_1; x_A; x_2)=(x_1; x_A ; x_A; x_2)\).
Также как и для треугольных чисел, существуют два важных частных случая - правые и левые трапециевидные числа.
Правое трапециевидное число, обозначаемое \( A_r = (a_1; a_1; a_2; x_2)\), имеет опорный интервал \([a_1; x_2]\)
а левое, обозначаемое \(A_l = (x_1; a_1; a_2; a_2)\), имеет опорный интервал \([x_1; a_2]\).
Арифметические операции с треугольными и трапециевидными числами
Сложение (вычитание) треугольных чисел
Суммирование и вычитание треугольных и трапециевидных чисел опирается на очевидные интервальные вычисления
\[
[a,b]+[c,d]=[a+c,b+d],\\
[a,b]-[c,d]=[a-d,b-c].
\]
Сумма двух треугольных чисел \(А_1=\left(x^{(1)}_1; x^{(1)}_A ; x^{(1)}_2\right)\) и \(А_2=\left(x^{(2)}_1; x^{(2)}_A ; x^{(2)}_2\right)\) также является треугольным числом
\[
A_1+A_2=\left(x^{(1)}_1; x^{(1)}_A ; x^{(1)}_2\right)+\left(x^{(2)}_1; x^{(2)}_A ; x^{(2)}_2\right)=\left(x^{(1)}_1+x^{(2)}_1; x^{(1)}_A+x^{(2)}_A ; x^{(1)}_2+x^{(2)}_2\right)
\]
и разность
\[
A_1-A_2=\left(x^{(1)}_1; x^{(1)}_A ; x^{(1)}_2\right)-\left(x^{(2)}_1; x^{(2)}_A ; x^{(2)}_2\right)=\left(x^{(1)}_1-x^{(2)}_2; x^{(1)}_A-x^{(2)}_A ; x^{(1)}_2-x^{(2)}_1\right).
\]
Пример.
Пусть
\[
A_1=(0,1,2), A_2=(-2,-1,2),
\]
тогда
\[
A_1+A_2=(0-2,1-1,2+2)=(-2,0,4).
\]
Произведение (деление) треугольных чисел на действительное число
Также, как и в случае суммирование, произведение произведение (деление) производится поэлементно
\[
Ar=rA=r(x_1;x_A;x_2)=(rx_1;rx_A;rx_2),\\
\frac{A}{r}=\frac{1}{r}\left(\frac{x_1}{r};\frac{x_A}{r};\frac{x_2}{r}\right).
\]
Пример.
Пусть
\[
A=(-1,1,2),
\]
тогда
\[
2A=(-2,2,4)
\]
и
\[
\frac{A}{2}=\left(-\frac{1}{2},\frac{1}{2},1\right).
\]
Нечеткое усреднение треугольных чисел.
Для множества треугольных чисел
\[А_i=\left(x^{(i)}_1; x^{(i)}_A ; x^{(i)}_2\right),i=1,2,...,n\]
легко выписать среднее арифметическое
\[
A_{среднее}=\frac{A_1+A_2+...+A_n}{n}=\frac{\left(x^{1)}_1; x^{(1)}_A ; x^{(1)}_2\right)+\left(x^{(2)}_1; x^{(2)}_A ; x^{(2)}_2\right)+...+\left(x^{(n)}_1; x^{(n)}_A ; x^{(n)}_2\right)}{n}=
\frac{\left(\sum_{i=1}^nx^{(i)}_1; \sum_{i=1}^nx^{(i)}_A ; \sum_{i=1}^nx^{(i)}_2\right)}{n}=
\left(\frac{1}{n}\sum_{i=1}^nx^{(i)}_1; \frac{1}{n}\sum_{i=1}^nx^{(i)}_A ; \frac{1}{n}\sum_{i=1}^nx^{(i)}_2\right).
\]
Пусть
\[
A_1=(0,1,2), A_2=(-2,-1,2),
\]
тогда
\[
\frac{A_1+A_2}{2}=(-1,0,2).
\]
Арифметические действия с трапециевидными числами.
Исходя из рассмотренных действий над треугольными числами, не нужно проявлять чудеса математической мысли, чтобы выписать аналогичные действия над трапециевидными числами,
а также, учитывая, что треугольные числа представляют собой частный случай треугольных чисел, соответствующие операции между треугольными т трапециевидными числами.
Сумма двух трапециевидных чисел \(А_1=\left(x^{(1)}_1; a^{(1)}_1; a^{(1)}_2; x^{(1)}_2\right)\) и \(А_2=\left(x^{(2)}_1; a^{(2)}_1; a^{(2)}_2 ; x^{(2)}_2\right)\) является трапециевидным числом
\[
A_1+A_2=\left(x^{(1)}_1; a^{(1)}_1; a^{(1)}_2; x^{(1)}_2\right)+\left(x^{(2)}_1; a^{(2)}_1; a^{(2)}_2 ; x^{(2)}_2\right)=\left(x^{(1)}_1+x^{(2)}_1; a^{(1)}_1+a^{(2)}_1; a^{(1)}_2+a^{(2)}_2; x^{(1)}_2+x^{(2)}_2\right).
\]
а разность
\[
A_1-A_2=\left(x^{(1)}_1; a^{(1)}_1; a^{(1)}_2; x^{(1)}_2\right)-\left(x^{(2)}_1; a^{(2)}_1; a^{(2)}_2 ; x^{(2)}_2\right)=
\left(x^{(1)}_1-x^{(2)}_2; a^{(1)}_1-a^{(2)}_2; a^{(1)}_2-a^{(2)}_1; x^{(1)}_2-x^{(2)}_1\right).
\]
Пример.
Пусть
\[
A_1=(0,0.5,1,2), A_2=(-2,-1,0,2),
\]
тогда
\[
A_1+A_2=(0-2,0.5-1,1+0,2+2)=(-2,-0.5,1,4).
\]
и
\[
A_1-A_2=(0-2,0.5-0,1+1,2+2)=(-2,0.5,2,4).
\]
Соответственно сумма треугольного \(А_1=\left(x^{(1)}_1; x^{(1)}_A; x^{(1)}_2\right)=\left(x^{(1)}_1; x^{(1)}_A; x^{(1)}_A; x^{(1)}_2\right)\) и трапециевидного \(А_2=\left(x^{(2)}_1; a^{(2)}_1; a^{(2)}_2 ; x^{(2)}_2\right)\) чисел, также является трапециевидным числом
\[
A_1+A_2=\left(x^{(1)}_1; x^{(1)}_A; x^{(1)}_A; x^{(1)}_2\right)+\left(x^{(2)}_1; a^{(2)}_1; a^{(2)}_2 ; x^{(2)}_2\right)=
\left(x^{(1)}_1+x^{(2)}_1; x^{(1)}_A+a^{(2)}_1; x^{(1)}_A+a^{(2)}_2; x^{(1)}_2+x^{(2)}_2\right).
\]
Пример.
Пусть
\[
A_1=(0,1,2)=(0,1,1,2), A_2=(-2,-1,-0.5,2),
\]
тогда
\[
A_1+A_2=(0-2,1-1,1-0.5,2+2)=(-2,0,0.5,4).
\]
Для множества трапециевидных чисел
\[А_i=\left(x^{(i)}_1; a^{(i)}_1; a^{(i)}_2; x^{(i)}_2\right),i=1,2,...,n\]
легко выписать среднее арифметическое
\[
A_{среднее}=
\left(\frac{1}{n}\sum_{i=1}^nx^{(i)}_1; \frac{1}{n}\sum_{i=1}^na^{(i)}_1; \frac{1}{n}\sum_{i=1}^na^{(i)}_2; \frac{1}{n}\sum_{i=1}^nx^{(i)}_2\right).
\]
Пример.
Пусть
\[
A_1=(0,1,2,4), A_2=(-2,-1,-0.5,2),
\]
тогда
\[
\frac{A_1+A_2}{2}=(-1,0,1.25,3).
\]
Теперь, когда вы окончательно смирились с различными геометрическими представлениями числа, нужно поговорить и об обратном процессе.
Кстати, заметим, что треугольное и трапецевидное представление числа не являются единственными, число можно представить в виде функции Гаусса
\[
f(x)=ae^{-\frac{(x-b)^2}{2c^2}}
\]
В-сплайна или любой унимодальной (с одним экстремумом) функции.
Фаззификация - преобразование некоторого четкого множества в нечеткое.
Например, четкое множество людей низкого, среднего и высокого роста выглядит так
Мужчины
Женщины
Можно провести фаззификацию таким образом
Мужчины
Женщины
или так
Мужчины
Женщины
или каким-то другим образом, все зависит от того насколько точно мы хотим решить задачу. Самая простая фаззификация - сведение к треугольным числам, в этом случае решение проще но и менее точное.
Во многих задачах более естественно вместо термина "степень принадлежности" использовать термин "надежность", кроме того, так как понятие нечеткого множества и его функции принадлежности полностью описывают друг друга, то эти два понятия можно отождествлять.
Если \(U=\{u_1,u_2,...,u_n\}\) дискретное универсальное множество, состоящее из конечного количества элементов, то нечеткое множество \(A\) можно записать в виде
\[
\hat{A}=\sum_{i=1}^n\frac{\mu_{\hat{A}}(u_i)}{u_i},
\]
для непрерывного множества \(U\) имеем
\[
\hat{A}=\int_U\frac{\mu_{\hat{A}}(u)}{u}du.
\]
Как четкое множество можно перевести в нечеткое разными методами, так и обратную операцию можно провести различным образом.
Дефаззификацией называется процедура преобразования нечеткого множества в четкое, по сути дела, в число.
Дефаззификация по методу центра тяжести.
Для непрерывного универсума используем соотношение
\[
\hat{u}=\frac{\int_U{u\mu_{\hat{A}}(u)du}}{\int_U{\mu_{\hat{A}}(u)du}}=\frac{\int_{\underline{u}}^{\overline{u}}{u\mu_{\hat{A}}(u)du}}{\int_{\underline{u}}^{\overline{u}}{\mu_{\hat{A}}(u)du}},
\]
где
\[\overline{u}=\max\{u|u\in U,\mu(u)>0\},\underline{u}=\min\{u|u\in U,\mu(u)>0\},\]
для дискретного случае имеем
\[
\hat{u}=\frac{\sum_{i=1}^nu_i\mu_{\hat{A}}(u_i)}{\sum_{i=1}^n\mu_{\hat{A}}(u_i)}.
\]
Дефаззификация нечеткого множества по методу медианы
для непрерывного случая состоит в нахождении числа \(\hat{u}\) такого, что
\[
\int_{\underline{u}}^{\hat{u}}\mu_{\hat{A}}(u)du=\int_{\hat{u}}^{\overline{u}}\mu_{\hat{A}}(u)du
\]
то есть такого вертикального разреза, который делит исходную фигуру на две с одинаковой площадью,
для дискретного случая имеем
\[
\hat{u}=\min_{1\le j\le n}\left\{\sum_{i=j}^n\mu_{\hat{A}}(u_i)\left|\sum_{i=j}^n\mu_{\hat{A}}(u_i)\ge \frac{1}{2}\sum_{i=1}^n\mu_{\hat{A}}(u_i)\right.\right\}.
\]
Приведем простой пример. Пусть имеем средний доход (USD), определяемый треугольным числом (u1,u2,u3)=
(500,
1200,
2500
)
Тогда
Вначале проведем дефаззификацию методом центра тяжести.
Вычислим интеграл
\[
\int_{u1}^{u3} u\mu(u)du=\int_{u1}^{u2} u\mu(u)du+\int_{u2}^{u3} u\mu(u)du=\int_{u1}^{u2} u\frac{u-u1}{u2-u1}du+\int_{u2}^{u3} u\frac{u-u3}{u2-u3}du=
\frac{1}{u2-u1}\left.\left(\frac{u^3}{3}-u1\frac{u^2}{2}\right)\right|_{u1}^{u2}+
\frac{1}{u2-u3}\left.\left(\frac{u^3}{3}-u3\frac{u^2}{2}\right)\right|_{u2}^{u3},
\]
который в этом случае равен и интеграл
\[
\int_{u1}^{u3} \mu(u)du=\int_{u1}^{u2} \mu(u)du+\int_{u2}^{u3} \mu(u)du=\int_{u1}^{u2} \frac{u-u1}{u2-u1}du+\int_{u2}^{u3} \frac{u-u3}{u2-u3}du=
\frac{1}{u2-u1}\left.\left(\frac{u^2}{2}-u1*u\right)\right|_{u1}^{u2}+
\frac{1}{u2-u3}\left.\left(\frac{u^2}{2}-u3*u\right)\right|_{u2}^{u3},
\]
который равен и поделив первое на второе, получаем дефаззифицированное значение \(\hat{u}=\).
Теперь проведем дефаззификацию методом медианы, то есть найдем такое значение \(\hat{u}\), что
\[
\int_{u1}^{\hat{u}}\mu(u)du=\int_{\hat{u}}^{u2}\mu(u)du.
\]
В нашем случае \(\hat{u}=\).
Рассмотрим дискретный случай, для чего проведем дискретизацию исходных данных для n=10:
\(\mu_i=\)
Проведем дефаззификацию для метода центра тяжести
\(\sum_{i=0}^nu_i\mu_i=\)
и
\(\sum_{i=0}^n\mu_i=\)
поделив первое на второе, получем \(\hat{u}=\).
Проиллюстрируем для дискретного случая дефаззификацию по методу медианы:
j
\(\sum_{i=0}^j\mu_i\)
\(\sum_{i=j}^n\mu_i\)
\(u_j\)
Последнее значение \(u_j\) и будет искомым значением \(\hat{u}\).
Рассмотрим еще один пример (отсюда).
Компания имеет три автозаправочные станции, одна из которых находится в черте города, вторая на окраине и третья на объездной дороге.
Первая АЗС, благодаря своему удачному месторасположению, обеспечивает достаточно стабильные ежедневные продажи в пределах от
100 тыс.грн. до
120 тыс.грн.
АЗС на окраине города приносит не более 40 тыс.грн.
Продажи автозаправки на объездной дороге существенно зависит от времени года, от дня недели и погоды и продажи лежат в пределах от
20 тыс.грн.
до 140 тыс.грн.
Причем, с наиболее ожидаемый объем продаж лежит в пределах от
80 тыс.грн.
до
110 тыс.грн.
При этом расходы компании лежат в пределах от
60 тыс.грн.
до
110 тыс.грн.
с наиболее ожидаемым значением
80 тыс.грн.
Найдем чистый доход компании.
Продажи, представимые в виде трапециевидных чисел будут иметь вид
а расходы \(B=\left(x^{(B)}_1,a^{(B)}_1,a^{(B)}_2,x^{(B)}_2\right)\)=(),
Суммарный объем продаж будет равным \(A=A_1+A_2+A_3=\left(x^{(A)}_1,a^{(A)}_1,a^{(A)}_2,x^{(A)}_2\right)\)=():
Для нахождения чистого дохода найдем разность между суммарным объемом продаж и расходами компании
Отсюда получаем, что чистый доход компании лежит от до , с наиболее ожидаемой уверенностью от до .
Для вычисления ожидаемого дохода проведем дефаззификацию методом центра тяжести и получим значение .
Размер стартовых инвестиций известен точно и составляет I = 1 млн.грн.
Ставка дисконтирования в плановый период может колебаться в пределах от RDmin = 10%
до RDmax = 30% годовых
Чистый денежный поток планируется в диапазоне от CFmin = 0
до CFmax = 2 млн. грн.
Остаточная (ликвидационная) стоимость проекта равна G= 0.
Чистая современная ценность инвестиций (NPV) характеризует эффективность текущих операций и рассчитывается в модели как отношение чистой прибыли к выручке от реализации:
\[
NPV=\sum_{i=0}^{Life+1}\frac{NVF_i}{(1+RD)^i},
\]
где NCFi - чистый эффективный денежный поток на i-ом интервале планирования, RD - ставка дисконтирования (в десятичном выражении), Life - горизонт исследования,
выраженный в интервалах планирования.
В рассматриваемом случае (интервал планирование равен 2 года) чистая современная ценность проекта может быть оценена по формулам:
\[
NPV_\min=-I+\frac{CF_\min}{1+RD_\max/100}+\frac{CF_\min}{(1+RD_\max/100)^2},
\]
и NPVmin=
\[
NPV_\max=-I+\frac{CF_\max}{1+RD_\min/100}+\frac{CF_\max}{(1+RD_\min/100)^2},
\]
и NPVmax=
\[
NPV_{avg}=-I+\frac{CF_{avg}}{1+RD_{avg}/100}+\frac{CF_{avg}}{(1+RD_{avg}/100)^2},
\]
и ожидаемый случай NPVavg=.
Здесь CFavg = (CFmax -CFmin )/2 = млн. грн., RDavg = (RDmax - RDmin)/2 = % годовых.
Под эффективными инвестициями понимаем такое множество состояний инвестиционного процесса, когда реальная чистая современная ценность проекта больше заданного инвесторами критерия G.
Функцию принадлежности NPV инвестиционного проекта можно свести к треугольному числу NPV=( , , )
То есть для \(\alpha\in [0,1]\)
\[
NPV=\left\{
\begin{array}{ll}
NPV_1=\alpha(NVP_{avg}-NPV_\min)+NPV_\min, \\
NPV_2=-\alpha(NPV_\max-NVP_{avg})+NPV_\max.
\end{array}
\right.
\]
Значение α>α1 для которого выполняется неравенство NPV>G, дает уверенность в том, что проект эффективен, поэтому степень риска инвестиционного проекта нулевая.
Уровень α1 назывется верхней границей зоны риска.
Поскольку все реализации (NPV,G) при заданном уровне принадлежности α равновозможны, то степень риска неэффективности проекта \(\varphi(α)\) есть геометрическая вероятность события
попадания точки (NPV,G) в зону неэффективных инвестиций
\[
\varphi(\alpha)=\left\{
\begin{array}{ll}
0, & \hbox{ } G\le NPV_1 \\
\frac{G-NPV_1}{NPV_2-NPV_1}, & \hbox{ }NPV_1\lt G\lt NPV_2, \\
1, & \hbox{ }NPV_2\le G.
\end{array}
\right.
\]
Тогда итоговое значение степени риска неэффективности проекта равно
\[
V\& M=\int_0^{\alpha_1}\varphi(\alpha)d\alpha=
\left\{
\begin{array}{ll}
0, & \hbox{ } G\lt NPV_\min,\\
R\left(1+\frac{1-\alpha}{\alpha}\ln(1-\alpha)\right), & \hbox{ }NPV_\min\le G\lt N_{avg}, \\
1-(1-R)\left(1+\frac{1-\alpha}{\alpha}\ln(1-\alpha)\right), & \hbox{ }NPV_{avg}\le G\lt N_{\max}, \\
1, & \hbox{ }NPV_\max\le G.
\end{array}
\right.
\]
где
\[
R=\left\{
\begin{array}{ll}
\frac{G-NPV_\min}{NPV_\max-NPV_\min}, & \hbox{ } G\lt NPV_\max, \\
1, & \hbox{ }NPV_\max\le G.
\end{array}
\right.
\]
и верхняя граница зоны риска равна
\[
\alpha_1=\left\{
\begin{array}{ll}
0, & \hbox{ }G\lt NPV_\min.\\
\frac{G-NPV_\min}{NPV_{avg}-NPV_\min}, & \hbox{ } NPV_\min\le G\lt NPV_{avg}, \\
\frac{NPV_\max-G}{NPV_\max-NPV_{avg}}, & \hbox{ } NPV_{avg}\le G\lt NPV_{\max}, \\
0, & \hbox{ }NPV_\max\le G.
\end{array}
\right.
\]
Для исходных данных \(\alpha_1=\)
и степень риска V&M= (%).
Если для принятия решения будем использовать следующую градацию
V&M
Степень риска
Решение компании относительно инвестирования
0 – 0,07
Очень низкая
Точно принять проект
0,07 – 0,15
низкая
Принять, но с осторожностью и последующим мониторингом
0,16 – 0,35
средняя
Принять с ограничениями
0,36 – 0,4
высокая
Отклонить и пересмотреть проект
> 0,40
Очень высокая
Отказаться с уверенностью
то для исходных данных рекомендуемое значение будет: .
Что сказать, название навевает добрачные взаимоотношения. Но это только терминология.
Вначале рассмотрим достаточно простое понятие: отложим на осях \(OX, OY\) отрезки \(A=[0,1],B=[0,1]\) и проведем прямые \(x=1,y=1\). Не нужно быть гением от математики, чтобы в результате увидеть единичный квадрат.
Множество точек данного квадрата обозначается
\[
A\times B=\left\{(x,y)\left|x\in A,y\in B\right.\right\}.
\]
Ясно, что А и В совсем не обязательно должны быть единичными отрезками.
В общем случае, если A и B-подмножества универсальных множеств \(U_1\) и \(U_2\) соответственно, A × B называется декартовым произведением
Нечеткое отношение на A × B, обозначаемое \(\mathcal{R}\) или \(\mathcal{R}(x; y)\), определяется как множество
\[
\mathcal{R}=\left\{((x,y),\mu_{\mathcal{R}}(x,y))\left|(x,y)\in A\times B,\mu_{\mathcal{R}}(x,y)\in[0,1]\right.\right\}.
\]
где \(µ_{\mathcal{R}} (x; y)\) - функция принадлежности от двух переменных.
Эта функция устанавливает степень принадлежности упорядоченной пары \((x; y)\) из \(\mathcal{R}\), связывая с каждой парой \((x; y)\) из A × B действительное число из интервала [0, 1].
Формально нечеткое отношение \(\mathcal{R}\) является классическим тринарным отношением, это множество упорядоченных точек в трехмерном пространстве.
В непрерывном случае это поверхность.
Пример.
Пусть есть множество аптек \(A=\{a_1,a_2,a_3\}\) и множество аптечных складов \(S=\{s_1,s_2\}\). Пусть \(\mathcal{R}\) нечеткое отношение между этими двумя множествами, характеризующее
транспортные издержки на доставку медикаментов, от больших (1) до отсутствия таковых (0) - аптека при аптечном складе:
\[
\mathcal{R}=\{
((\hbox{склад }s_1,\hbox{ аптека }a_1),0.3),
((\hbox{склад }s_1,\hbox{ аптека }a_2),0.6),
((\hbox{склад }s_1,\hbox{ аптека }a_3),0.8),
((\hbox{склад }s_2,\hbox{ аптека }a_1),0.8),
((\hbox{склад }s_2,\hbox{ аптека }a_2),0.5),
((\hbox{склад }s_2,\hbox{ аптека }a_3),0).
\}
\]
Запишем это соотношение в виде таблицы
\[
\begin{array}{c|c|c|c}
& \hbox{ аптека }a_1 & \hbox{ аптека }a_2 & \hbox{ аптека }a_3\\ \hline
\hbox{склад }s_1 & 0.3 & 0.6 & 0.8\\ \hline
\hbox{склад }s_2 & 0.8 & 0.5 & 0\\ \hline
\end{array}
\]
Функция принадлежности показывает насколько велики транспортные издержки, так доставка медикаментов с первого склада в первую аптеку достаточно недорога, тогда как доставка со второго склада недешевая.
Основные операции над нечеткими отношениями
Пусть \(\mathcal{R}_1\) и \(\mathcal{R}_2\)-два нечетких отношения на A × B,
\[
\mathcal{R}_1 = \{ ((x, y), \mu_{\mathcal{R}_1} (x, y))\}, (x, y) \in A × B;\\
\mathcal{R}_2= \{((x,y), \mu_{\mathcal{R}_2}(x, y))\}, (x,y) \in A × B.
\]
Используем функции принадлежности \(µ_{\mathcal{R}_1}(x, y)\) и \(µ_{\mathcal{R}_2}(x, y)\) для введения операций с \(\mathcal{R}_1\) и \(\mathcal{R}_2\) аналогично операциям с нечеткими множествами, рассмотренными ранее.
Равенство
\(\mathcal{R}_1=\mathcal{R}_2\), тогда и только тогда, когда для каждой пары \((x, y) \in A × B\) выполняется равенство
\[
\mu_{\mathcal{R}_1} (x, y)=\mu_{\mathcal{R}_2} (x, y).
\]
Включение
Если для каждой пары \((x, y) \in A × B\)
\[
\mu_{\mathcal{R}_1} (x, y)\le \mu_{\mathcal{R}_2} (x, y).
\]
отношение \(\mathcal{R}_1\) включается в \(\mathcal{R}_2\) или \(\mathcal{R}_2\) больше, чем \(\mathcal{R}_1\), обозначается \(\mathcal{R}_1 \subseteq \mathcal{R}_2\).
Если \(\mathcal{R}_1 \subseteq \mathcal{R}_2\) и кроме того, если по меньшей мере существует хоть одна пара \((х, у)\),
\[
\mu_{\mathcal{R}_1} (x, y)\lt \mu_{\mathcal{R}_2} (x, y),
\]
тогда имеем строгое включение \(\mathcal{R}_1 \subset \mathcal{R}_2\).
Дополнения
Дополнение отношения \(\mathcal{R}\), обозначаемого \(\bar{\mathcal{R}}\), определяется равенством
\[
\mu_{\bar{\mathcal{R}}} (x, y)=1- \mu_{\mathcal{R}} (x, y),
\]
для любой пары \((x, y) \in A × B\).
Пересечение
Пересечение \(\mathcal{R}_1\) и \(\mathcal{R}_2\) обозначаемое \(\mathcal{R}_1\cap \mathcal{R}_2\) определяется следующим образом
\[
\mu_{\mathcal{R}_1\cap \mathcal{R}_2}(x,y)=\min\left\{\mu_{\mathcal{R}_1}(x,y),\mu_{\mathcal{R}_2}(x,y)\right\}, (x, y) \in A × B.
\]
Объединение
Объединение \(\mathcal{R}_1\) и \(\mathcal{R}_2\) обозначаемое \(\mathcal{R}_1\cup \mathcal{R}_2\) определяется следующим образом
\[
\mu_{\mathcal{R}_1\cup \mathcal{R}_2}(x,y)=\max\left\{\mu_{\mathcal{R}_1}(x,y),\mu_{\mathcal{R}_2}(x,y)\right\}, (x, y) \in A × B.
\]
Пусть \(\mathcal{R}_1 - \) нечеткое отношение \(\mathcal{R}_1: X\times Y \to [0,1] \) между \(X\) и \(Y\), \(\mathcal{R}_2 - \) нечеткое отношение \(\mathcal{R}_2: Y\times Z \to [0,1] \) между \(Y\) и \(Z\).
Нечеткое отношение между X и Z, обозначаемое \(\mathcal{R_1}\circ\mathcal{R_2}\) и определяемое соотношением
\[
\mu_{\mathcal{R_1}\circ\mathcal{R_2}}(x,z)=\bigvee_y\{\mu_{\mathcal{R_1}}(x,y)\& \mu_{\mathcal{R_2}}(y,z)\},
\]
называется min-max композицией или сверткой отношений \(\mathcal{R_1},\mathcal{R_2}\).
Рассмотрим пример вычисления композиции нечетких отношений.
Пусть
\(\mathcal{R_1}\)
y1
y2
y3
x1
0.1
0.7
0.4
x2
1
0.5
0
и
\(\mathcal{R_2}\)
z1
z2
z3
z4
y1
0.9
0
1
0.2
y2
0.3
0.6
0
0.9
y3
0.1
1
0
0.5
Тогда
\(\mathcal{R_1}\circ\mathcal{R_2}\)
z1
z2
z3
z4
Здесь
\[
\mu_{\mathcal{R_1}\circ\mathcal{R_2}}(x_i,z_j)= (\mu_{\mathcal{R_1}}(x_i,y_1) \& \mu_{\mathcal{R_2}}(y_1,z_j))\vee
(\mu_{\mathcal{R_1}}(x_i,y_2) \& \mu_{\mathcal{R_2}}(y_2,z_j))\vee
(\mu_{\mathcal{R_1}}(x_i,y_3) \& \mu_{\mathcal{R_2}}(y_3,z_j)),i=1,2;j=1,2,3,4.
\]
или, что то же
\[
\mu_{\mathcal{R_1}\circ\mathcal{R_2}}(x_i,z_j)= \max\{\min(\mu_{\mathcal{R_1}}(x_i,y_1), \mu_{\mathcal{R_2}}(y_1,z_j)),
\min(\mu_{\mathcal{R_1}}(x_i,y_2), \mu_{\mathcal{R_2}}(y_2,z_j)),
\min(\mu_{\mathcal{R_1}}(x_i,y_3), \mu_{\mathcal{R_2}}(y_3,z_j))\},i=1,2;j=1,2,3,4.
\]
Знание эксперта \(А → В\) (если А то В) отражает нечеткое причинное отношение предпосылки и заключения, поэтому его можно назвать нечетким отношением и обозначить через \(\mathcal{R}\):
\[
\mathcal{R}= А → В,
\]
где «→» называют нечеткой импликацией.
Отношение \(\mathcal{R}\) можно рассматривать как нечеткое подмножество прямого произведения \(Х×У\) полного множества предпосылок \(X\) и заключений \(Y\).
Таким образом, процесс получения (нечеткого) результата вывода В' с использованием данного наблюдения А' и знания А → В можно представить в виде правила
\[
В' = А' ᵒ \mathcal{R}= А' ᵒ (А → В),
\]
где «о» — операция композиции (свертки).
Традиционно нечеткие выводы представляют собой восходящие выводы от предпосылок к заключению.
Но могут применяться и нисходящие выводы.
Пусть задано полное пространство предпосылок \(X=\{x_1,...,x_m\}\) и полное пространство заключений \(Y=\{y_1,...,y_n\}\).
Между \(x_i\) и \(y_j\) существуют нечеткие причинные отношения \(x_i\to y_j\), которые можно представить в виде матрицы \(\mathcal{R}\) с элементами \(r_{i,j}\in [0,1], i=1,...,m,j=1,...,n.\)
Предпосылки и заключения можно рассматиривать как нечеткие множества A и B на пространствах X и Y, отношения которых можно представить в виде композиции нечетких выводов \(B=A\circ \mathcal{R}\).
В данном случае направление выводов является обратным для правил, то есть, задана матрица \(\mathcal{R}\) (знания эксперта), наблюдаются выходы В (заключения) и определяются входы А (предпосылки).
Принять на роботу специалиста, умеющего выполнять требуемые функции.
Передать решение проблемы на аутсорсинг, заключив договор со сторонней организацией на выполнение задания.
Руководитель принимает решение исходя из критериев:
Насколько быстро будет выполнена работа.
Насколько дорого обойдется выполнение этой работы.
Насколько качественно будет выполнена работа.
Будем считать, что все критерии одинаковы по важности. Каждый критерий порождает отношение предпочтения на множестве альтернатив (возможностей).
Обозначим альтернативы \(x_1,x_2,x_3\). Тогда отношения предпочтения будут:
\(\cal{R}_1 - \) x1 одинаковы по предпочтению с x2,
а x3 предпочтительнее, чем x2 по критерию 1. (Насколько быстро будет выполнена работа.)
\(\cal{R}_2 - \) x1 предпочтительнее чем x2 и x3,
а x2 предпочтительнее, чем x3 по критерию 2. (Насколько дорого обойдется выполнение этой работы.)
\(\cal{R}_3 - \) x1 одинаковы по предпочтению с x2,
а x3 предпочтительнее, чем x1 по критерию 3. (Насколько качественно будет выполнена работа.)
По этим данным составляются матрицы отношений \(\cal{R}_1,\cal{R}_2,\cal{R}_3\):
\[
r^k_{i,j}=\left\{
\begin{array}{ll}
1, & \hbox{ если i-я альтернатива лучше j-й по критерию k или альтернативы одинаковы по предпочтению;}\\
0, & \hbox{ если i-я альтернатива хуже j-й по критерию k.}
\end{array}
\right.
\]
В результате получаем матрицу \(\mu_1\):
1
1
0
1
1
0
1
1
1
матрицу \(\mu_2\):
1
1
1
0
1
1
0
0
1
и матрицу \(\mu_3\):
1
1
0
1
1
0
1
1
1
А теперь решаем задачу в соответствии с описанным алгоритмом.
Строим нечеткое отношение \(Q=\cal{R}_1\cap\cal{R}_2\cap\cal{R}_3\)
\[
\mu_Q(x_i,x_j)=\min\{\mu_1(x_i,x_j),\mu_2(x_i,x_j),\mu_3(x_i,x_j)\}=
\]
1
1
0
0
1
0
0
0
1
Находим подмножество недоминируемых альтернатив на множестве \(\{X,\mu_Q\}\)
\[
\mu_Q(x_i)=1-\max_{x_j\in X}\left\{\mu_Q(x_j,x_i)-\mu_Q(x_i,x_j)\right\}
\]
по всем \(i\) и \(j (i\ne j)\):
Строим отношение \(W\):
\[
\mu_W(x_i,x_j)=\sum_{j=1}^m\omega_j\mu_j(x_i,x_j), \sum_{j=1}^m\omega_j=1.
\]
Если важность критериев равна \(\omega_1=\)0.3333
(насколько быстро будет выполнена работа),
\(\omega_2=\)0.3333
(насколько дорого обойдется выполнение этой работы),
\(\omega_3=\)0.3333 (насколько качественно будет выполнена работа), то
\(\mu_W(x_1,x_1)=\) 1/3(1+1+1)=1;
\(\mu_W(x_1,x_2)=\) 1/3(1+1+1)=1;
\(\mu_W(x_1,x_3)=\)1/3(0+1+0)=1/3;
\(\mu_W(x_2,x_1)=\) 1/3(1+0+1)=2/3;
\(\mu_W(x_2,x_2)=\) 1/3(1+1+1)=1;
\(\mu_W(x_2,x_3)=\) 1/3(0+1+0)=1/3;
\(\mu_W(x_3,x_1)=\) 1/3(0+0+1)=1/3;
\(\mu_W(x_3,x_2)=\) 1/3(1+0+0)=1/3;
\(\mu_W(x_3,x_3)=\) 1/3(1+1+1)=1.
Матрица \(\mu_W\) равна
1
1
1/3
2/3
1
1/3
1/3
1/3
1
Далее находим подмножество недоминируемых альтернатив множества \(\{X,\mu_W\}\)
\[
\mu_W(x_i)=1-\max_{x_j\in X}\left\{\mu_W(x_j,x_i)-\mu_W(x_i,x_j)\right\}
\]
по всем \(i\) и \(j (i\ne j)\):
Отсюда получаем, что рациональным необходимо считать выбор альтернативы, имеющих максимальную степень недоминируемости:
Прямое произведение.
Рассмотрим нечеткие множества A и B
\[
A=\{(x,\mu_A(x)),\mu_A(x)\in [0,1]\},\\
B=\{(y,\mu_B(y)),\mu_B(y)\in [0,1]\},
\]
определеные для \(x \in A \subset U_1\) и \(y \in B \subset U_2\).
Прямое минимальное произведение нечетких множеств A и B, определяется соотношением
\[
A\stackrel{\min}{\times}B=\{(x,y),\min(\mu_A(x),\mu_B(y)),(x,y)\in A\times B\},
\]
это означает, что к декартовому произведению A × B нужно присоединить в качестве значения принадлежности меньшее из \(µ_A(x)\) и \(µ_B (y)\).
Прямое максимальное произведение нечетких множеств A и B, определяется соотношением
\[
A\stackrel{\max}{\times}B=\{(x,y),\max(\mu_A(x),\mu_B(y)),(x,y)\in A\times B\},
\]
то есть, к декартовому произведению A × B нужно присоединить в качестве значения принадлежности большее из \(µ_A(x)\) и \(µ_B (y)\).
Следующий пример взят отсюда.
В городе N-ске отвод паводковых вод осуществляется путем направления паводкового водосброса в систему прудов, которые накапливают наземный сток от ливней и сбрасывают воду вниз по течению с
контролируемой скоростью, чтобы уменьшить или исключить наводнения в районах ниже.
Пусть A относительная наполняемость системы прудов на основе наблюдений за последние годы (предположим, что наполняемость четырех прудов равна p1, p2, p3 и p4,
и все вместе они образуют один сток в магистральный коллектор).
Пусть B общее количество осадков, основанное на значениях наблюдений за тот же срок, полученных с трех разных метереологических станций, g1, g2 и g3.
Пусть есть следующие конкретные нечеткие множества
\[
A=\left\{\frac{0.2}{p_1},\frac{0.6}{p_2},\frac{0.5}{p_3},\frac{0.9}{p_4}\right\},\\
B=\left\{\frac{0.4}{g_1},\frac{0.7}{g_2},\frac{0.8}{g_3}\right\}.
\]
Выпишем прямое минимальное произведение этих двух нечетких множеств:
\[
C=A\stackrel{\min}{\times}B=
\begin{array}{c|ccc}
& g_1 & g_2 & g_3 \\
\hline
p_1 & 0.2 & 0.2 & 0.2 \\
p_2 & 0.4 & 0.6 & 0.6 \\
p_3 & 0.4 & 0.5 & 0.5 \\
p_4 & 0.2 & 0.7 & 0.8 \\
\end{array}
\]
Смысл этого произведения состоит в том, чтобы связать предсказание метереологической станцией ливней с фактической наполняемостью водоема во время дождя.
Более высокие значения указывают на информацию о станции, которые могут эффективно моделировать наводнение и управлять ими.
Более низкие относительные значения могут указывать на проблему или нерепрезентативное расположение датчика метеостанции.
Определим насколько хорошо прогнозируют данные метеорологические станции ливни локализованные данной областью или большей областью.
Рассмотрим результаты для удаленной системы водоемов во время того же ливня.
Предположим, есть взаимосвязь между наполняемостью еще пяти прудов в новой системе прудов (p5, ..., p9) и данными об осадках из исходных датчиков
осадков (g1, g2 и g3). Это соотношение задается следующим образом
\[
D=
\begin{array}{c|ccc}
& g_1 & g_2 & g_3 \\
\hline
p_5 & 0.3 & 0.4 & 0.2 \\
p_6 & 0.6 & 0.7 & 0.6 \\
p_7 & 0.5 & 0.5 & 0.8 \\
p_8 & 0.2 & 0.3 & 0.9 \\
p_9 & 0.1 & 0.3 & 0.8 \\
\end{array}
\]
Пусть E является нечеткой max-min комбинацией этих двух систем
\[
E=
\begin{array}{c|ccc}
& p_1 & p_2 & p_3 & p_4 \\
\hline
p_5 & 0.2 & 0.4 & 0.4 & 0.4 \\
p_6 & 0.2 & 0.6 & 0.5 & 0.7 \\
p_7 & 0.2 & 0.6 & 0.5 & 0.8 \\
p_8 & 0.2 & 0.6 & 0.5 & 0.8 \\
p_9 & 0.1 & 0.6 & 0.5 & 0.8 \\
\end{array}
\]
где, например,
\[
\mu_E(p_2,p_7)=\max\{\min\{0.4,0.5\},\min\{0.6,0.5\},\min\{0.6,0.8\}\}=0.6.
\]
Если числа в этом соотношении большие, это означает, что прогноз ливня достаточно эффективен, если числа ближе к нулю, то прогноз более локализован и исходные датчики метеостанции не являются хорошим предсказателем для обеих систем.
Пусть имеется множество альтернатив
\[
A=\{a_1,a_2,...,a_m\}
\]
и набор критериев
\[
C=\{C_1,C_2,...,C_n\}.
\]
Тогда для каждого критерия \(C_j\) поставим в соответствие нечеткое множество (см. (\ref{dfuzzy1}))
\[
C_j=\left\{\frac{\mu_{C_j}(a_1)}{a_1},\frac{\mu_{C_j}(a_2)}{a_2},...,\frac{\mu_{C_j}(a_m)}{a_m}\right\},
\]
где \(\mu_{C_j}(a_i)\in [0,1]\) - оценка альтернативы \(a_i\) по критерию \(C_j\) характеризует степень соответствия альтернативы понятию, определяемому критерием \(C_j\).
Правило для выбора наилучшей альтернативы может быть записано в виде пересечения соответствующих нечетких множеств
\[
\cal{C}=C_1\bigcap C_2\bigcap ...\bigcap C_n,
\]
что соответствует нахождению минимума функций принадлежности
\[
\mu_\cal{C}(a_i)=\min_{j=1,2,...,n}\mu_{C_j}(a_i),i=1,2,...,m.
\]
В качестве лучшей выбирается альтернатива \(a^*\), имеющая наибольшее значение функции принадлежности
\[
\mu_\cal{C}(a^*)=\max_{i=1,2,...,m}\mu_{\cal{C}}(a_i).
\]
Примеры взяты отсюда.
Пример критериев равной важности.
Рассмотрим задачу выбора руководителя IT-фирмы. Претенденты оцениваются по следующим критериям:
\(C_1 - \) профессиональные навыки,
\(C_2 - \) организаторские способности,
\(C_3 - \) опыт руководящей работы,
\(C_4 - \) авторитет в коллективе,
\(C_5 - \) коммуникабельность,
\(C_6 - \) возраст.
Претенденты:
Черныгин И. - Head of Operation HR,
Смолич В. -Project Manager,
Диденко Д. - Software Product Manager,
Пивень П. - Бизнес-аналитик,
Мартыненко М. - Team Lead.
Оценка претендента по 10-балльной шкале.
№
Претендент (альтернативы)
\(C_1 - \) профессиональные навыки
\(C_2 - \) организаторские способности
\(C_3 - \) опыт руководящей работы
\(C_4 - \) авторитет в коллективе
\(C_5 - \) коммуникабельность
\(C_6 - \) возраст
1
Черныгин И.
6
5
9
7
8
2
2
Смолич В.
9
4
6
7
4
8
3
Диденко Д.
5
7
9
4
8
6
4
Пивень П.
7
8
3
9
6
5
5
Мартыненко М.
4
2
6
7
8
9
В результате получаем следующие множества
и правило выбора имеет вид
\(\cal{C}=\)
В результате получаем рейтинг альтернатив
Если критерии \(C_j\) имеют разную важность, то есть, неравноправны, то каждому из них приписывается число \(\alpha_j\ge 0\), значение которого больше для более важного критерия,
и правило выбора принимает вид
\[
\cal{C}=C_1^{\alpha_1}\bigcap C_2^{\alpha_2}\bigcap ...\bigcap C_n^{\alpha_n},
\]
при условии
\[
\alpha_j\ge 0, j=1,2,...,n; \frac{1}{n}\sum_{j=1}^n\alpha_i=1.
\]
Коэффициенты относительной важности определяются на основе процедуры парного сравнения критериев.На первом этапе формируется матрица \(\cal{B}\), элементы которой выбираются из условий
Шкала оценок важности.
Относительная важность критериев \(C_i\) и \(C_j\)
Элемент \(b_{i,j}\)
Равная важность
1
Немного важнее
3
Важнее
5
Заметно важнее
7
Намного важнее
9
Промежуточные значения
2,4,6,8
с естественными условиями \(b_{i,i}=1,b_{i,j}=\frac{1}{b_{j,i}}\). В первом случае важность критерия относительно самого себя равна единице, во втором, если некоторый критерий
важнее другого в некоторое количество раз, то второй в то же число слабее первого.
Далее находим собственный вектор \(w\) матрицы \(\cal{B}\), соответствующий наибольшему собственному числу \(\lambda_\max\):
\begin{equation}\label{1}
\cal{B}w=\lambda_\max w.
\end{equation}
Требуемые значения коэффициентов \(\alpha_j\) получаются перемножением элементов собственного вектора на размерность \(n\), при условии нормировки
\[\alpha_j=nw_j.\]
Заметим, что задача нахождения собственных чисел и векторов сводится к решению алгебраического уравнения степени, равной размерности матрицы \(\cal{B}\), то есть, если матрица
размерности 3×3 то это кубическое уравнение, если 100×100 то уравнение сотой степени. Ясно, что это само по себе задача нетривиальная, поэтому для нахожнения
собственного вектора, соответствующего наибольшему собственному числу будем использовать итерационный, приближенный метод - Rayleigh's Power Method, о чем будет сказано позже, при рассмотрении следующего примера.
Пример критериев различной важности.
Требуется выбрать место для строительства предприятия, исходя из следующих критериев:
\(C_1 - \) близость к потребителю продукции предприятия,
\(C_2 - \) близость к источникам сырья,
\(C_3 - \) наличие свободной квалифицированной рабочей силы.
Предполагаемые места строительства (альтернативы): \(a_1, a_2, a_3, a_4\).
Оценка альтрнатив по 10-балльной шкале.
№
Предполагаемые места строительства (альтернативы)
\(C_1 - \) близость к потребителю продукции предприятия
\(C_2 - \) близость к источникам сырья
\(C_3 - \) наличие свободной квалифицированной рабочей силы
1
\(a_1\)
5
5
2
2
\(a_2\)
7
4
1
3
\(a_3\)
3
8
6
4
\(a_4\)
6
4
9
В этом случае нечеткие множества, характеризующие альтернативные варианты при условии различных критериев, будут иметь вид:
Критерии имеют различную важность и характеризуются мнением экспертов, результаты их попарного сравнения представлены матрицей \(\cal{B}\)
\(C_1 \)
\(C_2 \)
\(C_3 \)
\(C_1\)
1
5
0.333333
\(C_2\)
1/5
1
0.111111
\(C_3\)
3
9
1
Проиллюстрируем нахождение наибольшего собственного числа и соответствующего собственного вектора итерационным, приближенным методом - Rayleigh's Power Method.
Пусть
\[
\cal{B}=\left(
\begin{array}{ccc}
1 & 5 & 1/3 \\
1/5 & 1 & 1/9 \\
3 & 9 & 1\\
\end{array}
\right)
\].
Выберем стартовое значение \(w^{(0)}\), к примеру, таким, чтобы все координаты были равными и выполнялось условие нормировки:
\[
\sum_{i=1}^nw_i=1,
\]
то есть,
\[
w^{(0)}=\left(\frac{1}{3},\frac{1}{3},\frac{1}{3}\right)^T.
\]
В соответствии с задачей (\ref{1}), проведем первую итерацию
\[
\cal{B}w^{(0)}=
\left(
\begin{array}{ccc}
1 & 5 & 1/3 \\
1/5 & 1 & 1/9 \\
3 & 9 & 1\\
\end{array}
\right)
\left(
\begin{array}{c}
1/3 \\
1/3 \\
1/3\\
\end{array}
\right)=
\left(
\begin{array}{c}
1/3(1+5+1/3) \\
1/3(1/5+1+1/9) \\
1/3(3+9+1)\\
\end{array}
\right)=
\left(
\begin{array}{c}
\frac{19}{9} \\
\frac{59}{135} \\
\frac{13}{3}\\
\end{array}
\right)=\left(\frac{19}{9} +\frac{59}{135}+ \frac{13}{3}\right)
\left(
\begin{array}{c}
\frac{285}{929} \\
\frac{59}{929} \\
\frac{285}{929}\\
\end{array}
\right)=\frac{929}{135}
\left(
\begin{array}{c}
\frac{285}{929} \\
\frac{59}{929} \\
\frac{285}{929}\\
\end{array}
\right)=\lambda^{(1)}w^{(1)};
\]
Теперь вторую
\[
\cal{B}w^{(1)}=
\left(
\begin{array}{ccc}
1 & 5 & 1/3 \\
1/5 & 1 & 1/9 \\
3 & 9 & 1\\
\end{array}
\right)
\left(
\begin{array}{c}
\frac{285}{929} \\
\frac{59}{929} \\
\frac{285}{929}\\
\end{array}
\right)=
\left(
\begin{array}{c}
1\cdot\frac{285}{929}+5\cdot \frac{59}{929}+\frac{1}{3}\cdot \frac{285}{929} \\
\frac{1}{5}\cdot\frac{285}{929}+1\cdot \frac{59}{929}+\frac{1}{9}\cdot \frac{285}{929} \\
3\cdot\frac{285}{929}+9\cdot \frac{59}{929}+1\cdot \frac{285}{929} \\
\end{array}
\right)=
\left(
\begin{array}{c}
\frac{675}{929} \\
\frac{443}{2787} \\
\frac{1671}{929}\\
\end{array}
\right)=\left(\frac{675}{929} +\frac{443}{2787} + \frac{1671}{929}\right)
\left(
\begin{array}{c}
\frac{2025}{7481} \\
\frac{443}{7481} \\
\frac{5013}{7481}\\
\end{array}
\right)=\frac{7481}{2787}
\left(
\begin{array}{c}
\frac{2025}{7481} \\
\frac{443}{7481} \\
\frac{5013}{7481}\\
\end{array}
\right)=\lambda^{(2)}w^{(2)};
\]
Продолжая этот процесс, либо заданное число раз, либо пока для заданного порога \(\varepsilon>0\) не выполнится условие \(|\lambda^{{k}}-\lambda^{(j)}|\lt \varepsilon \), приходим к
приближенным \(\lambda_\max\) и соответствующему собственному вектору \(w=(w_1,w_2,w_3)\).
Для данных нашего примера получаем
\(w_1=\)0.06, \(w_2=\)0.27,\(w_3=\)0.67.
Модифицируем множества \(C_j\) с учетом важности критериев
и правило выбора имеет вид
\(\cal{C}=\)
В результате получаем рейтинг альтернатив
Заметим, что \(\lambda_\max\ge n\) и значение \(\lambda_\max - n\) дает меру несогласованности и указывает когда суждения экспертов следует проверить, чем больше это значение,
тем больше несогласованность и тем больше требуется проверить экспертные оценки. Для данного примера \(\lambda_\max=\) и \(n=3\), мера несогласованности равна .
Нечеткая логика фокусируется на лингвистических переменных в естественном языке (чуть больше, слегка, приоткрыть, немного и пр.) и стремится обеспечить основу для приближенных
рассуждений с неточными предложениями, отражает как яркость, так и неопределенность естественного языка в рассуждениях здравого смысла.
Здесь переплетаются отношения между классическими множествами, классической логикой, нечеткими множествами (в частности, нечеткими числами), бесконечнозначной логикой и нечеткой логикой.
Основные части нечеткой логики касаются лингвистических переменных и лингвистических модификаторов, пропозициональной нечеткой логики, правил вывода и приближенных рассуждений.
В повседневной жизни мы оперируем нестрогими (нечеткими, размытыми) понятиями - вода в кране "ледяная", "очень холодная", "холодная", "бодрящая", "прохладная", "комфортная",
"теплая", "горячая", "обжигающая", или критерий риска банкротства предприятия - "очень низкий", "низкий", "средний", "высокий", "очень высокий".
Практически все явления вокруг нас мы оцениваем с субъективной точки зрения, то есть нечетко. Это и состояние погоды и цены в магазине и качество товара и прочее, прочее, прочее.
Несмотря на кажущуюся неопределенность, люди, в процессе общения хорошо понимают описание объектов и явлений на лингвистическом уровне, что позволяет воспринимать, анализировать информацию,
перерабатывать ее и делать на ее основе выводы.
Нечеткие методы позволяют формализовать процесс обработки информации, заданной в лингвистической форме. Для этой цели используются следующие понятия:
лингвистическая переменная,
лингвистический терм,
лингвистический оператор.
Заметим, что под лингвистической переменной понимается переменная, которая принимает значений фраз естественного языка.
Лингвистической переменной называется пятерка \(\{x,T(x),X,G,M\}\), где х - имя переменной, Т(х) - множество имен лингвистических значений переменной х,
каждое из которых является нечеткой переменной на множестве Х, G - синтаксическое правило для образования имен значений х, М - семантическое правило для ассоциирования
каждой величины значения с ее понятием.
В качестве примера рассмотрим лингвистическую переменную, описывающую рост взрослого человека, тогда: х- "рост", Х - множество чисел из интервала [67,272]
(по официальным данным самый низкий человек - Хагендра Тапа Магар имел рост 67 см., а самый высокий - Роберт Першинг Уодлоу был ростом в 272 см.), Т(х) - значения
"низкий", "средний", "высокий", G - "очень", "не очень". Такие лингвистические усилители могут образовывать новые понятия: "очень высокий", "не очень низкий".
М - правило, определяющее вид функции принадлежности для каждого значения из множества Т.
«Очень» - операция концентрации, которая сужает множество вниз и, таким образом, уменьшает степень принадлежности нечетких элементов.
Операция “очень” может быть задана как квадрат функции принадлежности
\[
\mu_A^{очень}(x)=\left(\mu_A(x)\right)^2,
\]
например, если степень принадлежности степени риска банкротства предприятия к множеству «высокого» равно 0.8, то для «очень высокого» степень принадлежности равно 0.64.
«Чрезвычайно» служит той же цели, но делает это в большей степени, что может быть выполнено путем возведения \(\mu_A(x)\) в третью степень:
\[
\mu_A^{чрезвычайно}(x)=\left(\mu_A(x)\right)^3.
\]
Для предыдущего примера риск банкротства будет «чрезвычайно высоким» со степенью принадлежности 0.512.
«Очень очень» просто расширение концентрации.
\[
\mu_A^{очень-очень}(x)=\left(\mu_A^{очень}(x)\right)^2=\left(\mu_A(x)\right)^4.
\]
"Относительно" или «более или менее» - операция расширения, в результате расширяется набор и, следовательно, увеличивает степень принадлежности нечетких элементов.
Эта операция может представлена в виде:
\[
\mu_A^{более-менее}(x)=\sqrt{\mu_A(x)}.
\]
В данном примере рассмотрен метод комплексной оценки финансового состояния предприятия, позволяющий одновременно оценить степень риска его банкротства.
В основе примера лежит использование теории нечетких множеств в финансовом менеджменте.
Понятно, что оценка финансового состояния предприятия опирается на его финансовые показатели, заметим, что универсальных показателей нет.
Анализируя деятельность предприятия, нужно учитывать его уникальность, специфику, а не все "стричь под одну гребенку".
Эксперту во время его работы необходимо выбрать ряд отдельных финансовых показателей, о которых можно сказать, что они наилучшим образом характеризуют отдельные стороны деятельности предприятия и
при этом образуют некую законченную совокупность, дающую исчерпывающее представление о предприятии как о целом.
Значимость тех или иных показателей для оценки тех или иных предприятий различна, и поэтому перед экспертом встает трудная задача отбора и ранжирования факторов анализа.
Показатели, классифицированные по группам (финансовая устойчивость, ликвидность, рентабельность и т.д.), могут образовывать иерархию, но в простейшем случае они просто составляют неупорядоченный набор.
Причем здесь и далее по умолчанию предполагаем, что рост отдельного показателя Хi сопряжен со снижением степени риска банкротства и с улучшением состояния рассматриваемого предприятия.
Если для данного показателя наблюдается противоположная тенденция, то в анализе его следует заменить сопряженным.
Например, показатель доли заемных средств в активах предприятия разумно заменить показателем доли собственных средств в активах.
Пример системы показателей (заметим, что показатели упорядочены по уменьшению их значимости, если вы желаете изменить порядок, что может быть существенным для данной задачи, перетяните мышкой показатель
на то место, которое, с вашей точки зрения, должен занимать этот показатель.):
X1: Коэффициент автономии (отношение собственного капитала к валюте баланса),
X3: Коэффициент промежуточной ликвидности (отношение суммы денежных средств и дебиторской задолженности к краткосрочным пассивам),
X4: Коэффициент абсолютной ликвидности (отношение суммы денежных средств к краткосрочным пассивам),
X5: Оборачиваемость всех активов в годовом исчислении (отношение выручки от реализации к средней за период стоимости активов),
X6: Рентабельность всего капитала (отношение чистой прибыли к средней за период стоимости активов).
Сопоставим каждому показателю Хi уровень его значимости для анализа ri.
Чтобы оценить этот уровень, нужно расположить все показатели по порядку убывания значимости так, чтобы выполнялось правило
Получение оценки ri экспертом, является достаточно сложным, так как зависит не только от конкретного предприятия, но и от того или иного этапа его деятельности, поэтому, как правило,
ограничиваются тем, что система показателей проранжирована в порядке убывания их значимости.
Итак, будем считать, что об уровне значимости показателей неизвестно ничего кроме факта, что показатели проранжированы в порядке убывания их значимости.
Полагая, что оценка ri отвечает максиму энтропии наличной информационной неопределенности об объекте исследования, П.Фишберн предложил следующую формулу для расчета
\[
r_i=\frac{2(n-i+1)}{n(n+1)}.
\]
Для нашего примера имеем
Распознавание уровня показателя – самый деликатный вопрос данного метода. Эта процедура целиком отдается на откуп эксперту, в расчете на его опыт.
Значение уровней финансовых показателей, которые соотносятся с лингвистическими переменными - очень низкий,низкий, средний,высокий и очень высокий, отражается таблицей \((\lambda_{i,j})_{i=1,j=1}^{6,5}\):
Классификатор уровней финансовых показателей
Шифр показателя
Наименование показателя
Критерий разбиения по уровням:
очень низкий
низкий
средний
высокий
очень высокий
X1
Коэффициент автономии (отношение собственного капитала к валюте баланса),
Коэффициент промежуточной ликвидности (отношение суммы денежных средств и дебиторской задолженности к краткосрочным пассивам),
X4
Коэффициент абсолютной ликвидности (отношение суммы денежных средств к краткосрочным пассивам),
X5
Оборачиваемость всех активов в годовом исчислении (отношение выручки от реализации к средней за период стоимости активов),
X6
Рентабельность всего капитала (отношение чистой прибыли к средней за период стоимости активов).
Построение комплексного финансового показателя проводится следующим образом:
\[
V\& M=\sum_{j=1}^5 0.1\times j\sum_{i=1}^nr_i\lambda_{i,j}.
\]
Чем выше уровень показателя V&M, тем лучше обстоит дело с финансами предприятия.
Для нашего примера получаем
V&M==.
Для заключения о финансовом состоянии предприятия и об уровне риска банкротства используем классификатор уровня комплексного показателя V&M, настроенный на системе весов:
Основой для проведения операции нечеткого логического вывода является база правил, содержащая нечеткие высказывания в форме «ЕСЛИ-ТО» и функции принадлежности для соответствующих лингвистических термов.
При этом должны соблюдаться следующие условия:
Существует хотя бы одно правило для каждого лингвистического терма выходной переменной.
Для любого терма входной переменной имеется хотя бы одно правило, в котором этот терм используется в качестве предпосылки (левая часть правила).
В противном случае имеет место неполная база нечетких правил.
Пусть в базе правил имеется m правил вида:
R1: ЕСЛИ x1 это A1,1...И...xn это A1,n, ТО y это B1,
...
Ri: ЕСЛИ x1 это Ai,1...И...xn это Ai,n, ТО y это Bi,
...
Rm: ЕСЛИ x1 это Am,1...И...xn это A1,n, ТО y это Bm,
где xk, k=1..n — входные переменные; y — выходная переменная; Ai,k — заданные нечеткие множества с функциями принадлежности.
Результатом нечеткого вывода является четкое значение переменной y* на основе заданных четких значений xk, k=1..n.
В общем случае механизм логического вывода включает четыре этапа:
введение нечеткости (фазификация),
нечеткий вывод,
композиция и
приведение к четкости, или дефазификация.
Алгоритмы нечеткого вывода различаются, главным образом, видом используемых правил, логических операций и разновидностью метода дефазификации.
Разработаны модели нечеткого вывода Мамдани, Сугено, Ларсена, Цукамото.
Наиболее распространенный способ логического вывода в нечетких системах - алгоритм Мамдани (Mamdani).
В нем используется минимаксная композиция нечетких множеств. Данный метод включает в себя следующую последовательность действий:
Процедура фазификации: определяются степени истинности, т.е. значения функций принадлежности для левых частей каждого правила (предпосылок).
Для базы правил с m правилами обозначим степени истинности как Ai,k(xk), i=1..m, k=1..n.
Нечеткий вывод. Сначала определяются уровни «отсечения» для левой части каждого из правил: \(\beta_i=\min_i\{A_{i,k}(x_k)\}\).
Далее находятся «усеченные» функции принадлежности: \(B'_i(y)=\min_i\{\beta_i,B_i(y)\}\).
Композиция, или объединение полученных усеченных функций, для чего используется максимальная композиция нечетких множеств:\(\max_i\{B'_i(y)\}\)
— функция принадлежности итогового нечеткого множества.
Дефазификация, или приведение к четкости. Существует несколько методов дефазификации. Например, метод среднего центра, или центроидный метод:
\[
y^{*}=\frac{\int\limits_y yB(y)}{\int\limits_y B(y)}.
\]
Геометрический смысл такого значения — центр тяжести итоговой фигуры.
В нечетких моделях Цукамото (Tsukamoto) вывод каждого нечеткого правила «если-то» представлен нечетким множеством с монотонной функцией принадлежности.
В результате предполагаемый результат каждого правила определяется как четкое значение.
Общий вывод принимается как средневзвешенное значение вывода каждого правила.
Поскольку каждое правило предполагает четкие выходные данные, нечеткая модель Цукамото агрегирует выходные данные каждого правила методом
средневзвешенного значения и, таким образом, позволяет избежать трудоемкого процесса дефаззификации.
В этом преимущество алгоритма Цукамото перед алгоритмом Мамдани, с другой стороны, условие монотонности функции принадлежности нечеткого вывода существенно сужают область применения алгоритма Цукамото.
Sugeno и Takagi предполагали, что вывод можно представвить в виде линейных функций. Это еще более жесткое ограничение, чем у алгоритма Цукамото, но при этом, как и в предыдущем случае,
общий вывод принимается как средневзвешенное значение вывода каждого правила, что позволяет сразу получить четкий вывод без использование процесса дефаззификации.
Рисунок графически показывает процесс нечеткого вывода для двух входных переменных и двух нечетких правил.
Здесь Вариант 1 иллюстрирует метод Tsukamoto, Вариант 2 - метод Mamdani и Вариант 3 - Sugeno. Наиболее популярным является алгоритм Мамдани.
Вначале простой пример иллюстритующий метод нечеткого вывода Мамдани.
Анализ надежности банка.
Пусть были установлены следующие правила:
Если банк образован недавно, значит его надежность низкая.
Если время работы банка среднее, значит и его надежность средняя.
Если банк существует достаточно давно, значит его надежность высокая.
Диапазон времени существования банков, находится в интервале от 5 лет до 15 лет и лингвистическая переменная "длительность работы банка" включает три
нечеткие переменные: "малая" -
\[
B_1(y)=\left\{
\begin{array}{lll}
1, & \hbox{ если }& y\lt 1,\\
\frac{8-y}{7}, & \hbox{ если } & 1\le y\le 5, \\
0, & \hbox{ если }& y\gt 5,
\end{array}
\right.
\]
"средняя" -
\[
B_2(y)=\left\{
\begin{array}{lll}
\frac{y-5}{3}, & \hbox{ если }& 5\le y\lt 8\\
\frac{10-y}{2}, & \hbox{ если } & 8\le y\le 10, \\
0, & \hbox{ иначе },
\end{array}
\right.
\]
и "большая" -
\[
B_3(y)=\left\{
\begin{array}{lll}
0, & \hbox{ если }& y\lt 10,\\
\frac{y-8}{7}, & \hbox{ если } & 10\le y\lt 15, \\
1, & \hbox{ если }& y\gt 15.
\end{array}
\right.
\]
Лингвистическая переменная «Надежность банка» включает три нечеткие переменные «низкая»:
\[
A_1(x)=\left\{
\begin{array}{lll}
1, & \hbox{ если }& x\le 1,\\
2-x, & \hbox{ если } & 1\lt x\le 2, \\
0, & \hbox{ если }& x\gt 2,
\end{array}
\right.
\]
«средняя»
\[
A_2(x)=\left\{
\begin{array}{lll}
x-2, & \hbox{ если }& 2\le x\lt 3,\\
4-x, & \hbox{ если } & 3\le x\le 4, \\
0, & \hbox{ иначе, }
\end{array}
\right.
\]
и «высокая»
\[
A_3(x)=\left\{
\begin{array}{lll}
0, & \hbox{ если }& x\lt 3,\\
x-3, & \hbox{ если } & 3\le x\le 4, \\
1, & \hbox{ если }& x\gt 4,
\end{array}
\right.
\]
надежность оценена по пятибалльной шкале.
Проведем оценку банка, который действует 7 лет.
Тогда . Далее находятся «усеченные» функции принадлежности надежности банка:
Найдем абсциссу центра тяжести этой фигуры, она равна . Учитывая используемую пятибальную шкалу, это и есть оценка надежности банка по пятибальной системе.
Рассмотрим этот же пример для метода Цукамото.
Представим функции принадлежности надежности банка в виде монотонной функции, например, таким образом:
Тогда для выбранного срока существования банка получаем
Используя средневзвешенную оценку
\[u=\frac{w_1\times u_1+w_2\times u_2}{w_1+w_2}\]
получаем надежность банка составляет баллов.
Метод Сугено еще больше упрощает задачу - по сути, это тот же метод Цукамото, в котором функция принадлежности представляет собой монотонную функцию, как правило, линейную.
Например, для рассмотренной задачи представим надежность банка в виде:
Надежность низкая \(A_1(x)=1-\frac{x}{3}\) для \(x\in [0,3]\), иначе 0,
Надежность средняя \(A_2(x)=1-\frac{(x-3)^2}{9}\) для \(x\in [0,5]\), иначе 1,
Надежность высокая \(A_3(x)=\frac{x-3}{2}\) для \(x\in [3,5]\), иначе 0.
Результат так же, как и для метода Цукамото, рассчитывается путем вычисления средневзвешенной оценки. Для нашего примера надежность банка составляет баллов.
Централизованное водоснабжение является одним из фундаментальных факторов цивилизации. Где бы не появлялись крупные поселения человека, сразу возникала проблема водоснабжения.
Не просто водоснабжения, а обеспечения чистой, безопасной водой. Проблема обеззараживания воды была радикально решена только с появлением процесса хлорирования воды.
Станции водоподготовки, снабжающие необходимой для жизни питьевой водой, одновременно являются хранителями огромных количеств хлора, выступающего в
качестве «обезвреживателя» микробов. Хлорирование воды как средство ее обеззараживания было начато в начале 20 века и спасло огромное количество жизней,
остановив победное шествие кишечных инфекций.
Однако хлорирование воды имеет существенные недостатки. Прежде всего, хлор – отравляющее вещество и его производство и хранение в виде жидкости, находящейся под давлением в
баллонах или цистернах создает угрозу как для персонала, так и для жителей близлежащих районов. Эти обстоятельства усугубляются физико-химическими и токсикологическими
свойствами хлора, являющегося сильнодействующим ядовитым веществом удушающего характера. Токсикологические и физико-химические свойства хлора
определяют основные поражающие факторы при его аварийных выбросах (см.[С.С. Тимофеева, Е.А. Хамидуллина, О.А. Давыдкина Оценка аварийных рисков опасных объектов, использующих хлор в технологических процессах.-Вестник ИрГТУ №6(89) 2014 с.95-100]).
Целью данной работы является моделирование аварийных ситуаций разгерметизации емкостного оборудования с хлором с последующей оценкой риска для людей,
попавших в зону потенциального территориального риска вокруг аварийных объектов.
Основные причины возникновения аварий, сопровождающихся утечками хлора, включают технические причины, обусловленные неисправностью или изношенностью оборудования,
организационные причины, вызванные «человеческим фактором», а также их комбинацию, имеющую большую долю в структуре причин. Основные причины рассматриваемых аварий
представлены в виде диаграммы
Уровень опасности аварийной утечки хлора зависит от многих факторов, в частности от геометрических размеров сквозного отверстия в сосуде или трубопроводе, давления в них,
температуры окружающей среды, скорости ветра в приземном слое, вертикальной подвижности атмосферы, а также агрегатного состояния выделяющегося хлора. Наиболее опасны
утечки жидкого хлора, т.к. при испарении 1 л жидкого хлора образуется около 450 л газообразного Сl2.
В работе [Mahant, Narendra. “Risk Assessment is Fuzzy Business – Fuzzy Logic Provides the Way to Assess Off-site Risk from Industrial Installations”. Risk 2004. 2004. No. 206] рассмотрен анализ на основе нечеткой логики системы безопасности жизнедеятельности предприятия, на территории которого хранится хлор. В дальнейшем будем использовать
систему правил, рассмотренной в данной работе.
Итак, пусть на заводе внедрена система безопасности жизнедеятельности (Safety Management System, SMS), однако она не всегда отражает полную и точную информацию, поэтому всегда существует риск утечки хлора и, соответственно, последствия влияния на здоровье и жизнь людей. Если утечка хлора произошла непосредственно из резервуара, то этот вид риска характеризуется как внешний риск, поскольку он уже не может быть устранен в случае происшествия и его последствия сложно контролировать.
Ставится задача оценить риск операционной деятельности завода на жизнедеятельность сотрудников и жителей территории, расположенной вблизи от завода.
Решение поставленной задачи осуществляется с помощью методов нечеткой логики. В качестве входных переменных системы нечеткого вывода были рассмотрены:
надежности системы безопасности жизнедеятельности;
последствия от утечки хлора.
Для оценки первой из входных переменных экспертом была составлена таблица критериев надежности системы безопасности жизнедеятельности, в соответствии с которой группа экспертов оценивала ее на рассматриваемом заводе.
.
Надежность
Критерий
Шкала от 0 до 100
Низкая (Inadequate)
Система не отвечает необходимым условиям безопасности, нет тренингов для персонала по технике безопасности и пр.
45>
Средняя (Good)
Система, в целом, отвечает требованиям безопасности, но нет достаточной подготовки персонала.
45-75
Высокая (Excellent)
Система, которая полностью интегрирована в процесс деятельности предприятия, персонал ознакомлен системой.
>75
Оценка второй входной переменной основана на анализе давления (концентрации) хлора в резервуаре. Для этого экспертами опять же была составлена таблица категорий последствий
избыточного давления в случае утечки хлора.
Категория
Критерий
Шкала от 0 до 100
Категория 1
Концентрация хлора не превышает 50 PPM и в случае утечки не принесет вреда людям.
0 – 12
Категория 2
Концентрация хлора может достигать на короткие промежутки времени 100 PPM и в случае утечки лишь с малой вероятностью принесет лишь незначительные повреждения.
12 – 37
Категория 3
Концентрация хлора не превышает 100 PPM и в случае утечки принесет лишь незначительные повреждения.
37 – 62
Категория 4
Концентрация хлора не превышает 200 PPM и в случае утечки принесет повреждения людям с низкой вероятностью смертельного исхода.
62 – 87
Категория 5
Концентрация хлора превышает 200 PPM и в случае утечки с высокой вероятностью (допустим, 50%) приведет к смертельному исходу.
87 – 100
Выходная переменная «риск» операционной деятельности была оценена по следующим параметрам:
Категория риска
Критерий
Очень высокий
Высока вероятность смертельных исходов на заводе и прилегающей территории;
Высокий
Низкая вероятность смертельных исходов, но высокая вероятность вредя для здоровья;
Умеренный
Остается вероятность легких повреждений для здоровья.
Низкий
Нет риска смерти или вреда для здоровья.
Очень низкий
Полное отсутствие риска для резидентов.
Для формирования системы нечеткого вывода были сформулированы 12 правил:
Если "Последствия утечки соответствуют Категории 5" и "НАДЕЖНОСТЬ SMS Низкая" ТО "Риск Очень высокий"
Если "Последствия утечки соответствуют Категории 5" и "НАДЕЖНОСТЬ SMS Средняя" TO "Риск Высокий"
Если "Последствия утечки соответствуют Категории 5" и "НАДЕЖНОСТЬ SMS Высокая" ТО "Риск Умеренный"
Если "Последствия утечки соответствуют Категории 4" и "НАДЕЖНОСТЬ SMS Низкая" ТО "Риск Высокий"
Если "Последствия утечки соответствуют Категории 4" и "НАДЕЖНОСТЬ SMS Средняя" ТО "Риск Умеренный"
Если "Последствия утечки соответствуют Категории 4" и "НАДЕЖНОСТЬ SMS Высокая" ТО "Риск Низкий"
Если "Последствия утечки соответствуют Категории 3" и "НАДЕЖНОСТЬ SMS Низкая" ТО "Риск Умеренный"
Если "Последствия утечки соответствуют Категории 3" и "НАДЕЖНОСТЬ SMS Средняя" ТО "Риск Низкий"
Если "Последствия утечки соответствуют Категории 3" и "НАДЕЖНОСТЬ SMS Высокая" ТО "Риск Очень низкий"
Если "Последствия утечки соответствуют Категории 2" и "НАДЕЖНОСТЬ SMS Средняя" ТО "Риск Низкий"
Если "Последствия утечки соответствуют Категории 2" и "НАДЕЖНОСТЬ SMS Высокая" ТО "Риск Очень низкий"
Если "Последствия утечки соответствуют Категории 1" ТО "Риск Очень низкий"
Традиционно нечеткие модели строятся на использовании треугольных и трапецивидных чисел, причем размеры этих чисел выбираются на основе экспертных оценок, то есть, достаточно субъективно.
Рассмотрим более строгий подход.
Пусть имеется элемент четкой логики \(B_0(x)\), определенный следующим образом:
Для фаззификации данного элемента применим к нему оператор Стеклова:
\[
\Phi_h(f,x)=\frac{1}{h}\int_{x-h/2}^{x+h/2}f(t)dt.
\]
Тогда \(\Phi_h(B_0,x)\), будет иметь вид
\(\Phi_{h/2}(B_0,x)\), будет иметь вид
Таким образом, для приведения четкого случая к нечеткому нужно применить оператор Стеклова с соответствующим шагом.
Более того, можно этот процесс повторять, получая все более сложные нечеткие конструкции, так \(\frac{4}{3}\Phi_h(\Phi_h(B_0,x),x)\) (здесь 4/3 нормировочный коэффициент, чтобы функция принадлежности изменялась в интервале [0,1])
Вначале рассмотрим простую модель, основанную на использовании треугольных и трапецивидных чисел.
Тогда, проводя процесс фазиффикации критерия надежности, применим к четким критериям оператор Стеклова с шагом в 30 единиц и получаем
Критерий «риск» операционной деятельности имеет вид
Наконец, давление (концентрация) хлора в резервуаре
При надежности системы безопасности в 50 баллов,
оценим последствия давления утечки в 70 баллов, тогда используя алгоритм
нечеткого вывода Мамдани, получаем для оценки системы безопасности
а для давления (концентрации) хлора в резервуаре
Усекая функции принадлежности риска операционной деятельности, получаем
В соответствии с используемыми правилами нечеткого вывода, после дефаззификации получаем, что оценка риска равна
.
Понятно, что описанное решение является модельным, для реальной системы нужно, хотя бы усложнить модель, применив в треугольным и трапециевидным числам оператор Стеклова.