Кластеризация — процесс разбиения заданной выборки объектов (наблюдений) на подмножества (как правило, непересекающиеся), называемые кластерами, так, чтобы каждый кластер состоял из схожих объектов, а объекты разных кластеров существенно отличались.
Различные инструменты для кластеризации данных можно найти на веб-сайте Science Hunter.
Одной из целей кластеризации является выявление внутренних связей между данными путём определения кластерной структуры. Разбиение наблюдений на группы схожих объектов позволяет упростить дальнейшую обработку данных и принятие решений, применяя к каждому кластеру свой метод анализа - “divide et impera” (стратегия «разделяй и властвуй»).
Одним из приложений кластеризации является решение задачи сжатия данных. В случае, если исходная выборка избыточно большая, то можно сократить её, оставив несколько наиболее характерных представителей от каждого кластера.
Другой сферой использования кластеризация является обнаружение новизны в исследуемом множестве объектов. Выделяются нетипичные объекты, которые не удаётся присоединить ни к одному из кластеров. Для решения задач методами кластерного анализа, необходимо задавать количество кластеров заранее. В одном случае число кластеров стараются сделать поменьше. В другом случае важнее обеспечить высокую степень сходства объектов внутри каждого кластера, а кластеров может быть сколько угодно. В третьем случае наибольший интерес представляют отдельные объекты, не вписывающиеся ни в один из кластеров.
Пусть множество объектов \(\Im=\left\{x_i\right\}_{i=1}^n\), представленных набором атрибутов \(x_i=\left\{t_1^i,t_2^i,...,t_m^i\right\}_{i=1}^n\),
где \(t_\nu^i\) принимает значения из заданного множества \(T^i_\nu\).
Задача кластеризации состоит в построении множества C=\(\left\{C_\nu\right\}_{\nu=1}^k\) и отображения \(F:\Im\to\)C заданного множества объектов на множество кластеров.
Кластер содержит объекты из \(\Im\) похожие (по заданному критерию) друг на друга \(x_i\in C_\nu,x_j\in C_\nu \Rightarrow d(x_i,x_j)\lt\varepsilon\),
где \(d(\bullet,\circ)\) степень схожести между объектами (чаще всего это расстояние), а ε - максимальное значение порога, формирующего один кластер.
Наиболее используемыми мерами схожести является понятие расстояния между двумя точками \(\|x_i-x_j\|\). Приведем некоторые наиболее часто используемые определения расстояния.
Евклидово (среднеквадратическое или ℓ2) расстояние
\[d_2(x_i,x_j)=\|x_i-x_j\|_2=\sqrt{\sum_{\nu=0}^m\left(t_\nu^i-t_\nu^j\right)^2}\]
Рис.1. Иллюстрация Евклидова расстояния.
расстояние ℓ1 (в англоязычной литературе – манхеттеновское или городское расстояние)
\[d_1(x_i,x_j)=\|x_i-x_j\|_1=\sum_{\nu=0}^m\left|t_\nu^i-t_\nu^j\right|\]
Рис. 2. Иллюстрация расстояния ℓ1.
используется в том случае, когда нужно уменьшить влияние отдельных выбросов;
Чебышевское (равномерное или ℓ∞) расстояние
\[d_\infty(x_i,x_j)=\|x_i-x_j\|_\infty=max\left\{\left.\left|t_\nu^i-t_\nu^j\right|\right|\nu=0,..,m\right\}\]
Рис. 3. Иллюстрация расстояния Чебышева.
используется если нужно увеличить влияние отдельных выбросов;
расстояние Махалонобиса \[d_M(x_i,x_j)=\|x_i-x_j\|_M=\sqrt{(x_i-x_j)^T\Sigma^{-1}(x_i-x_j)}\] используется в случае, если нужно учесть корреляцию на конкретном классе.
Здесь Σ корреляционная матрица.
Заметим, что во многих случаях вместо расстояния в качестве критерия близости используется значение косинуса угла между двумя векторами
\[
\cos{\varphi_{i,j}=\frac{x_i^Tx_j}{\|x_i\|_2\|x_j\|_2}},
\]
тогда степень сходства между векторами (точками) \(x_i,x_j\) можно записать в виде
\[
d_{cos}(x_i,x_j)=1-\frac{x_i^Tx_j}{\|x_i\|_2\|x_j\|_2}.
\]
Корреляция Пирсона (Pearson) измеряет степень линейной зависимости между двумя профилями, в этом случае степень сходства будет иметь вид
\[
d_{cor}(x_i,x_j)=1-\frac{\sum_{\nu=1}^m\left(t_\nu^i-\bar{t}^i\right)\left(t_\nu^j-\bar{t}^j\right)}
{\sqrt{\sum_{\nu=1}^m\left(t_\nu^i-\bar{t}^i\right)^2\sum_{\nu=1}^m\left(t_\nu^j-\bar{t}^j\right)^2}}
\]
Метод r-ранговой корреляции Спирмена (Spearman) позволяет определить тесноту (силу) и направление корреляционной связи между двумя элементами или
двумя профилями (иерархиями) признаков, и степень сходства можно записать в виде
\[
d_{spear}(x_i,x_j) = 1-r\left(x_i,x_j\right)=1 - \frac{\sum\limits_{\nu=1}^m (\tau_\nu^i - \bar{\tau}^i)(\tau_\nu^j - \bar{\tau}^j)}
{\sqrt{\sum\limits_{\nu=1}^m(\tau_\nu^i - \bar{\tau}^i)^2 \sum\limits_{\nu=1}^m(\tau_\nu^j -\bar{\tau}^j)^2}}
\]
где \(\{\tau^i_\nu\} = rank(\{t^i_\nu\})\) и \(\{\tau^j_\nu\} = rank(\{t^j_\nu\})\).
Метод корреляции Кендалла (Kendall) измеряет соответствие между ранжированием переменных \(x_i\) и \(x_j\)
и является альтернативой корреляции Спирмена. Он предназначен для определения взаимосвязи между двумя ранговыми переменными.
Интерпретация результатов вычисления коэффициента ранговой корреляции Кендалла определяется как разность вероятностей совпадения и инверсии в рангах.
Коэффициент ранговой корреляции \(\tau\) Кендалла, как и коэффициент ранговой коррелеяции Спирмена, предназначен для определения взаимосвязи между двумя
ранговыми переменными.
Для одних и тех же значений переменных значения коэффициента корреляции Спирмена будут всегда немного больше, чем значения коэффициента ранговой
корреляции Кендалла, тогда как уровень значимости будет одинаков или же у коэффициента корреляции Кендалла будет немного больше.
Формула вычисления коэффициента ранговой корреляции Кендалла может быть следующим образом:
\[\tau= \frac{m_c - m_d}{\frac{1}{2}m(m-1)}, \]
где \(m_c\) — число совпадений, \(m_d \)— число инверсий, m — объем выборки
При наличии связанных рангов формула изменяется с учетом поправки на связанные ранги:
\[\tau=\frac {m_c - m_d}{\sqrt{\left[m\frac{(m-1)}{2}\right] - K_i} \sqrt{\left[m\frac{(m-1)}{2}\right] - K_j}}, \]
где \(K_i\) поправка на связи рангов переменной \(x_i\),
\(K_j\) — поправка на связи рангов переменной \(x_j\)
\[K_i=0,5\Sigma_is_i(s_i - 1),\]
где \(i\) — количество групп связей по \(x_i\), \(s_i\) — численность группы \(x_i\)
\[K_j=0,5\Sigma_js_j(s_j - 1),\]
где \(j\) — количество групп связей по \(x_j\), \(s_j\) — численность группы \(x_j\).
Таким образом, общее число возможных наблюдений для сравнения значений признаков равно \(m(m-1)/2\). Вначале нужно упорядочить пары по
значениям \(x_i\).
Если \(x_i\) и \(x_j\) коррелированы, то они будут иметь одинаковые порядки относительного ранга.
Теперь для каждого \(\nu\gt \xi\) нужно подсчитать число \(t^j_\nu\ge t^j_\xi\) (согласованные пары (c)) и число \(t^j_\nu\lt t^j_\xi\)
(несогласованные пары (d)). Расстояние согласно корреляции Кендалла определяется следующим образом:
\[
d_{kend}(x_i, x_j) = 1 - \frac{m_c - m_d}{\frac{1}{2}m(m-1)}
\]
Выбор степени схожести очень важен, так как он оказывает сильное влияние на результаты кластеризации (что видно на примере).
Для большинства распространенных методов кластеризации по умолчанию это евклидово расстояние.
В зависимости от типа данных и поставленных задач одни критери схожести могут быть предпочтительнее других.
Например, расстояние, основанное на корреляции, часто используется в анализе данных в медицине.
Расстояние на основе корреляции рассматривает два объекта одинаковыми, если их особенности сильно коррелированы, хотя наблюдаемые значения могут
быть далеки друг от друга в терминах евклидова расстояния. Расстояние между двумя объектами равно 0, когда они отлично коррелированы.
Корреляция Пирсона довольно чувствительна к выбросам. В случае, если наличие выбросов не принципиально, их влияние можно смягчить,
используя корреляцию Спирмена вместо корреляции Пирсона.
Нормализация (стандартизация) данных.
Для задачи кластеризации очень важно, чтобы все данные были соизмеримы, т.е. чтобы не получилось, что одна часть данных измеряется в упаковках,
а другая – в килограммах, другими словами, на первом этапе кластеризации всегда нужно проводить нормализацию данных.
Значение дистанционных мер тесно связано со шкалой, на которой производятся измерения.
Поэтому перед анализом имеющихся данных, их вначале часто масштабируют (т.е. стандартизируют).
Это особенно рекомендуется, если одни и те же переменные измеряются в разных масштабах (например: килограммы, километры, сантиметры, ...),
в противном случае данные, имеющиеся незначительные отклонения, могут оказать серьезное влияние на полученный результат.
Цель состоит в том, чтобы сопоставить переменные. Обычно переменные масштабируются так, чтобы стандартное отклонение было равно нулю:
\[
\frac{x_i - center(x)}{scale(x)},
\]
где \(center(x)\)может быть средним или медианным значений х, а \(scale(x)\) может быть стандартным отклонением, межквантильным диапазоном или средним
абсолютным отклонением.
Однако, нужно заметить, что стандартизация делает меры измерения расстояния - Евклида, Манхэттена и корреляции более похожими. Так при
стандартизации данных существует функциональная зависимость между коэффициентом корреляции Пирсона и евклидовым расстоянием:
\[
d_{euc}(x_i, x_j) = \sqrt{2m[1 - r(x_i, x_j)]},
\]
где \(x_i, x_j\) - два стандартизированных \(m\)-вектора с нулевым средним значением и единичной длиной.
Поэтому результат, полученный с помощью корреляционных мер Пирсона и стандартизованных евклидовых расстояний, сопоставим.
Если выбрано евклидово расстояние, то наблюдения с большими значениями характеристик будут сгруппированы вместе.
То же самое справедливо и для наблюдений с низкими значениями признаков.
Кроме того, при проведении процедуры кластеризации нужно заранее задаваться либо числом кластеров, либо критерием, характеризующем близость
элементов внутри кластера либо удаленность самих кластеров друг от друга.
Условно методы кластеризации разбиваются на два класса - иерархические и неиерархические.
В неиерархических алгоритмах присутствует наличие условия остановки и количества кластеров. Основой этих алгоритмов является гипотеза о сравнительно небольшом числе скрытых факторов, которые
определяют структуру связи между признаками.
Иерархические алгоритмы не завязаны на количестве кластеров.
Эта характеристика определяется по динамике слияния и разделения кластеров во время построения дерева вложенных кластеров (дендрограммы).
В свою очередь, иерархические алгоритмы делятся на агломеративные, которые строятся путем объединения элементов,
то есть уменьшением количества кластеров, и дивизимные, основанные на разделении (расщеплении) существующих групп (кластеров).
Иерархические алгоритмы.
Пусть имеем \(n\) точек в \(d\)-мерном пространстве. Целью иерархической кластеризации является создание последовательности вложенных разделов, которые можно удобно визуализировать с помощью дерева или иерархии кластеров, называемых кластерной дендрограммой.
Кластеры в иерархиях варьируются от мелкозернистого до крупнозернистого - самый низкий уровень дерева (листья) состоит из каждой точки в
своем кластере, тогда как самый высокий уровень (корень) состоит из всех точек в одном кластере. Оба эти случая могут считаться
тривиальными кластерами. На каком-то промежуточном уровне можно найти необходимые значимые кластеры.
Если пользователю необходимое заданное количество кластеров \(k\), то можно выбрать уровень, на котором есть k кластеров.
Существует два основных алгоритмических подхода к иерархической кластеризации - агломеративный и дивизимный.
Агломеративные стратегии работают снизу вверх, начиная с каждой из n точек в отдельном кластере, они пытаются
объединить наиболее похожие пары кластеров, пока все точки не станут членами одного и того же
кластера.
Дивизимные стратегии делают как раз наоборот, работая сверху вниз, начиная со всех точек в одном кластере, они рекурсивно разделяют кластеры,
пока все точки не будут находится в отдельных кластерах.
Иерархические агломеративные алгоритмы.
Рассмотрим набор данных \(D = \{x_1, ..., x_n\}\), где \(x_i \in R^d\) и кластеризацию C = \(\{C_1, ..., C_k\}\),
разделяющую множество \(D\), то есть каждый кластер представляет собой множество точек \(C_i \in D\), так что кластеры
попарно не пересекаются Ci ∩ Cj = ∅ (для всех \(i\ne j\)) и \(\bigcup_{i=1}^kC_i=D\). Кластеризация
\(A = \{A_1,..., A_r\}\) называется вложенной в другую кластеризацию \(B = \{B_1, ..., B_s\}\), если, как только \(r> s\) и для каждого
кластера \(A_i \in A\) существует кластер \(B_j \in B\),
такой, что \(A_i \subseteq B_j\). Иерархическая кластеризация дает последовательность из n вложенных множеств
C1 , ..., Cn , начиная от тривиальной кластеризации C1 =\(\{\{x_1\}, ..., \{x_n\}\}\), где каждый
элемент находится в отдельном кластере, до другой тривиальной кластеризации Cn =\(\{\{x_1, ..., x_n\}\}\),
где все точки находятся в одном кластере. В общем случае кластеризация Ct-1 вложена в
кластеризацию Ct .
Дендрограмма кластера представляет собой корневое двоичное дерево, которое описывает структуру вложенности с ребрами между кластерами
Ci∈Ct-1 и кластером Cj∈Ct, если Ci
вложено в Cj, т.е. если Ci∈Cj. Таким образом, дендрограмма захватывает всю
последовательность вложенных кластеров.
Кластеризация областей Украины по размеру средней зарплаты на 2017 год
В агломерационной иерархической кластеризации процесс начинается с того, что каждой из n точек ставится в соответствие отдельный кластер.
Далее идет итерационное объединение двух ближайших кластеров в один, пока все точки не будут членами одного и того же кластера.
Формально, учитывая набор кластеров C = \(\{C_1, C_2, ..., C_m\}\), найдем ближайшую пару
кластеров \(C_i\) и \(C_j\) и объединим их в новый кластер \(C_{ij} = C_i \bigcup C_j\). Затем
обновим набор кластеров, удалив \(C_i\) и \(C_j\) и добавим \(C_{ij}\): C =C\{{Ci}\(\bigcup\) {Cj}}
\(\bigcup \){Cij}. Мы повторяем процесс до тех пор, пока C не будет содержать только один кластер.
Поскольку на каждом шаге количество кластеров уменьшается на единицу, этот процесс приводит к последовательности n вложенных кластеров.
По требованию можно остановить процесс объединения, когда осталось ровно k кластеров.
C ← C \{{Ci} ∪ {Cj} ∪ {Cij} // Обновление кластеризации
Обновить матрицу расстояния Δ, чтобы провести новую кластеризацию
до |C| = k
Ключевым элементом алгоритма является определение ближайшей пары кластеров, то есть выбор критерия схожести.
Как уже отмечалось, наиболее распространенным критерием схожести является метрика (расстояние). Некоторые из критериев схожести уже были рассмотрены. Заметим, что выбор этого критерия существенно
сказывается на результате кластеризации.
При объединении \(i\) и \(j\)-го кластеров в один кластер, нужно вычислить расстояние от нового кластера до \(\nu\)-го кластера.
Традиционно, для пересчета расстояния во время слияния кластеров используются старые значения расстояний.
Как правило, при этом используют следующие критерии:
Рис. Результат применения агломеративной кластеризации с максимальным расстоянием.
Алгоритм на основе максимального расстояния способствует формированию компактных кластеров. К недостаткам относится эффект разрушения вытянутых кластеров.
\[
d_\mu \left( {C_i ,C_j } \right) = \left\| {\mu _i - \mu _j } \right\|, \mu_j=\frac{1}{n_j}\sum_{x\in C_j}x.
\]
На практике достаточно неплохо работают алгоритмы, основанные на среднем расстоянии, но, с точки зрения робастности и эффективности с вычислительной точки зрения, более эффективны алгоритмы, основанные на расстоянии между центрами кластеров.
В методе Уорда (Ward, J. H., Jr. (1963), "Hierarchical Grouping to Optimize an Objective Function", Journal of the American Statistical Association, 58, 236–244.) в качестве расстояния между кластерами берётся прирост суммы квадратов расстояний объектов до центров кластеров,
получаемый в результате их объединения. На каждом шаге алгоритма объединяются такие два кластера, которые
приводят к минимальному увеличению целевой функции, то есть внутригрупповой суммы квадратов. Этот метод направлен на
объединение близко расположенных кластеров.
Расстояние между двумя кластерами определяется как увеличение суммы квадрата ошибок при объединении двух кластеров.
Для данного кластера \(C_i\) ошибку можно записать следующим образом
\[\sum_{x\in C_i}\|x-\mu_i\|^2=\sum_{x\in C_i}{x^Tx}-2\sum_{x\in C_i}{x^T\mu_i}+\sum_{x\in C_i}{\mu_i^T\mu_i}=
\left(\sum_{x\in C_i}{x^Tx}\right)-n_i\mu_i^T\mu_i.\]
Ошибка кластеризации C = {C1, ..., Cm} задается как
\[\sum_{i=1}^m\sum_{x\in C_i}\|x-\mu_i\|^2\]
Мера Уорда определяет расстояние между двумя кластерами \(C_i\) и \(C_j\) как
изменение значения ошибки при объединении \(C_i\) и \(C_j\) в \(C_{ij}\), заданное как
\[\delta(C_i,C_j)=\sum_{x\in C_{ij}}\|x-\mu_{ij}\|^2-\sum_{x\in C_i}\|x-\mu_i\|^2-\sum_{x\in C_j}\|x-\mu_j\|^2.\]
Поскольку \(C_{ij} = C_i\) ∪ \(C_j\) и \(C_i\) ∩ \(C_j\) = ∅, мы имеем \(|C_{ij}|=n_{ij} = n_i + n_j\) и поэтому
\[\delta(C_i,C_j)=\sum_{z\in C_{ij}}\|z-\mu_{ij}\|^2-\sum_{x\in C_i}\|x-\mu_i\|^2-\sum_{y\in C_j}\|y-\mu_j\|^2\]
\[=\sum_{z\in C_{ij}}{z^Tz}-n_{ij}\mu_{ij}^T\mu_{ij}-\sum_{x\in C_{i}}{x^Tx}+n_{i}\mu_{i}^T\mu_{i}-
\sum_{y\in C_{j}}{y^Ty}+n_{j}\mu_{j}^T\mu_{j}\]
\[=n_{i}\mu_{i}^T\mu_{i}+n_{j}\mu_{j}^T\mu_{j}-(n_{i}+n_j)\mu_{ij}^T\mu_{ij}.\]
Отсюда и из того факта, что
\[\sum_{z\in C_{ij}}{z^Tz}=\sum_{x\in C_{i}}{x^Tx}+\sum_{y\in C_{j}}{y^Ty}\]
сразу получаем
\[
\mu_{ij}=\frac{n_i\mu_i+n_j\mu_j}{n_i+n_j},
\]
тогда
\[
\mu_{ij}^T\mu_{ij}=\frac{1}{\left(n_i+n_j\right)^2}\left(n_i^2\mu_{i}^T\mu_{i}+2n_in_j\mu_{i}^T\mu_{j}+n_j^2\mu_{j}^T\mu_{j}\right).
\]
Изменение значения ошибки при объединении кластеров примет вид
\[\delta(C_i,C_j)=n_i\mu_{i}^T\mu_{i}+n_j\mu_{j}^T\mu_{j}-
\frac{1}{\left(n_i+n_j\right)}\left(n_i^2\mu_{i}^T\mu_{i}+2n_in_j\mu_{i}^T\mu_{j}+n_j^2\mu_{j}^T\mu_{j}\right)
\]
\[
=\frac{1}{n_i+n_j}\left(n_i\left(n_i+n_j\right)\mu_{i}^T\mu_{i}+n_j\left(n_i+n_j\right)\mu_{j}^T\mu_{j}-
n_i^2\mu_{i}^T\mu_{i}-2n_in_j\mu_{i}^T\mu_{j}-n_j^2\mu_{j}^T\mu_{j}\right)
\]
\[
=\frac{n_in_j\left(\mu_{i}^T\mu_{i}-2\mu_{i}^T\mu_{j}+\mu_{j}^T\mu_{j}\right)}{n_i+n_j}
\]
\[
=\frac{n_in_j}{n_i+n_j}\|\mu_i-\mu_j\|^2.
\]
Таким образом, мера Уорда является взвешенной версией среднего расстояния между кластерами, кстати, при использовании евклидова расстояния
среднее расстояние можно переписать в виде
\(\delta\left(\mu_{i},\mu_{j}\right)=\|\mu_i-\mu_j\|^2.\)
Как видно, единственное отличие состоит в том, что мера Уорда изменяет расстояние между кластерами на половину гармонического среднего для размеров кластера
\[
\frac{2}{\frac{1}{n_1}+\frac{1}{n_2}}=\frac{2n_1n_2}{n_1+n_2}.
\]
Предложенная конструкция (А.А.Шумейко, С.Л.Сотник Использование агломеративной кластеризации для автоматической рубрикации
текстов // Системні технології. Регіональний міжвузівський збірник наукових праць. – Випуск 3(74).- Дніпропетровськ, 2011, c. 131-137)
в качестве степени похожести использует коэффициент обобщенной корреляции, и является естественным обобщением использования корреляции Пирсона.
На нижнем уровне построения дендрограммы будут пары элементов \(c_{i,j}=(x_i,x_j)\), характеризуемые коэффициентом обобщенной корреляции
\[
d_{c}(x_i,x_j)=\frac{\sum_{\nu=1}^m\left(t_\nu^i-\bar{t}^i\right)\left(t_\nu^j-\bar{t}^j\right)\omega\left(x_i,x_j\right)}
{\sqrt{\sum_{\nu=1}^m\left(t_\nu^i-\bar{t}^i\right)^2\sum_{\nu=1}^m\left(t_\nu^j-\bar{t}^j\right)^2}}
\]
где \(\omega\left(x_i,x_j\right)\) представляет собой весовую функцию общего вида, которая может зависеть как от конкретных элементов
векторов, так и от каких-то их общих характеристик (например, норм векторов).
Среди всех элементов нижнего уровня выберем элемент с наибольшим коэффициентом обобщенной корреляции. Пусть это будет элемент \(c_{i,j}\).
Для всех \(c_{i,\nu} (\nu\ne j)\) построим обобщенную корреляционную матрицу
\[
\mathcal{R}_{i,j,\nu}=
\left(
\begin{array}{lll}
d_{c}(x_i,x_i)& d_{c}(x_i,x_j)& d_{c}(x_i,x_\nu) \\
d_{c}(x_j,x_i)& d_{c}(x_j,x_j)& d_{c}(x_j,x_\nu) \\
d_{c}(x_\nu,x_i)& d_{c}(x_\nu,x_j)& d_{c}(x_\nu,x_\nu)
\end{array}
\right)
\]
Через
\[
\Lambda=\mathcal{R}_{i,j,\nu}^{-1}=
\left(
\begin{array}{lll}
\lambda_{i,i}& \lambda_{i,j}&\lambda_{i,\nu} \\
\lambda_{j,i}& \lambda_{j,j}&\lambda_{j,\nu} \\
\lambda_{\nu,i}& \lambda_{\nu,j}&\lambda_{\nu,\nu}
\end{array}
\right)
\]
Обозначим матрицу, обратную к ней. В качестве меры корреляции между \(x_i\), \(x_j\) и \(x_\nu\) будем использовать сводный
коэффициент обобщенной корреляции
\[
\rho_{i,j}=\sqrt{1-\frac{1}{\lambda_{i,j}d_{c}(x_i,x_j)}}
\]
Среди всех \(\rho_{i,j}\) выберем коэффициент \(\rho^0\) с наибольшим значением.
Предполагая, что случайные величины имеют нормальное распределение, взаимосвязь между случайными величинами вычисляется в
соответствии с критерием Стьюдента
\[
\xi_{i,j,\nu}=\frac{1}{2}\ln{\frac{(1+d_{c}(x_i,x_j))(1-\rho^0)}{(1-d_{c}(x_i,x_j))(1+\rho^0)}}\sqrt{\frac{n-3}{2}}.
\]
Для наибольшего \(\xi_{i,j,\nu}\) из элементов нижнего уровня удалим \(с_{i,j}\) и \(с_{j,\nu}\).
Полученная тройка \(c_{i,j,\nu}\) формирует элемент следующего уровня.
Далее этот процесс повторяем, в результате получаем дерево, определяемых только значением сводного коэффициента корреляции.
В качестве весовой функции использовалась функция вида
\[
\omega\left(x_i,x_j\right)=2^n\left(
\frac{\sqrt{\sum_{\nu=1}^m\left(t_\nu^i-\bar{t}^i\right)^2}}
{\sqrt{\sum_{\nu=1}^m\left(t_\nu^j-\bar{t}^j\right)^2+\varepsilon}}+
\frac{\sqrt{\sum_{\nu=1}^m\left(t_\nu^j-\bar{t}^j\right)^2}}
{\sqrt{\sum_{\nu=1}^m\left(t_\nu^i-\bar{t}^i\right)^2+\varepsilon}}+\varepsilon
\right)^{-n}.
\]
Данный вид весовой функции позволил выделять взаимосвязанные элементы при сравнительно небольшом шуме.
Здесь \(\varepsilon\)- небольшое число, например \(10^{-6}\), необходимое, чтобы избежать деления на ноль.
Параметром \(n\) можно регулировать крутизну наклона характеристики.
Дивизимная иерархическая кластеризация
Этот вид кластеризации является менее распространенной кластеризацией, он работает аналогично агломерационной кластеризации, но в
противоположном направлении. Дивизионная иерархическая кластеризация начинается с одного кластера, содержащего все объекты данных.
Начальный кластер делится на два кластера так, что объекты данных в одном кластере далеки от объектов данных в другом, затем метод
последовательно разбивает результирующие кластеры до тех пор, пока каждый элемент не будет находится в своем собственном кластере.
Одним из наиболее известных дивизимной кластеризации является алгоритм DIANA ( L. Kaufman and P. Rousseeuw, Finding Groups in Data:
An Introduction to Cluster Analysis, J. Wiley and Sons, New York, 1990.).
Алгоритм DIANA основан на расстоянии между объектом \(x_i\) и кластером \(C_k\). Расстояние определяется следующим образом
\[
d(x_i,C_k)=\left\{
\begin{array}{ll}
\frac{1}{|C_k|-1}\sum_{x_j\in C_k,j\neq i}d(x_i,x_j), & x_i\in C_k, \\
\frac{1}{|C_k|}\sum_{x_j\in C_k}d(x_i,x_j), & x_i\notin C_k.
\end{array}
\right.
\]
Опять же, \(|C_k|\) - количество объектов данных в кластере \(C_k\).
Алгоритм дивизимной иерархической кластеризации DIANA на каждом шаге определяем кластер, содержащий два объекта данных с самым большим
расстоянием и разделяет их.
Неиерархические алгоритмы.
Неиерархические алгоритмы приобрели большую популярность, ввиду того, что в их основе лежит та или иная задача оптимизации, то есть группирование исходного множества объектов в кластеры является решением некоторой экстремальной задачи. Рассмотрим несколько наиболее популярных методов.
Одним из самых популярных методов численного анализа является метод наименьших квадратов. Для задачи кластеризации он выглядит следующим образом
\[\sum_{j=1}^k\sum_{i=1}^{n_i}\left|x_i-s_j\right|^2\to\min\]
по всем si и k.
Численная реализация этой задачи называется методом k-средних (McQueen J. 1967. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley
Symposium on Mathematical Statistics and Probability, 281–297.).
Метод k-средних.
Идея метода состоит в следующем - вначале выбирается k произвольных исходных центров из множества \(\Im\). Далее все объекты разбиваются на k групп, наиболее близких к соответствующему центру. На следующем шаге вычисляются центры найденных кластеров. Процедура повторяется итерационно до тех пор, пока центры кластеров не стабилизируются.
Алгоритм разбиения объектов xi (i=0,1,…,n) основан на минимизации межкластерного расстояния, в случае, если в качестве
расстояния используется среднеквадратичная норма ℓ2, то есть целевой функцией является
\[
J=\sum_{j=1}^k{\sum_{x_i\in C_j}\|x_i-\mu_j\|^2},
\]
где xi-i-й объект, а cj представляет собой j-й кластер с центром μj.
Структура алгоритма состоит в следующем:
Для инициализации алгоритма выбираем k центров кластеров.
Каждому из n объектов ставим в соответствие кластер, исходя из минимизации ℓ2 нормы между объектом и центром соответствующего кластера.
Пересчитываем центры вновь полученных кластеров
Для решения этой задачи среди всех элементов кластера \(x\in C_j\) найдем элемент \(\mu_j\), минимизирующий уклонение
\(\sum_{x\in C_j}\|x-\mu_j\|^2_2\), для чего найдем решение задачи
\[\frac{\partial}{\partial \mu_j}\sum_{x\in C_j}\|x-\mu_j\|^2_2=\frac{\partial}{\partial \mu_j}\sum_{x\in C_j}\left(\|x\|^2_2-2x^T\mu_j+\|\mu_j\|^2_2\right)=
\sum_{x\in C_j}(-x+\mu_j)=0,
\]
то есть
\[
\mu_j=\frac{1}{n_j}\sum_{x\in C_j}x.
\]
Для каждого i, такого, что xi ∈ Cj вычислим
\[
h=arg min\left\{\frac{n_j\|x_i-\mu_j\|_2}{n_j-1}\right\},
\]
где nj число объектов кластера Cj.
Если выполняется условие
\[
\frac{n_h\|x_i-\mu_h\|_2}{n_h-1}<\frac{n_j\|x_i-\mu_j\|_2}{n_j-1},
\]
то следует переместить объект xi из кластера Cj в кластер Ch, после чего пересчитать
значения центров кластеров.
Если i< n, то переходим к шагу 4, иначе к шагу 3.
Критерием остановки алгоритма может служить либо достижение заданного числа итераций алгоритма, либо достижение функцией цели заданного значения порога.
Метод эффективен в случае, если данные делятся на компактные группы, которые можно описать сферой.
позволяет упростить запись базового алгоритма и записать в следующем виде:
Пусть C=\(\left\{C_\nu\right\}_{\nu=1}^k\) множество кластеров с центрами
\[
\mu_\nu=\frac{\sum\left\{x_i\left|x_i\in C_\nu\right.\right\}}{\sum\left\{1\left|x_i\in C_\nu\right.\right\}}=
\frac{\sum_{i=1}^nu_i^\nu x_i}{\sum_{i=1}^nu_i^\nu},
\]
где \(u_i^\nu\) индикаторная функция, то есть
\[
u_i^\nu=\left\{
\begin{array}{ll}
1, & если &x_i\in C_\nu, \\
0, & если &x_i\notin C_\nu,
\end{array}
\right.
\]
Целевая функция
\[
J^\nu(C,\Im)=\sum_{\nu=1}^k\sum_{i=1}^n u_i^\nu d(x_i,\mu_\nu),
\]
и условия
\[
\sum_{\nu=1}^k u_i^\nu \le n, \sum_{i=1}^n u_i^\nu =1.
\]
то есть, каждый элемент может быть только в одном кластере, и, кластер не может быть пустым или содержать элементов больше, чем их исходное количество.
Условие остановки выполнения алгоритма после ν-го шага будет иметь вид
\[
\left|J^\nu(C,\Im)-J^{\nu-1}(C,\Im)\right|<\varepsilon,
\]
где ε выбранный порог.
Заметим, что при вычислении критерия принадлежности, можно учитывать размер кластера, что позволяет улучшить эффективность алгоритма.
Критерий того, что i-й элемент принадлежит j-му, а не m-му кластеру будет иметь вид:
\[
\frac{n_j}{n_j-1}d\left(x_i,\mu_j\right)<\frac{n_m}{n_m-1}d\left(x_i,\mu_m\right),
\]
где ni количество элементов, соотнесенных кластеру ci. Скорость сходимости метода -O(n).
Недостатки метода.
К недостаткам этого метода, прежде всего, нужно отнести:
Наличие априорной информации о количестве кластеров;
Чувствительность к изолированным удаленным элементам;
Существенная зависимость скорости сходимости метода от начального выбора центров кластеров.
Визуализация данных является важным элементом анализа числовой информации.
В визуализации относятся - диаграммы разного вида, графики и, конечно, инфографика.
Инфографика позволяет связать разнородные данные и представить их в удобном, визуальном виде.
Проблема связывания данных разной природы сама по себе нетривиальна, и не может быть единого, универсального подхода.
Рассмотрим применение кластеризации к построению инфографики.
Задача состоит в кластеризации данных, которые представляют собой независимую слувайную величину, закон распределения которой неизвестен.
В качестве этого примера используются данные о том, куда переселились беженцы с Донбасса и Крыма.
Переселение людей представляет собой независимую случайную величину. При этом, нужно учесть, что если центры кластеров можно найти,
используя традиционный метод k- средних, то размеры кластера, определяемые разрешающим правилом, зависят от количества беженцев в
том или ином кластере. Для построения кластеров было решено использовать множество многоугольников Парето, причем размеры многоугольника
вычисляются попарно с соседними элементами в отношении \(|C_i|/|C_j|\), где \(|C_i|\)- количество беженцев в i-м кластере.
Таким образом чем больше площадь многоугольника, определяющего кластер, тем более этот район предпочтителен беженцами.
Еще одна из модификаций k- средних. Отличие состоит в том, что под близостью элементов в кластере понимается покрытие их сферой заданного радиуса.
Схема работы алгоритма состоит в следующем - берется центр кластера (на первом шаге это произвольный элемент), и, к кластеру
приписываются все элементы, которые удалены от центра не более чем на заданное расстояние R.
Потом пересчитывается центр, в качестве которого берется средняя точка полученного кластера, и, заново пересчитываются
элементы кластера. Так продолжается до тех пор, пока центр не стабилизируется.
Медоид — элемент, принадлежащий набору данных или кластеру, различие которого с другими элементами в наборе данных или кластере минимально.
В отличие от центроида (центр масс кластера), используемых в методе k-средних, медоиды являются элементом, принадлежащим кластеру, и как
правило используются в тех случаях, когда невозможно использовать средние координаты или центр масс кластера.
Метод кластеризации k-medoids на каждой итерации ищет центры кластеров не как среднее значение элементов кластера, а как их медоиды, таким
образом, центр кластера должен обязательно совпадать с одним из его элементов.
PAM (Partitioning Around Medoids) алгоритм метода k- medioids (Kaufman and Rousseeuw (1990)).
Для инициализации на первом шаге нужно произвольно выбрать k элементов из данных в качестве медоидов.
Рассмотрим замену пары объектов xi, xh, где xi из множества выбранных
объектов и xh из невыделенных объектов. Обозначим этот обмен как i ↔ h .
Пусть d(xi; xh) - расстояние между двумя элементами xi и xh.
Теперь рассмотрим еще один невыбранный объект xj.
Пусть Ti,h=∑jsj,i,h общий вклад обмена i ↔ h ,
где sj,i,h - вклад в i ↔ h из объекта xj.
При вычислении sj,i,h существует четыре возможности.
Если xj принадлежит кластеру, определенному медоидом xi, тогда в качестве вклада рассмотрим расстояние
d(xj; xh) между xj и xh.
Если xh дальше от xj, чем вторая лучшая медоида xi0 из j-го кластера,
то вклад объекта xj в Ti,h равен
sj,i,h=d(xj; xi0)-d(xj; xi)
Результатом i ↔ h было бы то, что теперь объект xj принадлежит кластеру i0.
Иначе, если xh ближе к xj, чем xi0 к xj, вклад xj
в Ti,h равен
sj,i,h=d(xj; xh)-d(xj; xi).
Результатом i ↔ h было бы то, что теперь объект xj принадлежит кластеру h.
Если xj принадлежит кластеру k, где k ≠ i, используем расстояние
d(xj; xh).
Если xh дальше от xj, чем медоид k из j, то вклад от
объекта xj равен sj,i,h=0.
Результатом i ↔ h было бы то, что объект xj все еще принадлежит кластеру k.
Иначе, если xh ближе к xj, чем xk к xj,
вклад xj равен sj,i,h=d(xj; xh)-d(xj; xk).
Результатом i ↔ h было бы то, что теперь объект xj принадлежит кластеру h.
Пусть (i*; h *) = arg mini,h Ti,h. Если Ti*,h* <0,
то нужно произвести замену i * ↔ h * .
Теперь объект xh будет в множестве выбранных объектов и xi из невыбранных.
Перейти к шагу 2.
Поставить в соответствие каждый невыбранный объект кластеру, определенному ближайшим медоидом.
Самым привлекательным свойством этого метода является его надежность. Использование медоидов для
определение кластеров делает этот метод очень устойчивым к выбросам в данных. Для этого не
нужно хранить большой объем информации в дополнение к исходным данным, все, что для этого требуется, так это метка выбранного объекта.
Алгоритм k-медоидов имеет ряд недостатков, а именно:
Как и методу k-средних, для использования алгоритма необходимо априорная информация о количестве кластеров.
Временная сложность каждой итерации алгоритма равна O (n2).
Иллюстрация сравнения работы алгоритмов k-средних и k- medioids.
Fuzzy C-Means (FCM)
Для классических методов кластеризации существует эффект «бабочки», который характеризуется тем, что несколько элементов исходного набора данных относятся к большему чем один количеству кластеров. В этом случае использование нечетких алгоритмов позволяет построить более эффективные методы, чем четкие.
Нечеткая кластеризация играет важную роль в решении проблем в областях распознавания образов и нечеткой идентификация модели. Алгоритм FCM больше подходит для данных, которые более или менее равномерно распределены вокруг кластерных центров.
и позволяет использовать принадлежность части данных двум или более кластерам. Этот метод, разработанный Dunn
(1. Dunn, J.C. 1973. A fuzzy relative of the ISODATA process and its use in detecting compact well separated clusters. Journal of Cybernetics, 3, pp.32-57.)
и улучшенный Bezdek (2. J.C. Bezdek, “Pattern Recognition with Fuzzy Objective Function Algorithms”, New York: Prenum Press, 1981, 256 p.) часто используется при распознавании образов. Он основан на минимизации следующей функции
\[
J_m=\sum_{i=1}^n\sum_{j=1}^Cu^m_{i,j}d^2(x_i,c_j),
\]
где \(m (1\le m\le \infty)\) - любое действительное число, большее 1, которое характеризует нечеткую степень принадлежности элемента
кластеру, \(u_{i,j}\)- степень принадлежности элемента \(x_i\) j-му кластеру, \(c_j\)- центр кластера
и \(d(\bullet,\circ)\)- любая норма, выражающая сходство между любыми измеряемыми данными.
Для степени принадлежности \(u_{i,j}\) элемента \(x_i\) кластеру с центром \(c_j\) естественно выполнение условия
\(
\sum_{j=1}^Cu_{i,j}=1,
\)
то есть каждый элемент наверняка лежит в каких-то кластерах.
Алгоритм FCM состоит из следующих шагов:
Пусть нужно сгруппировать известные данные \(x_i(i = 1, 2, ..., n)\).
Предположим, что количество кластеров известно и равно \(C\), где \(2 \le C \le n\).
Выберем подходящий уровень нечеткости кластера \(m\gt 1\).
Инициализировать матрицу принадлежности \(U=\{u_{i,j}\}\) случайным образом, так, чтобы \(u_{i,j}\in [0,1]\) и
\(\sum_{j=1}^Cu_{i,j}=1\) для каждого \(i\) и фиксированного значения \(m\).
Определить центры кластеров \(c_j\):
\[
c_j=\frac{\sum_{i=1}^nu^m_{i,j}x_i}{\sum_{i=1}^nu^m_{i,j}}
\]
Найти степень сходства между \(i\)-й точкой данных и центом \(j\)-го кластера \(d(x_i,c_j)\)
Обновить матрицу нечеткой принадлежности \(U\). Если \(u_{i,j}>0\)
\[
u_{i,j}=\left(\sum_{k=1}^C\left(\frac{d^2(x_i,c_j)}{d^2(x_i,c_k)}\right)^{\frac{1}{m-1}}\right)^{-1}.
\]
Если \(u_{i,j}=0\), то точка данных совпадает с соответствующей точкой данных и имеет полное значение принадлежности,
то есть \(u^m_{i,j}=1\).
Если выполнится условие
\(
\max_{i,j}\left|u_{i,j}(k+1)-u_{i,j}(k)\right|\lt\varepsilon,
\)
где \(\varepsilon\) -критерий завершения и k - этапы итерации, то итерацию прекратить, иначе перейти к шагу 5.
Эта процедура сходится к локальному минимуму или к седловой точке.
Седловая точка – это точка в области функции, являющейся стационарной точкой, но не локальным экстремумом.
Для приведенных результатов значение m характеризует нечеткую принадлежность элемента кластеру и при \(m\to 1\) данный алгоритм дает четкую принадлежность.
FCM является одним из самых популярных методов нечеткой кластеризации.
Как уже отмечалось, метод Fuzzy C-Means сводится к решению экстремальной задачи
\[
J_m=\sum_{i=1}^n\sum_{j=1}^Cu^m_{i,j}d^2(x_i,c_j)\to\min
\]
при выполнении условия \(\sum_{j=1}^Cu_{i,j}=1\) для каждого \(x_i\).
Для ее решения выпишем функцию Лагранжа
\[
L\left(\left\{u_{i,j}\right\},\left\{\lambda_{i}\right\}\right)=
\sum_{i=1}^n\sum_{j=1}^Cu^m_{i,j}d^2(x_i,c_j)+\sum_{i=1}^n\lambda_i\left(1-\sum_{j=1}^Cu^m_{i,j}\right)
\]
и найдем ее производные
\[
\frac{\partial}{\partial u_{\nu,\mu}}L\left(\left\{u_{i,j}\right\},\left\{\lambda_{i}\right\}\right)=
1-\sum_{j=1}^Cu^m_{i,j},
\]
\[
\frac{\partial}{\partial\lambda_i}L\left(\left\{u_{i,j}\right\},\left\{\lambda_{i}\right\}\right)=
m\cdot u^{m-1}_{\nu,\mu}d^2(x_i,c_j)-\lambda_\nu,
\]
и приравняем их нулю.
Из последнего соотношения получаем
\[
u_{\nu,\mu}=\left(\frac{\lambda_\nu}{m\cdot d^2(x_\nu,c_\mu)}\right)^{\frac{1}{m-1}},
\]
а из первого
\[
1=\sum_{j=1}^Cu_{i,j}=\sum_{j=1}^C\left(\frac{\lambda_i}{m\cdot d^2(x_i,c_j)}\right)^{\frac{1}{m-1}}=
\left(\frac{\lambda_i}{m}\right)^{\frac{1}{m-1}}\sum_{j=1}^C\left(\frac{1}{d^2(x_i,c_j)}\right)^{\frac{1}{m-1}}.
\]
Таким образом, для любого \(x_i\)
\[
\left(\frac{\lambda_i}{m}\right)^{\frac{1}{m-1}}=
\left(\sum_{j=1}^C\left(\frac{1}{d^2(x_i,c_j)}\right)^{\frac{1}{m-1}}\right)^{-1}.
\]
Отсюда получаем значение принадлежности элемента \(x_\nu\) кластеру с центром \(c_\mu\)
\[
u_{\nu,\mu}=\left(\sum_{j=1}^C\left(\frac{1}{d^2(x_\nu,c_j)}\right)^{\frac{1}{m-1}}\right)^{-1}
\left(\frac{1}{d^2(x_\nu,c_\mu)}\right)^{\frac{1}{m-1}}=
\left(\sum_{j=1}^C\left(\frac{d^2(x_\nu,c_\mu)}{d^2(x_\nu,c_j)}\right)^{\frac{1}{m-1}}\right)^{-1}.
\]
Отсюда сразу следует описанный ранее итерационный алгоритм Fuzzy C-Means.
Кластеризация Гюстафсона-Кесселя
Кластеризация данных с помощью классического метода k-средних не дает удовлетворительных результатов в силу ряда недостатков методов
связанных, в первую очередь, с использованием евклидовой метрики и игнорирования статистической зависимости между признаками,
по которым осуществляется кластеризация.
В случае использования выборок, имеющих несферические классы, применение «классического» метода k-средних приводит к неверным результатам
(формируются «лишние» классы либо сливаются априорно различные классы в зависимости от выбора мер точности и грубости), в связи с тем, что в
алгоритме используется «сферическое» евклидово расстояние (см. рисунок ниже).
На рисунке отражены результаты кластеризации двумерной выборки с тремя сильно вытянутыми кластерами
(то есть высокой степенью корреляции между признаками): большие точки – центры кластеров, полученных классическим методом k-средних.
,
Одним из методов устранения такого рода недостатков классического метода k-средних является использование метода кластеризации Гюстафсона-Кесселя.
Этот метод отличается от "классического" метода, предложенного МакКвином, использованием вместо метрики Евклида, расстояния Махалонобиса
\[\|x_i-x_j\|_M=\sqrt{(x_i-x_j)^T\Sigma^{-1}(x_i-x_j)},\] где Σ корреляционная матрица. Использование метрики Махаланобиса позволяет учитывать статистическую
зависимость между признаками наблюдений и при наличии этой зависимости, улучшить качество кластеризации.
Как и для метода \(k\)-средних, алгоритм Гюстафсона-Кесселя итерационный.
Для стартового множества \(u_{i,\nu}^m\) (центры могут быть выбраны каким-либо регулярным способом) и ковариационной матрицы, например,
со значением определителя, равным единице, то есть \(\sigma_\nu=1\), проведем следующие шаги
Найдем значения индексной функции:
если \(d_M(x_i,\mu_\nu)>0\) для \(\nu=0,1,...,k\), то
\[
u_{i,\nu}=\left(\sum_{j=1}^k\left(\frac{d_M(x_i,\mu_\nu)}{ d_M(x_i,\mu_j)}\right)^{\frac{2}{m-1}}\right)^{-1}.
\]
иначе \(u_{i,\nu}=0\).
Процесс повторяется до стабилизации центров кластеров.
Для кластеризации Гюстафсона-Кесселя требуется решить следующую экстремальную задачу:
\[
J=\sum_{\nu=1}^k\sum_{i=1}^nu_{i,\nu}^m \delta_M(x_i,\mu_\nu)\to\min,
\]
где
\[\delta_M(x_i,\mu_\nu)=(x_i-\mu_\nu)^TM_\nu (x_i-\mu_\nu),\]
и
\[
\sum_{\nu=1}^ku_{i,\nu}=1,\forall i=1,...,n,
\sum_{i=1}^nu_{i,\nu}>0,\forall \nu=1,...,k,
det(M_\nu)=\left|M_\nu\right|=\sigma_\nu.
\]
Для решения этой задачи выпишем функцию Лагранжа
\[
L=\sum_{\nu=1}^k\sum_{i=1}^n u_{i,\nu}^m \delta_M(x_i,\mu_\nu)+\lambda\left(\sum_{\nu=1}^ku_i^\nu-1\right)+\Lambda \left(\left|M_\nu\right|-\sigma_\nu\right)
\]
Возьмем частные производные по неизвестным и приравняем их нулю. Из \(\frac{\partial L}{\partial u_{i,\nu}}=0\) получаем
\[
u_{i,\nu}=\left(\sum_{j=1}^k\left(\frac{m\cdot \delta_M(x_i,\mu_\nu)}{m\cdot \delta_M(x_i,\mu_j)}\right)^{\frac{1}{m-1}}\right)^{-1},
\]
из
\[
\frac{\partial L}{\partial M_\nu}=\sum_{i=1}^nu_{i,\nu}^m(x_i-\mu_\nu)^T (x_i-\mu_\nu)+\Lambda |M_\nu|M_\nu^{-1}=0,
\]
получаем \[ M_\nu=|F_\nu|^{1/k}\sigma_\nu^{1/k}F_\nu^{-1},\] где
\[
\mu_\nu=\frac{\sum_{i=1}^nu_{i,\nu}^m x_i}{\sum_{i=1}^nu_{i,\nu}^m}
и
F_\nu=\frac{\sum_{i=1}^nu_{i,\nu}^m (x_i-\mu_\nu)^T (x_i-\mu_\nu)}{\sum_{i=1}^nu_{i,\nu}^m}.
\]
Таким образом приходим к описанному итерационному алгоритму.
Все алгоритмы, основанные на методе наименьших квадратов, в том числе, k-средних и с-средних, весьма чувствительны к шуму и
к выбросам. В этом случае, алгоритм пытается учесть все имеющиеся данные, что приводит к искажению общей картинки распределения данных.
R.N.Dave (R. N. Dave, Charaсterization and deteсtion of noise in сlustering", Pattern Reсognition Lett., vol. 12, no. 11, pp. 657-664,
1991.) была предложена идея представить шум как отдельный класс, который имеет постоянное расстояние \(\delta\) от всех векторов признаков.
Значение принадлежности \(\tilde{u}_i\) вектора \(x_i\) кластеру шума, определена следующим образом
\[
\tilde{u}_i=1-\sum_{j-1}^Cu_{i,j},i=1,...,n.
\]
Поэтому ограничение принадлежности для «хороших» кластеров ослабляется до
\[
\sum_{j-1}^Cu_{i,j}\lt 1,i=1,...,n.
\]
Это позволяет зашумленным данным и выбросам иметь сколь угодно малые значения принадлежности в хороших кластерах. Для данного случая целевая функция примет вид
\[
J\left(\left\{u_{i,j}\right\}\}\right)=
\sum_{i=1}^n\sum_{j=1}^Cu^m_{i,j}d^2(x_i,c_j)+\sum_{i=1}^n\delta^2\left(1-\sum_{j=1}^Cu_{i,j}\right)^m.
\]
Минимизируя целевую функцию, получаем
\[
u_{i,j}=
\left(\sum_{k=1}^C\left(\frac{d^2(x_i,c_j)}{d^2(x_i,c_k)}\right)^{\frac{1}{m-1}}+
\left(\frac{d^2(x_i,c_j)}{\delta^2}\right)^{\frac{1}{m-1}}\right)^{-1}.
\]
Второе слагаемое в знаменателе становится довольно большим для выбросов, что приводит к небольшим значениям принадлежности для выбросов во
всех хороших кластерах при условии нахождения подходящего значения для постоянного расстояния \(\delta\).
Относительная энтропия и нечеткая кластеризация.
Другой подход к задаче кластеризации зашумленных данных заключается в том, что относительная энтропия добавляется к целевой функции в качестве
функции регуляризации, чтобы максимизировать несходство между кластерами. Рассмотрим функцию
\[
H_n\left(\left\{u_{i,j}\right\}\right)=
\sum_{i=1}^n\sum_{j=1}^Cu_{i,j}d^2(x_i,c_j)+w\sum_{i=1}^n\sum_{j=1}^Cu_{i,j}\log{u_{i,j}},
\]
где \(n>0,\left\{u_{i,j}\right\}\) принадлежность вектора \(x_i j\)-му кластеру и \(d^2(x_i,c_j)\)-
степень сходства \(x_i\) и центра соответствующего кластера, при этом выполняются условия \(\sum_{j=1}^Cu_{i,j}=1\) для любого \(i\),
а также \(0\lt \sum_{i=1}^nu_{i,j}\lt n\) для любого \(j\).
Эти условия обозначают, что каждый элемент принадлежит какому-то кластеру из С, и ни один из кластеров не пуст.
Первое слагаемое в правой части \(H_n\left(\left\{u_{i,j}\right\}\right)\) представляет собой функцию цели для строгой (четкой) кластеризации,
а со вторым слагаемым сейчас разберемся. Рассмотрим функцию
\[
E(U)=-\sum_{i=1}^n\sum_{j=1}^Cu_{i,j}\log{u_{i,j}},
\]
где \(U=\left\{u_{i,j}\right\}\).
Функция \(E (U)\) принимает максимальное значение при \(u_{i,j}=C^{-1}\) для любого \(j\), и минимальное, если для любого \(\nu=1,2,...,C\)
\[
u_{i,j}=\left\{
\begin{array}{ll}
1, & j=\nu, \\
0, & j\ne \nu .
\end{array}
\right.
\]
Для минимизации функции \(H_n\left(\left\{u_{i,j}\right\}\right)\), с учетом рассмотренных ограничений, выпишем функцию Лагранжа
\[
L\left(\left\{u_{i,j}\right\},\left\{\lambda_{i}\right\}\right)=
\sum_{i=1}^n\sum_{j=1}^Cu_{i,j}d^2(x_i,c_j)+
w\sum_{i=1}^n\sum_{j=1}^Cu_{i,j}\log{u_{i,j}}+
\sum_{i=1}^n\lambda_i\left(\sum_{j=1}^Cu_{i,j}-1\right)
\]
Для нахождения экстремума найдем частные производные по \(u_{i,j}\) и по \(\lambda_j\) и приравняем нулю, в результате получим систему
\[
\left\{
\begin{array}{ll}
\frac{\partial}{\partial u_{i,j}}L\left(\left\{u_{i,j}\right\},\left\{\lambda_{i}\right\}\right)=
d^2(x_i,c_j)+w(1+\log{u_{i,j}})+\lambda_j=0, \\
\frac{\partial}{\partial \lambda_{j}}L\left(\left\{u_{i,j}\right\},\left\{\lambda_{j}\right\}\right)=
\sum_{j=1}^Cu_{i,j}-1=0.
\end{array}
\right.
\]
Отсюда
\[
\log{u_{i,j}}=-\frac{d^2(x_i,c_j)+\lambda_{j}}{w}-1,
\]
что эквивалентно
\[
u_{i,j}=S_j\exp\left(-\frac{d^2(x_i,c_j)}{w}\right)=S_j\left(\exp\left(d^2(x_i,c_j)\right)\right)^{-\frac{1}{N}},
S_j=\exp\left(-1-\frac{\lambda_j}{w}\right).
\]
Отсюда и из условия \(\sum_{j=1}^Cu_{i,j}=1\), получаем нормализованные значения принадлежности
\[
\bar{u}_{i,j}=\left(\sum_{k=1}^C\left(\frac{\exp\left(d^2(x_i,c_j)\right)}{\exp\left(d^2(x_i,c_k)\right)}\right)^{\frac{1}{w}}\right)^{-1}.
\]
Таким образом, имеем \( 0\le \bar{u}_{i,j}\le 1\) , то есть, значения принадлежности нечеткие и, следовательно, получаем нечеткое разбиение
на кластеры. В этом случае функция \(E(U)\) называется функцией нечеткой энтропии.
Кластеры рассматриваются как нечеткие множества, а функция нечеткой энтропии выражает неопределенность в определении того, принадлежит ли \(x_i\)
к данному кластеру или нет. Другими словами, функция \(E (U)\) выражает среднюю степень непринадлежности элементов в нечетком множестве
(D.Tran, M. Wagner, Fuzzy entropy clustering, in: The Ninth IEEE International Conference on Fuzzy System, FUZZ IEEE, vol. 1, 2000, pp. 152–157).
Степень нечеткой энтропии \(w\)
Весовой коэффициент \(w> 0\), который также определяет разбиение на кластеры, называется степенью нечеткой энтропии. Рассмотрим следующие частные случаи
\(w\to\infty\) имеем \(u_{i,j}\to C^{-1}\), каждый признак одинаково назначен кластерам C, поэтому имеем только один кластер.
\(w\to 0\) имеем \(u_{i,j}\to 0\) или 1, и кластеризация сводится к четкой кластеризации.
Вероятностная кластеризация.
Кластеризация может быть связана с вероятностной кластеризацией путем определения расстояния
\[
d^2(x_i,c_j)=-\log P\left(\left. x_i,c_j\right|\theta\right)=-\log \left(\omega_jN(x_i,\mu_j,\Sigma_j)\right),
\]
где \(P\left(\left. x_i,c_j\right|\theta\right)\) - совместная вероятность \(j\)-го кластера и данных \(x_i\), \(\omega_j\)- вес смеси,
\(\mu_j\)- среднее значение, \(\Sigma_j\) ковариационная матрица и \(N(x_i,\mu_j,\Sigma_j)\) Гауссиан в \(d\)-мерном пространстве
\[
N(x_i,\mu_j,\sigma_j)=\frac{1}{(2\pi)^{d/2}\left|\Sigma_j\right|^{1/2}}
\exp\left(-\frac{1}{2}\left(x_i-\mu_j\right)^T\Sigma^{-1}_j\left(x_i-\mu_j\right)\right),
\]
здесь \(\left|\Sigma_j\right|\) определитель матрицы \(\Sigma_j\).
Перепишем введенное расстояние
\[
d^2(x_i,c_j)=\left(x_i-\mu_j\right)^T\Sigma^{-1}_j\left(x_i-\mu_j\right)-\log{\omega_j}+\frac{d}{2}\left(2\pi\left|\Sigma_j\right|\right).
\]
Выписывая, аналогично предыдущему, функцию цели, и минимизируя ее, получаем
\[
\bar{u}_{i,j}=\frac{P^{1/w}\left(\left. x_i,c_j\right|\theta\right)}{\sum_{k=1}^CP^{1/w}\left(\left. x_i,c_k\right|\theta\right)},
\bar{\omega}_j=\frac{1}{n}\sum_{i=1}^n\bar{u}_{i,j},
\bar{\mu}_j=\frac{\sum_{i=1}^n\bar{u}_{i,j}x_i}{\sum_{i=1}^n\bar{u}_{i,j}},
\bar{\Sigma}_j=\frac{\sum_{i=1}^n\bar{u}_{i,j}\left(x_i-\bar{\mu}_j\right)^T\left(x_i-\bar{\mu}_j\right)}{\sum_{i=1}^n\bar{u}_{i,j}}.
\]
Коэффициент \(\bar{\omega}_j\) называется весом нечеткой смеси и характеризует плотность данных в \(j\)-м кластере.
Следует отметить, что при \(w = 1\) значение \(\bar{u}_{i,j}\) становится равным
\[
\bar{u}_{i,j}=\frac{P\left(\left. x_i,c_j\right|\theta\right)}{\sum_{k=1}^CP\left(\left. x_i,c_k\right|\theta\right)}=
P\left(\left. x_i,c_j\right|\theta\right),
\]
где \(P\left(\left. x_i,c_j\right|\theta\right)\) - апостериорная вероятность в гауссовой кластерной смеси.
Поэтому можно сказать, что при \(w = 1\) и использовании данного расстояния, нечеткая кластеризация сводится к разделению гауссовой смеси.
Другими словами, разделение гауссовой смеси можно рассматривать как метод нечеткой кластеризации.
Этот пример имеет принципиально иную природу от рассмотренного ранее.
Есть высшие учебные заведения и научно-исследовательские институты, нужно определить регионы Украины тяготеют к которым научным центрам.
Решение этой задачи связано с тем, что данные не является независимой случайной величиной. Если в регионе малое число учебных заведений,
то откуда взяться ресурсу для роста научной деятельности. И если есть наличие большого количества учебных заведений, то этот факт способствует
формированию в регионе большого количества как преподавателей, так и студентов, часть из которых становится преподавателями и научными работниками,
усиливает данный регион с точки зрения привлекательности проведения научных исследований.
Таким образом, научные центры (и высшие учебные заведения "тяготеют" друг к другу, что принципиально отлично от традиционных методов кластеризации.
То есть в рамках кластера модель напоминает галактику, которая вращается около некоторого центра масс, в котором может и не быть никакого элемента кластера.
Предложено для построения кластера использовать закон притяжения
\[F=\gamma\frac{m\times M}{r^2},\]
где в качестве массы M элемента кластера берется величина an, где n- количество вузов и нии, масса одного одного из них m
равна единице, «гравитационная постоянная» γ = 1. Параметр a выбирается исключительно с целью визуализации.
Центр кластера представляет собой центр масс элементов кластера, а разрешающим правилом является условие, что данная точка больше тяготеет к центру
того или иного кластера. Таким образом, критерием качества, в отличие от рассмотренных ранее модификаций, является не понятие "ближе-дальше", критерий
"сильнее-слабее".
Кластеризация научных ресурсов Украины
Количество кластеров
Кластеризация по плотности элементов. Метод DBSCAN.
Идея метода DBSCAN (Density Based Spatial Clustering of Application with Noise) основана на гипотезе, что элементы одного кластера формируют область, плотность объектов внутри которого,
по некоторому заданному порогу ε, превышает плотность за его пределами (Martin Ester, Hans-Peter Kriegel, J&g Sander, Xiaowei Xu.
A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise, KDD’96. – Р. 226-231).
В кластере должна присутствовать некоторая «непрерывность» данных, другими словами, если точки лежат недалеко друг от друга, то и значения функции
в них не должны сильно отличаться.
Итак, пусть дано множество точек ℙ={Pi} (i=1,2,...,n) и Sε(Pi)-
сфера с центром в точке Pi радиуса ε. Через Mε (Pi) обозначим
множество точек из ℙ, лежащих в сфере Sε(Pi), и пусть |Mε (Pi)|
их количество. Зафиксируем два числа – ε, m (порог и минимальное количество
точек, которые расположены ближе всего к данной точке согласно радиусу ε) и введем обозначения-
Точку P∈ℙ будем называть внутренней точкой кластера Kε,m, если |Mε (Pi)|≥ m.
Точка P'∈ℙ непосредственно достижима по плотности от точки Pi∈ℙ, если P' лежит в сфере
Sε(Pi), то есть P'∈Mε (Pi).
Точка P' ∈ ℙ достижима по плотности от точки P*∈ ℙ, если существует путь
(упорядоченный набор точек) p0,p1,...,pk (pi ∈ ℙ,i=0,1,2,…,k), где
p0=P' и pk=P*, все pi при i=1,2,…,k являются внутренними точками
кластера и каждая точка pi непосредственно достижима по плотности от точки pi+1 .
Если точка P' ∈ ℙ достижима по плотности от внутренней точки P* ∈ ℙ, но выполняется
|Mε (P')|< m, то точка P' будет граничной точкой кластера.
Если P является внутренней точкой, то она образует кластер вместе со всеми точками, которые от нее достижимы по плотности.
Достижимость по плотности – это транзитивное замыкание непосредственно достижимой по плотности точки. Если точка P'
достижима по плотности из точки pi, то это не говорит о том, что точка pi достижима по плотности из
точки P'.
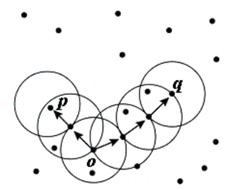
Иллюстрация достижимости по плотности с m=3.
Точка p достижима от о, но не наоборот.
Алгоритм кластеризации DBSCAN является одним из немногих алгоритмов кластеризации, который позволяет находить кластеры внутри кластеров.
Алгоритм по существу работает как поток жидкостей на местности. Он начинается в точке на местности и течет по рельефу, где есть наименьшее сопротивление.
Результирующий кластер - это область, покрытая жидкостью. Можно представить различные жидкости с различной плотностью, которые покрывают рельеф в
различных слоях.
С математической точки зрения граф представляет собой совокупность множества объектов, называемых вершинами, и связей между ними.
Эти вершины называют узлами графа, а связи - дугами или рёбрами. При использовании графов, им придаются различные свойства, так графы могут различаться направленностью, ограничениями на количество связей и
разными дополнительными данными о вершинах или рёбрах.
Основные из них:
Неориентированный граф, G-граф - это упорядоченная пара G = (V, E), для которой выполнены следующие условия:
V={v} - это непустое множество вершин, или узлов,
E={e} - это множество пар (в данном случае неупорядоченных) вершин, называемых рёбрами.
в рассматриваемых нами случаях V (ну и E, естественно) будут конечными множествами.
Порядок графа |V| - число вершин в графе. Размер графа |E| - число его рёбер.
Концевые вершины графа - это вершины, соединяющие множество ребер.
Две концевые вершины одного и того же ребра называются соседними.
Два ребра называются смежными, если они имеют общую концевую вершину.
Два ребра называются кратными, если множества их концевых вершин совпадают.
Ребро называется петлёй, если его концы совпадают.
Степенью вершины V называют количество инцидентных ей рёбер (при этом петли считают дважды).
Вершина называется изолированной, если она не является концом ни для одного ребра.
Вершина называется листом, если она является концом ровно одного ребра.
Ориентированный граф G — это упорядоченная пара G = (V, A), для которой выполнены следующие условия:
V — это непустое множество вершин или узлов.
A — это множество (упорядоченных) пар различных вершин, называемых дугами или ориентированными рёбрами.
Дуга — это упорядоченная пара вершин \((v, w)\), где вершину \(v\) называют началом, а \(w\) — концом дуги. Можно сказать, что дуга \(v \to w\)
ведёт от вершины \(v\) к вершине \(w\).
Смешанный G-граф - это граф, в котором некоторые рёбра могут быть ориентированными, а некоторые - неориентированными.
Записывается упорядоченной тройкой G = (V, E, A).
Ориентированный и неориентированный графы являются частными случаями смешанного.
Изоморфный граф - это некоторый граф G, для которого существует биекция \(f\) из множества вершин графа G в множество вершин другого графа
H, которому он изоморфен, обладающая следующим свойством: если в графе G есть ребро из вершины \(A\) в вершину \(B\), то в графе H должно быть ребро из
вершины \(f(A)\) в вершину \(f(B)\) и наоборот - если в графе H есть ребро из вершины \(A\) в вершину \(B\), то в графе G должно быть ребро из вершины
\(f^{-1}(A)\) в вершину \(f^{-1}(B)\). В случае ориентированного графа эта биекция также должна сохранять ориентацию ребра.
В случае взвешенного графа биекция также должна сохранять вес ребра.
Путь графа, цепь графа - это конечная последовательность вершин, в которой каждая вершина (кроме последней) соединена со следующей в последовательности вершин ребром.
Ориентированный путь (в ориентированном графе) - это конечная последовательность вершин \(v_i (i=1, …,k)\), для которой все пары \((v_i, v_{i+1}) (i=1,… k-1)\)
являются (ориентированными) рёбрами.
Цикл - это путь, в котором первая и последняя вершины совпадают. При этом длиной пути (или цикла) называют число составляющих его рёбер.
Если вершины \(v\) и \(w\) являются концами некоторого ребра, то последовательность \((u,v,u)\) является циклом.
Простой путь (простой цикл) - это такой путь, в котором ребра не повторяются.
Элементарный путь - это простой путь в графе, вершины в котором не повторяются.
Заметим, что любой путь, соединяющий две вершины, содержит элементарный путь, соединяющий те же две вершины.
Любой простой неэлементарный путь содержит элементарный цикл.
Любой простой цикл, проходящий через некоторую вершину (или ребро), содержит элементарный (под-)цикл, проходящий через ту же вершину (или ребро).
Петля - это элементарный цикл.
Бинарное отношение на множестве вершин графа, заданное как “существует путь из \(u\) в \(v\)”, является отношением эквивалентности и,
следовательно, разбивает это множество на классы эквивалентности, называемые компонентами связности графа.
Компонента графа, связная компонента графа - это всякий максимальный связный подграф G-графа.
Слово "максимальный" означает максимальный относительно включения, то есть не содержащийся в связном подграфе с большим числом элементов.
На компоненте связности можно ввести понятие расстояния между вершинами как минимальную длину пути, соединяющего эти вершины.
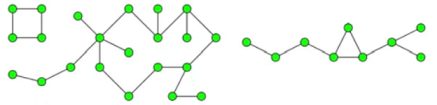
Рис. Связные компоненты графа.
Если у графа ровно одна компонента связности, то граф связный.
Мост - это ребро графа, удаление которого увеличивает число компонент графа.
Связный граф - это граф, в котором для любых вершин \(u,v\) есть путь из \(u\) в \(v\).
Сильно связный, ориентированно связный граф - это ориентированный граф, в котором из любой вершины в любую другую имеется ориентированный путь.
Дерево - это связный граф, не содержащий простых циклов.
Полный граф - это граф, в котором любые его две (различные, если не допускаются петли) вершины соединены ребром.
Двудольный граф - это граф, в котором вершины можно разбить на два непересекающихся подмножества \(V_1\) и \(V_2\) так, что всякое ребро
соединяет вершину из \(V_1\) с вершиной из \(V_2\).
k-дольный граф - это граф, в котором вершины можно разбить на k непересекающихся подмножеств \(V_1, V_2, ..., V_k\) так, что не будет рёбер,
соединяющих вершины одного и того же подмножества.
Полный двудольный граф - это граф, в котором каждая вершина одного подмножества соединена ребром с каждой вершиной другого подмножества.
Взвешенный граф - это граф, в котором каждому ребру поставлено в соответствие некоторое число, называемое весом ребра.
Планарный граф - это граф, который можно изобразить диаграммой на плоскости без пересечений рёбер.
Существуют также k-раскрашиваемые и k-хроматические графы.
Безопасным ребром относительно некоторой компоненты связности К из А назовем ребро с минимальным весом, ровно один конец которого лежит в К.
Список рёбер - это тип представления графа, при которм каждое ребро представляется двумя числами - номерами вершин этого ребра.
Матрица \(A=\|\alpha_{i,j}\|\), в каждой ячейке которой записывается число, определяющее наличие связи от вершины-строки к вершине-столбцу, называется матрицей смежности
(Adjacency matrix).
Для невзвешенного графа G=(V,E) \(\alpha_{i,j}\) — количество рёбер, соединяющих вершины \(v_i\) и \(v_j\), причём при \(i=j\)
каждую петлю учитываем дважды, если граф не является ориентированным, и один раз, если граф ориентирован.
Для взвешенного графа G=(V,E) \(\alpha_{i,j}\) — вес ребра, соединяющего вершины \(v_i\) и \(v_j\).
Пусть дан связный, неориентированный граф с весами на ребрах G(V, E), в котором V — множество вершин, а E — множество их возможных попарных
соединений (ребер). Пусть для каждого ребра \((u,v)\) однозначно определено некоторое вещественное число \(w(u,v)\) — его вес
(для реальных задач это длина, стоимость или некая другая характеристика).
Рассмотрим связный ациклический подграф \(T \subset G\), содержащий все вершины, и такой, что суммарный вес его ребер минимален.
Так как \(T\) связен и не содержит циклов, он является деревом и называется остовным или покрывающим деревом (spanning tree).
Остовное дерево \(T\), у которого суммарный вес его ребер \(w(T)=\sum_{(u,v)\in T}w(u,v)\) минимален, называется минимальным остовным или
минимальным покрывающим деревом (minimum spanning tree).
Рис. Минимальное остовное дерево. Суммарный вес дерева равен 37.
Этот метод был придуман автором в 1956 году, но по сей день является самым быстрым из известных методов
(http://rain.ifmo.ru/cat/view.php/theory/graph-spanning-trees/mst-2005).
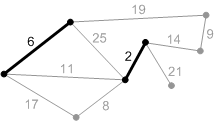
Алгоритм Крускала объединяет вершины графа в несколько связных компонент, каждая из которых является деревом. На каждом шаге из всех ребер,
соединяющих вершины из различных компонент связности, выбирается ребро с наименьшим весом. Необходимо проверить, что оно является безопасным.
Так как ребро является самым легким из всех ребер, выходящих из данной компоненты, оно будет безопасным.
Для реализовации выбора безопасного ребра на каждом шаге все ребра графа G перебираются по возрастанию веса. Для очередного ребра проверяется, не лежат ли концы
ребра в разных компонентах связности, и если это так, ребро добавляется, и компоненты объединяются.
Удобно использовать для хранения компонент структуры данных для непересекающихся множеств, как, например, списки или, что лучше,
лес непересекающихся множеств со сжатием путей и объединением по рангу (один из самых быстрых известных методов). Элементами
множеств являются вершины графа, каждое множество содержит вершины одной связной компоненты. Для работы с множествами
используются следующие процедуры:
Make-Set(v)
Создание множества из набора вершин
Find-Set(v)
Возвращает множество, содержащее данную вершину
Union(u,v)
Объединяет множества, содержащие данные вершины
Общая схема алгоритма выглядит так:
1: A ← 0
2: foreach (для каждой) вершины v ∈ V[G]
3: do Make-Set(v)
4: упорядочить ребра по весам
5: for (u,v) ∈ E (в порядке возрастания веса)
6: do ifFind-Set(u) ≠ Find-Set(v)then
7: A ← A ∪ {(u,v)}
8: Union(u,v)
9: returnA
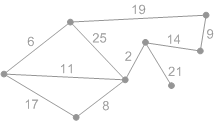
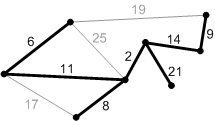
Рис. Перебираем ребра в порядке возрастания веса:
первое ребро с весом 2. Добавляем его к А.
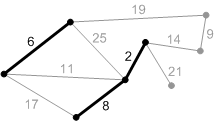
Рис. Следующее безопасное ребро с весом 6. Добавляем его.
Рис. Следующее безопасное ребро с весом 8.
Рис. Следующее безопасное ребро с весом 9.
Рис. Следующее безопасное ребро с весом 11.
Рис. Следующее безопасное ребро с весом 14.
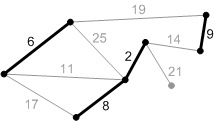
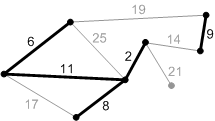
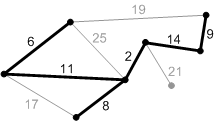
Рис. Ребра с весом 17, 19 и 25 – не безопасные. Их концы лежат в одной компоненте связности.
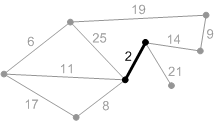
Ребро с весом 21 – безопасное, поэтому добавляем его. Минимальное остовное дерево построено.
Кластеризация на основе минимального остовного дерева
Пусть есть взвешенный граф G, у которого весами W являются расстояния между объектами. Построим для него минимальное остовное дерево и удалим
\(k-1\) ребро с максимальными весами. В результате получим \(k\) компонент связности, которые можно интерпретировать как кластеры.
Ясно, что изменяя количество кластеров, можно получить дендрограмму, позволяющую разбить граф на любое количество кластеров от одного до количества верпшин этого графа.
Матрица смежности и визуализация связи объектов.
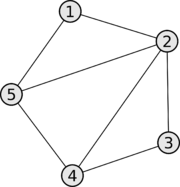
Для набора данных \(D = {x_i}_{i=1}^n\), состоящего из n точек в пространстве \(R^d\), обозначим через \(\textbf{A}\)
симметричную матрицу подобия (сходства) между точками, это матрица размером n × n заданная как
\[
\textbf{A}=
\left(
\begin{array}{llll}
a_{11}& a_{12}& \ldots &a_{1n} \\
a_{21}& a_{22}& \ldots &a_{2n} \\
\vdots & \vdots& \ddots & \vdots \\
a_{n1}& a_{n2}& \ldots &a_{nn}
\end{array}
\right)
\]
где \(a_{ij}\) обозначает подобие или сходство между точками \(x_i\) и \(x_j\), при этом сходство должно быть симметричным и
неотрицательным, т. е. \(a_{ij} = a_{ji}\) и \(a_{ij}\ge 0\), соответственно.
Матрицу \(\textbf{A}\) можно рассматривать как взвешенную матрицу смежности взвешенного (неориентированного) графа \(G = (V, E)\),
где каждая вершина является точкой и каждое ребро соединяет пару точек, т.е.
\[
V=\{x_i|i=1,...,n\}, E=\{(x_i,x_j)|1\le i,j \le n\}.
\]
Кроме того, матрица подобия \(\textbf{A}\) задает вес на каждом ребре и \(a_{ij}\) обозначает
вес ребра \((x_i, x_j)\). Если все коэффициенты сходства равны нулю или единицам, то \(\textbf{A}\) представляет регулярное смежное
отношение между вершинами.
Значения отклонений размера средней зарплаты на 2017 год по областям Украины.
При составлении ребра для каждого узла находятся k ближайших соседей, причем ребро добавляется тогда и только тогда, когда оба узла взимно близки,
то есть, как один входит в k ближайших соседей второго узла, так и другой, входит в k ближайших соседей первого узла.
Заметим, что в данном случае Киев выбивается из общей картины, так как нет ни одного региона, для которого Киев входил в k ближайших соседей
(кроме тривиального случая, когда задействованы все ребра).
Для вершины \(x_i\) через \(d_i\) обозначим степень вершины, определяемую как \(d_i=\sum_{j=1}^na_{i,j}.\)
Определим матрицу степени Δ графа G как диагональную матрицу n × n
\[
\Delta=
\left(
\begin{array}{llll}
d_{1}& 0& \ldots & 0 \\
0& d_2& \ldots & 0 \\
\vdots & \vdots & \ddots & \vdots \\
0& 0& \ldots & d_{n}
\end{array}
\right)=
\left(
\begin{array}{llll}
\sum_{j=1}^na_{1,j}& 0& \ldots & 0 \\
0& \sum_{j=1}^na_{2,j}& \ldots & 0 \\
\vdots & \vdots & \ddots & \vdots \\
0& 0& \ldots & \sum_{j=1}^na_{n,j}
\end{array}
\right)
\]
Нормализованная матрица смежности получается путем деления каждой строки матрицы смежности на степень соответствующего узла.
\[
\textbf{M}=\Delta^{-1}A=
\left(
\begin{array}{llll}
\frac{a_{11}}{d_1}& \frac{a_{12}}{d_1}& \ldots &\frac{a_{1n}}{d_1} \\
\frac{a_{21}}{d_2}& \frac{a_{22}}{d_2}& \ldots &\frac{a_{2n}}{d_2} \\
\vdots & \vdots& \ddots & \vdots \\
\frac{a_{n1}}{d_n}& \frac{a_{n2}}{d_n}& \ldots &\frac{a_{nn}}{d_n}
\end{array}
\right)
\]
При этом, если \(\textbf{M}=\{m_{i,j}\}\), то \(\sum_{j=1}^nm_{i,j}=\sum_{j=1}^n\frac{a_{i,j}}{d_i}=\frac{d_i}{di}=1.\)
Марковская кластеризация
Рассмотрим метод кластеризации, основанный на моделировании случайного блуждания на взвешенном графе.
Основная идея заключается в том, что если переходы от узла к узлу по ребрам их соединяющим, отражают веса этих ребер, то
в пределах кластера, переходы от одного узла к другому короче, чем переходы между узлами из разных кластеров.
Причина этого в том, что узлы внутри кластера имеют более высокие сходства или веса, а узлы из разных кластеров
имеют более низкое сходство.
Нормализованную матрицу смежности \(\textbf{M}\) можно интерпретировать как матрицу перехода.
При этом значения \(m_{i,j}=\frac{a_{i,j}}{d_i}\) можно интерпретировать как вероятность перехода или перехода от узла i
к узлу j в графе G.
Более того, учитывая, что
элементы матрицы \(\textbf{M}\) неотрицательны, т.е. \(m_{ij}\gt 0\),
строки из \(\textbf{M}\) являются векторами вероятности, т.е. \(\sum_{j=1}^nm_{i,j}=1,\)
таким образом, можно считать, что матрица \(\textbf{M}\) является матрицей перехода для цепи Маркова или марковским
случайным блужданием на графе G. Цепочка Маркова является случайным процессом дискретного времени \(t\)
над множеством состояний, в нашем случае это множество вершин V. Цепочка Маркова реализует
переход от одного узла к другому на дискретных шагах \(t = 1,2,...\) с вероятностью перехода от узла i к узлу j,
заданного как \(m_{ij}\). Пусть случайная величина \(X_t\) обозначает состояние в момент времени t.
Марковское свойство означает, что распределение вероятности \(X_t\) по состояниям на момент времени \(t\) зависит только от
распределения вероятности \(X_{t-1}\), т. е.
\[
P (X_t = i | X_0, X_1, ..., X_{t-1}) = P (X_t = i | X_{t-1})
\]
Далее, предположим, что цепь Маркова однородна, т.е. вероятность перехода
\[
P (X_t = j | X_{t-1} = i) = m_{ij}
\]
не зависит от шага \(t\).
Для заданного узла i матрица перехода \(\textbf{M}\) задает вероятности достижения любого
другого узла j за один шаг. Начиная с узла i при t = 0, рассмотрим
вероятность попасть в узел j при t = 2, т. е. после двух шагов. Обозначим через \(m_{ij}(2)\)
вероятность достижения j из i за два шага. Мы можем вычислить это следующим образом
\[
m_{ij}(2) = P (X_2 = j | X_0 = i) =\sum_{\nu=1}^nP (X_1 = \nu | X_0 = i) P (X_2 = j | X_1 = \nu)
= \sum_{\nu=1}^nm_{i\nu}m_{\nu j} = \textbf{m}^T_i M_j,
\]
где \(\textbf{m}_i = (m_{i1}, m_{i2}, ..., m_{in})^T\) обозначает вектор, соответствующий \(i\)-й строке
\(\textbf{M}\) и \(M_j = (m_{1j}, m_{2j}, ..., m_{nj})^T\) обозначает вектор, соответствующий \(j\)-му
столбцу \(\textbf{M}\).
Рассмотрим произведение \(\textbf{M}\) самой на себя
\[
\textbf{M}^2=\textbf{M}\times \textbf{M}=
\left(\begin{array}{c}
\textbf{m}_1^T \\
\textbf{m}_2^T \\
\vdots \\
\textbf{m}_n^T \\
\end{array}
\right)
\times
\left(
\begin{array}{cccc}
M_1 & M_2 & \ldots & M_n\\
\end{array}
\right)=
\left\{\textbf{m}_i^TM_j\right\}_{i,j=1}^n=\left\{m_{ij}(2)\right\}_{i,j=1}^n.
\]
Отсюда следует, что \(\textbf{M}^2\) - матрица вероятности перехода для цепи Маркова над двумя шагами.
Аналогично, для трех шагов матрица перехода равна \(\textbf{M}^2\times \textbf{M}=\textbf{M}^3\).
В общем случае матрица вероятности перехода для t шагов определяется следующим образом \(\textbf{M}_{t-1}\times \textbf{M}=
\textbf{M}_t\).
Таким образом, случайное блуждание на графе G соответствует взятию последовательных степеней матрицы перехода \(\textbf{M}\).
Пусть \(\tau_0\) задает вектор вероятности начального состояния, то есть для \(t = 0\).
Тогда \(\tau_{0i}= P (X_0 = i)\) - вероятность старта в узле \(i\) для всех \(i = 1, ..., n\).
Начиная с \(\tau_0\), мы можем получить вектор вероятности состояния для \(X_t\), т.е.
вероятность попасть в узел \(i\) на шаге \(t\) будет следующей
\[
\tau_{t}^T=\tau_{t-1}^T\textbf{M}
=\left(\tau_{t-2}^T\textbf{M}\right)\times \textbf{M}=\tau_{t-2}^T\textbf{M}^2
=\left(\tau_{t-3}^T\textbf{M}^2\right)\times \textbf{M}=\tau_{t-3}^T\textbf{M}^3
=\ldots
=\tau_{0}^T\textbf{M}^t.
\]
Отсюда сразу получаем
\[
\tau_{t}=\left(\textbf{M}^t\right)^T\tau_{0}=\left(\textbf{M}^T\right)^t\tau_{0}.
\]
Рассмотрим случай, когда вероятность перехода от узла i к узлу j завышена, и принимает
значеие \(m_{ij}^r\), где степень \(r\ge 1\). Для матрицы перехода \(\textbf{M}\) определим
оператор \(Υ\) следующим образом
\[
Υ (\textbf{M}, r) =\left\{\frac{m_{ij}^r}{\sum_{\nu=1}^nm_{i\nu}^r}\right\}_{i,j=1}^n.
\]
Эта операция к трансформированной или раздутой матрице вероятности перехода, но элементы ее остаются неотрицательными,
и каждая строка нормирована на сумму к 1. Чистый эффект этого оператора заключается в увеличении большей вероятности
переходов и уменьшения более низких вероятностных переходов.
Марковский метод кластеризации - это итерационный метод, который перемежает разрастание матрицы и шаги инфляции
(использование оператора \(Υ (\textbf{M}, r)\)).
Матричное разложение соответствует взятию последовательных степеней матрицы перехода, что приводит к случайным блужданиям
большей длины. С другой стороны, использование оператора инфляции \(Υ (\textbf{M}, r)\) увеличивает вероятность более вероятных переходов
и уменьшает менее вероятные переходы. Поскольку узлы в одном кластере должны иметь более высокий вес и, следовательно,
более высокие вероятности переходов между ними, то оператор \(Υ (\textbf{M}, r)\) делает этот переход более вероятным, то есть
оставляет узлы внутри кластера. Таким образом, это ограничивает масштабы случайного блуждания.
Вместо того, чтобы полагаться на заданное пользователем число \(k\) выходных кластеров, MCL принимает в качестве входного
параметра значение \(r\gt 1\). Более высокие значения \(r\) приводят к большему количеству меньших кластеров,
тогда как меньшие значения приводят к малому числу, но больших кластеров.
Однако предварительно точное число кластеров не может быть определено.
В принципе, MCL сначала добавляет петли или собственные ребра к \(\textbf{A}\), если они не существуют, но если \(\textbf{A}\) - матрица смежности, то это не требуется, так как узел наиболее похож на себя, и,
следовательно, \(\textbf{A}\) должен иметь высокие значения на диагоналях.
Итеративный процесс расширения и инфляции MCL прекращается, когда матрица перехода сходится, т.е. когда разность между матрицей
перехода от двух последовательных итераций становится меньше порога \(\varepsilon>0\). Матричная разность ищется в терминах нормы Фробениуса
\[
\left\|\textbf{M}_t-\textbf{M}_{t-1}\right\|_F=\sqrt{\sum_{i=1}^n\sum_{j=1}^n\left|\textbf{M}_t(i,j)-\textbf{M}_{t-1}(i,j)\right|^2}.
\]
Окончательно кластеры можно найти, перечислив слабосвязанные компоненты в направленном графе, индуцированные окончательной матрицей
перехода \(\textbf{M}_t\).
Направленный граф, индуцированный \(\textbf{M}_t\), обозначается как \(G_t = (V_t, E_t)\). Множество вершин
такое же, как набор узлов в исходном графе, т.е. \(V_t = V\), и множество ребер задано в виде
\[
E_t =\left\{(i, j) | \textbf{M}_t (i, j)> 0\right\}.
\]
Другими словами, направленное ребро \((i, j)\) существует только в том случае, если узел \(i\) может перейти в узел \(j\)
в пределах \(t\) шагов процесса расширения и инфляции. Узел \(j\) называется аттрактором,
если \(\textbf{M}_t(j,j)>0\), и мы говорим, что узел \(i\) притягивается к аттрактору \(j\), если \(\textbf{M}_t(i,j)>0\).
Процесс MCL дает набор узлов аттрактора \(V_a \subseteq V\), так что другие узлы
притягивается, по крайней мере, к одному аттрактору из \(V_a\). То есть для всех узлов \(i\) существует узел
\(j\in V_a\),такой что \((i, j) \in E_t\). Сильно связная компонента в ориентированном графе определяет максимальный подграф такой,
что существует направленный путь между всеми парами вершин в подграфе. Чтобы извлечь кластеры из \(G_t\), MCL сначала обнаруживает
сильно связанные компоненты \(S_1, S_2,...., S_q\) над множеством аттракторов \(V_a\). Далее,
для каждого сильно связанного множества аттракторов \(S_j\) MCL обнаруживает слабосвязанные компоненты, состоящие из всех узлов
\(i \in V_t - V_a\), притягиваемых к аттрактору из \(S_j\). Если узел \(i\) притягивается к множеству сильно связанных компонентов,
он добавляется к каждому такому кластеру, в результате чего возможны перекрывающиеся кластеры.
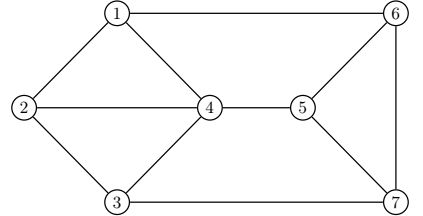
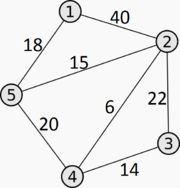
Пример
Пусть дан граф
с матрицей смежности
Для него матрица степени графа будет равна
Нормализованная матрица графа равна
Выберем значение r=2.65.
Найдем матрицы перехода, пока норма Фробениуса отклонения от матрицы, полученной на предыдущем шаге итерации не станет меньше
\(\varepsilon=0.0001\)
Результатом будет следующее:
По данным государственной службы статистики України средняя заработная плата по видам экономической деятельности в 2017 году составляет
Сельское хозяйство, лесное хозяйство и рыбное хозяйство
из них сельское хозяйство
Промышленность
Строительство
Оптовая и розничная торговля; ремонт автотранспортных средств и мотоциклов
Транспорт, складское хозяйство, почтовая и курьерская деятельность
наземный и трубопроводный транспорт
водный транспорт
авиационный транспорт
складское хозяйство и вспомогательная деятельность в сфере транспорта
почтовая и курьерская деятельность
Временное размещение и организация питания
Информация и телекоммуникации
Финансовая и страховая деятельность
Операции с недвижимым имуществом
Профессиональная, научная и техническая деятельность
из них научные исследования и разработки
Деятельность в сфере административного и вспомогательного обслуживания
Государственное управление и оборона; обязательное социальное страхование
Образование
Здравоохранение и предоставление социальной помощи
из них здравоохранение
Искусство, спорт, развлечения и отдых
деятельность в сфере творчества, искусства и развлечений
функционирования библиотек, архивов, музеев и других учреждений культуры
Предоставление других видов услуг
6383
6149
8055
6537
7935
8220
7960
8296
33689
8752
4126
5112
12725
13257
6174
10162
8334
5798
10346
5782
5005
5017
6433
5792
5466
6884
Провести кластеризацию и проанализировать полученные результаты.
Задача 3.
Для данных
провести кластеризацию областей Украины по экологическому состоянию.
Задача 4.
В таблице приведены данные по концентрации уксусной кислоты, H2S и молочной кислоты в 30 образцах зрелого сыра чеддер.
Кроме того, предоставляется субъективная ценность вкуса.
Используя методы кластеризации, дать оценку данным образцам сыра.
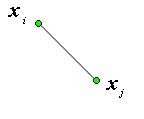
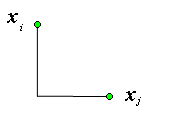
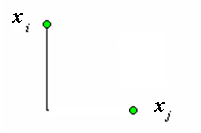
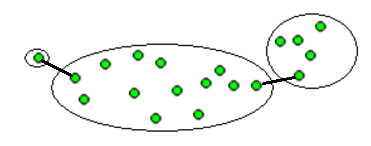
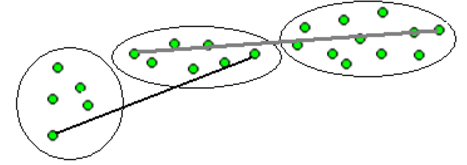

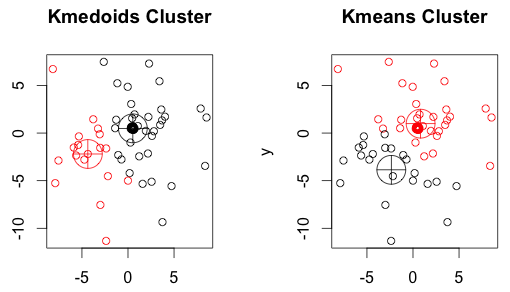
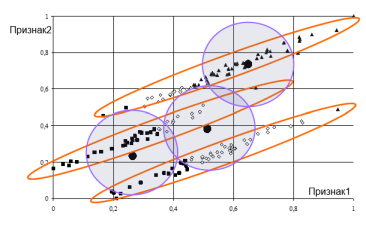 ,
,