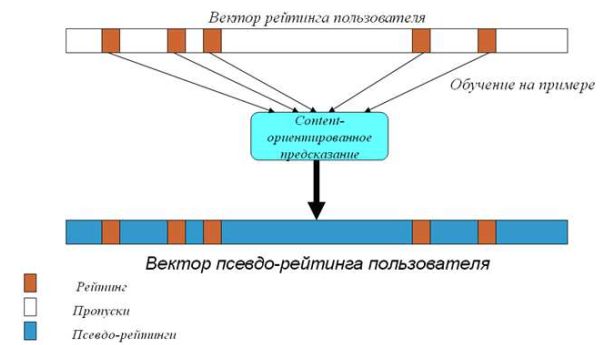
Задача 1.
Для коллекции книг
| ID | Книга |
|---|
| 329 | Стругацкий А., Стругацкий Б. Понедельник начинается в субботу: Сказка для научных работников младшего возраста. — М.: Детская литература, 1965. — 224 с. |
| 1204 | Керниган Б., Ритчи Д. Язык программирования Си. — Москва: Финансы и статистика, 1992. — 272 с. |
| 1611 | Джеймс Э.Л. Пятьдесят оттенков серого. — Москва: Эксмо,2015. — 480 с. |
дана таблица рейтингов
| Пользователь | Книга | Рейтинг |
|---|
| Иванов | 329 | 2 |
| Иванов | 1611 | 5 |
| Петров | 329 | 5 |
| Петров | 1204 | 2 |
| Сидоренко | 329 | 3 |
| Сидоренко | 1204 | 4 |
| Сидоренко | 1611 | 1 |
| Скибка | 1204 | 3 |
| Скибка | 1611 | 2 |
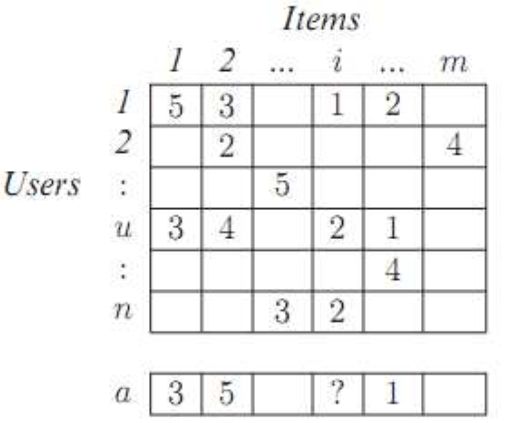
Используя методы коллаборативной фильтрации, получить значения недостающих рейтингов.
Задача 2.
Пользователь просмотрел фильмы и выставил им оценку
| Фильм | Режиссер | Актеры (главная роль) | Жанр | Оценка |
|---|
| Иван Васильевич меняет профессию | Гайдай Л. | Демьяненко А., Яковлев Ю. | Комедия | 4 |
| Бриллиантовая рука | Гайдай Л. | Никулин Ю., Миронов А. | Комедия | 4 |
| Терминатор | Кэмерон Д. | Шварцнеггер А. | Фантастика | 5 |
| Неудержимые | Сталлоне С. | Шварцнеггер А. | Боевик | 0 |
| Правдивая ложь | Кэмерон Д. | Шварцнеггер А. | Боевик | 4 |
| Аватар | Кэмерон Д. | Уортингтон С. | Фантастика | 5 |
| Олимпиус Инферно | Волошин И. | Филоненко П., Цаллати В. | Боевик | 0 |
| Хардкор | Найшуллер И. | Козловский Д. | Фантастика | 1 |
| Холодное сердце | Бак К., Ли Д. | | Мультфильм | 4 |
| Безумный Макс: дорога ярости | Миллер Д. | Харди Т. | Фантастика | 1 |
| Долгий путь | Гайдай Л. | Яковлев С., Игнатова К. | Мелодрама | 3 |
| Спортлото-82 | Гайдай Л. | Арлаускас А., Аманова С. | Комедия | 2 |
Используя методы контекстной фильтрации, определить какой их перечисленных ниже фильмов рекомендовать пользователю.
| Фильм | Режиссер | Актеры (главная роль) | Жанр | Рейтинг |
|---|
| Операция «Ы» и другие приключения Шурика | Гайдай Л. | Демьяненко А., Селезнева Н. | Комедия | |
| Джуниор | Райтман А. | Шварцнеггер А., Де Вито Д. | Комедия | |
| Титаник | Кэмерон Д. | Ди Каприо Л., Уинслет К. | Мелодрама | |
| Брат | Балабанов А. | Бодров С. | Боевик | |
| Люди Икс: последняя битва | Рэтнер Б. | Джекман Х. | Фантастика | |
| Остаться в живых | Сталлоне С. | Траволта Д. | Боевик | |
Задача 3.
Определить рейтинг фильмов из условия предыдущей задачи, если данные берутся из таблицы
| Фильм | Режиссер | Актеры (главная роль) | Жанр | Количество просмотров | Оценка |
|---|
| Иван Васильевич меняет профессию | Гайдай Л. | Демьяненко А., Яковлев Ю. | Комедия | 4 | 4 |
| Бриллиантовая рука | Гайдай Л. | Никулин Ю., Миронов А. | Комедия | 5 | 5 |
| Терминатор | Кэмерон Д. | Шварцнеггер А. | Фантастика | 5 | 5 |
| Неудержимые | Сталлоне С. | Шварцнеггер А. | Боевик | 1 | 0 |
| Правдивая ложь | Кэмерон Д. | Шварцнеггер А. | Боевик | 4 | 4 |
| Аватар | Кэмерон Д. | Уортингтон С. | Фантастика | 3 | 5 |
| Олимпиус Инферно | Волошин И. | Филоненко П., Цаллати В. | Боевик | 1 | 0 |
| Хардкор | Найшуллер И. | Козловский Д. | Фантастика | 1 | 1 |
| Холодное сердце | Бак К., Ли Д. | | Мультфильм | 2 | 4 |
| Безумный Макс: дорога ярости | Миллер Д. | Харди Т. | Фантастика | 1 | 1 |
| Долгий путь | Гайдай Л. | Яковлев С., Игнатова К. | Мелодрама | 1 | 3 |
| Спортлото-82 | Гайдай Л. | Арлаускас А., Аманова С. | Комедия | 1 | 2 |