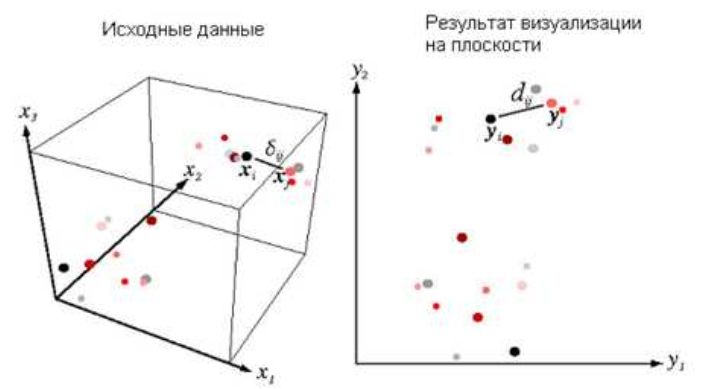
Человек достаточно хорошо анализирует двумерные, или, в крайнем случае, трехмерные данные, однако большинство информации, которая требует анализа,
имеет существенно большую размерность. Что же делать? Для того, чтобы помочь исследователю провести анализ имеющихся данных, используют методы
визуализации, сводя многомерные данные к дву- или трехмерным. Различные инструменты для визуализации многомерных данных можно найти на
веб-сайте Science Hunter.
Рассмотрим пример. Достаточно часто информация задана в виде квадратной таблицы удаленностей объектов друг от друга. На пересечении \(i\)-ой строки и \(j\)-oro
столбца в такой таблице стоит значение, определяющее отличие (или сходство) \(i\)-ro и \(j\)-ro
объекта. Такое представление информации характерно для различного рода
исследований, когда человеку предлагается оценивать сходство или различие в некоторой системе объектов или понятий.
Відстані між обласними центрами України
Місто
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
Таким образом, изначально каждому объекту не сопоставляется никакой
координаты в многомерном пространстве, и, представить такие данные в виде некоторой геометрической интерпретации достаточно сложно. Задача
многомерного шкалирования заключается в том, чтобы так сконструировать распределение данных в пространстве, чтобы расстояния между
объектами соответствовали значениям, заданным в матрице удаленностей. Возникающие при
этом координатные оси могут быть интерпретированы как некоторые факторы, значения которых определяют различия объектов между собой, например,
главные направления, определяемые с помощью МГК (PCA). В таком случае, поставив в соответствие каждому объекту пару координат, получим способ
визуализации данных.
Иллюстрация многомерного шкалирования.
В линейном методе метрического шкалирования применяется метод главных компонент, но не к исходной матрице расстояний, а к дважды центрированной матрице, у которой среднее
значение чисел в любой строке и столбце равно нулю.
Дважды центрированная матрица однозначно вычисляется по исходной. После этого, существует возможность определить размерность пространства,
обеспечивающего точное воспроизведение матрицы удаленностей, либо определить эффективную размерность конструируемого пространства признаков,
которая обеспечит воспроизведение матрицы удаленностей с заданной точностью.
Получение дважды центрируемых матриц является обязательным этапом для многомерного шкалирования.
Основу многомерного шкалирования составляют разного рода предположения о структуре различий имеющихся объектов, каждый из
которых характеризуется набором признаков. Сами по себе эти признаки могут иметь разную природу и структуру - могут быть сложными и простыми,
одномерными и многомерными. Главным обоснованием многомерного шкалирования является предположение, что различие определяется расхождением по
ограниченному числу простых признаков, которые явно или неявно могут быть использованы при учете этих самых различий.
Таким образом, формализация задачи многомерного шкалирования может быть сформулирована следующим образом - для заданной
матрицы различий между объектами
\begin{equation}\label{'md1'}
D=\left(
\begin{array}{cccc}
D_{1,1} & D_{1,2}&\cdots & D_{1,n} \\
D_{2,1} & D_{2,2}&\cdots & D_{2,n} \\
\vdots & \vdots&\ddots & \vdots \\
D_{n,1} & D_{n,2}&\cdots & D_{n,n} \\
\end{array}
\right)
\end{equation}
нужно построить систему точек
\begin{equation}\label{'md2'}
X=\left(
\begin{array}{cccc}
X_{1,1} & X_{1,2}&\cdots & X_{1,n} \\
X_{2,1} & X_{2,2}&\cdots & X_{2,n} \\
\vdots & \vdots&\ddots & \vdots \\
X_{n,1} & X_{n,2}&\cdots & X_{n,n} \\
\end{array}
\right)
\end{equation}
так, чтобы матрица расстояний между ними
\begin{equation}\label{'md3'}
d=\left(
\begin{array}{cccc}
d_{1,1} & d_{1,2}&\cdots & d_{1,n} \\
d_{2,1} & d_{2,2}&\cdots & d_{2,n} \\
\vdots & \vdots&\ddots & \vdots \\
d_{n,1} & d_{n,2}&\cdots & d_{n,n} \\
\end{array}
\right)
\end{equation}
в смысле некоторого критерия, была как можно ближе к матрице \(D\).
Постановка задачи более чем расплывчатая.
Существует два основных подхода к решению этой задачи - метрический и неметрический.
В первом случае строится модель субъективного расстояния, при этом исходные оценки различий (сходства) должны удовлетворять
аксиомам метрического пространства. Неметрическое шкалирование использует не числовые характеристики сходства (различия), а их порядок.
То есть порядок расстояний между точками должен соответствовать порядку оценок исходных данных.
Прежде всего заметим, что в этом случае для матрицы \(D\) должны выполняться следующие условия
Рефлексивность отличий: \(D_{i,i}=0\), отличие между двумя идентичными элементами равно нулю.
Симметричность: \(D_{i,j}=D_{j,i}\). Значения различий не должно зависеть от перестановок.
Выполнение неравенства треугольника: \(D_{i,j}+D_{j,k}\ge D_{i,k}\).
Таким образом, субъективные оценки должны представлять собой величины на шкале отношений.
Решение задачи многомерного шкалирования состоит из двух составляющих -
Определение минмальной размерности пространства (количество базисных осей), необходимого для описания различий.
Вычисление координат каждого объекта относительно базисных осей.
Достаточно интересный подход к решению первой задачи предложил Р.Шеппард еще в 1962 году (Shepard R.M. The analysis of proximities:
multidimensional scaling with an unknown distance function // Psycho metrika, 1962. V. 27. № 2-3. P. 125-139, 219-246).
Идея Шеппарда состоит в следующем - давайте уменьшим маленькое и увеличим большое. Точкой водораздела "большое-маленькое расстояние"
будет среднее арифметическое расстояний. Хотя, естественно, это не единственный подход, есть методы, основанные на вращении пространств
(Кэрол и Виш) и другие.
Относительно второй задачи.
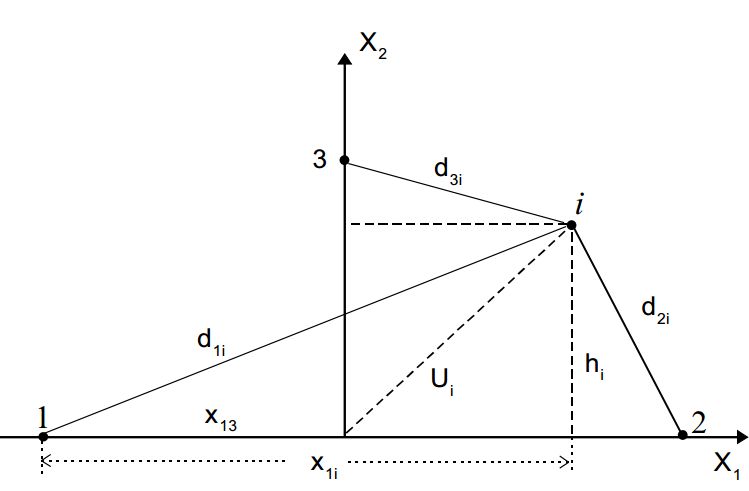
Метод ортогональных проекций.
Идея данного подхода (ординация Орлочи) достаточно проста - пусть информация о системе точек определена расстоянием между ними \((d_{i,j})_{i,j}\). Выберем среди них две точки с
максимальным расстоянием и отразим их на первую ось, первая из точек будет началом координат, вторая - \(X_{1,2}=d_{1,2}\).
Найдем проекцию \(i-\)й точки на первую ось
\[
x_{1,i}=\frac{d^2_{1,i}+d^2_{1,2}-d^2_{2,i}}{2d_{1,2}}
\]
и расстояние от этой точки до первой оси
\[
h_i=\sqrt{d^2_{1,i}-x_{1,i}^2}.
\]
Среди всех точек выберем точку с максимальным значением \(h_i\) и положим \(h_{\max}=X_{2,3}\). Заметим, что если все \(h_i=0\), то все точки лежат на одной оси.
Отложим \(X_{2,3}\) на оси \(X_{2}\) и спроектируем оставшиеся точки на полученную ось
\[
x_{2,i}=\frac{x^2_{2,3}+u^2_{i}-d^2_{3,i}}{2x_{2,3}}
\]
где
\[
u_i=\sqrt{h^2_{1}+(x_{1,i}-x_{1,3})^2}.
\]
Нахождение второй ортогональной проекции.
Далее, расстояние от каждой точки до плоскости \(X_1X_2\) равно
\[
q_i=\sqrt{d_{1,i}^2-x_{1,i}^2-x_{2,i}^2}.
\]
если не все \(q_i\) равны нулю, то берем точку с максимальным значением \(q_{\max}\) и проводим ось \(X_3\). На следующем шаге
находим проекции оставшихся точек на полученную ось
\[
x_{3,i}=\frac{d^2_{1,i}+x^2_{3,4}+(x_{1,i}-x_{1,4})^2+(x_{2,i}-x_{2,4})^2-x^2_{1,i}-x^2_{2,i}-d^2_{4,i}}{2x_{3,4}}.
\]
В случае необходимости, этот процесс можно продолжать, пока не будут выполнены требуемые условия, например, расброс данных до \(90\%\) дисперсии.
Метод прост и приятен, но зависит от первоначальных расстояний, то есть случайные выбросы и шум могут существенно исказить результат
шкалирования (визуализации данных).
Метод Торгенсона.
В основе этого метода лежит идея приближения исходной матрицы, матрицей меньшего ранга. Пусть, как и ранее, \(d_{i,j}\)- симметричные
расстояния между \(i-\)й и \(j-\)й точками.
Пусть \(B=(b_{i,j})_{i,j=1}^{n-1}\), где
\[
b_{i,j}=\frac{d^2_{i,j}+d^2_{i,k}-d^2_{j,k}}{2},j,k\ne 1.
\]
Нетрудно видеть, что \(b_{i,j}\) равно скалярному произведению векторов от \(i-\)й точки к \(j-\)й и \(k-\)й.
Действительно, из теоремы косинусов имеем
\[
d^2_{j,k}=d^2_{i,j}+d^2_{i,k}-2d_{i,j}d_{j,k}\cos\varphi \Rightarrow d_{i,j}d_{j,k}\cos\varphi=\frac{d^2_{i,j}+d^2_{i,k}-d^2_{j,k}}{2}.
\]
Так как в качестве \(i-\)й точки может быть любая, то таких матриц \(B\) существует \(n\) штук.
Любая положительная полуопределенная матрица \(B\) может быть факторизована для получения матрицы \(X\)
\[
B=X\cdot X^T.
\]
Если ранг матрицы \(B\) равен \(r\), где \(r\ge (n-1)\), то \(X\) является прямоугольной матрицей \((n-1)\times r\), элементы которой являются проекциями точек на
\(r\) ортогональных осей с началом в \(i-\)й точке евклидова пространства. Матрицы \(B\), построенные с использованием разных \(i-\)х точек
дадут множество матриц \(X\), отличающихся друг от друга только смещением и вращением осей.
Поэтому, имеет смысл поместить начало координат в центре тяжести всех точек. В этом случае получаем единственное решение, причем, с
компенсацией случайной ошибки. Если пропустить разного рода преобразования, то получим
\[
b_{j,k}=\frac{1}{2}\left(d^2_{i,j}+d^2_{i,k}-d^2_{j,k}\right)-\frac{1}{2n}\sum_{j=1}^n\left(d^2_{i,j}+d^2_{i,k}-d^2_{j,k}\right)
-\frac{1}{2n}\sum_{k=1}^n\left(d^2_{i,j}+d^2_{i,k}-d^2_{j,k}\right)+\frac{1}{2n^2}\sum_{j=1}^n\sum_{k=1}^n\left(d^2_{i,j}+d^2_{i,k}-d^2_{j,k}\right).
\]
А что касается факторизации, то
\[
X=E\Lambda^{1/2},
\]
где \(E-\) матрица собственных векторов, а \(\Lambda\) диагональная матрица собственных значений \(B\).
Заметим, что другой подход к задаче факторизации можно посмотреть здесь.
Рассмотрим простой пример,
но, в отличие от предыдущих рассуждений, используем матричный подход.
По мотивам вступительной компании 2017 года дан список конкурсных предметов для поступления на 1-й курс бакалаврата (3-й и 4-й предметы по выбору,
то есть при сравнении их можно менять местами).
1-й предмет
2-й предмет
3-й предмет
4-й предмет
Філософія
українська мова та література
історія України
математика
іноземна мова
Екологія
українська мова та література
біологія
хімія
географія
Інженерія програмного забезпечення
українська мова та література
математика
фізика
іноземна мова
Менеджмент
українська мова та література
математика
іноземна мова
географія
Выпишем значения различия конкурсных предметов для данных специальностей
Філософія
Екологія
Інженерія програмного забезпечення
Менеджмент
Філософія
0
3
2
2
Екологія
3
0
3
2
Інженерія програмного забезпечення
2
3
0
1
Менеджмент
2
2
1
0
Для получения дважды центрированной матрицы сделаем вспомогательные построения при условии \(n=4\).
Использование неметрического многомерного шкалирования предполагает наличие более слабых ограничений, чем рассмотренном ранее случае,
достаточно, чтобы оценки различий (сходства) удовлетворяли отношениям шкалы порядка.
Пусть \(m = n (n - 1) / 2\) и несходство \(\delta_{i,j}\) не может быть измерено, как в предыдущем случае, но они
могут быть ранжированы по порядку,
\[
\delta_{r_1,s_1}\lt \delta_{r_2,s_2}\lt...\lt\delta_{r_m,s_m},
\]
где \(r_1,s_1\) указывает пару элементов с наименьшим несходством, а \(r_m,s_m\) представляет пару с наибольшей несходством.
В неметрическом многомерном масштабировании ищем низкоразмерное представление таких точек, что ранжирование расстояния
\[
d_{r_1,s_1}\lt d_{r_2,s_2}\lt...\lt d_{r_m,s_m},
\]
точно соответствуют порядку несхожести. Но не наоборот, порядок значений расстояний между точками может не отвечать порядку
ранжирования несходства элементов.
Подходящие \(\hat{d}_{i,j}\) можно оценить монотонной регрессией, в которой мы ищем значения \(\hat{d}_{i,j}\), чтобы минимизировать
масштабированную сумму квадратов разностей
\[
S^2=\frac{\sum_{i\lt j}\left(d_{i,j}-\hat{d}_{i,j}\right)^2}{\sum_{i\lt j}d_{i,j}^2}
\]
при условии ограничения
\[
\hat{d}_{r_1,s_1}\le \hat{d}_{r_2,s_2}\le...\le \hat{d}_{r_m,s_m}.
\]
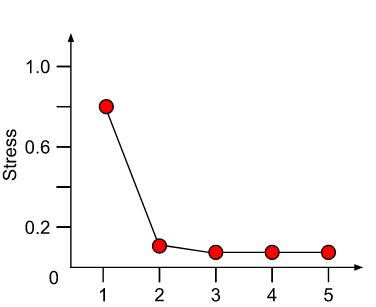
Минимальное значение \(S^2\) для данной размерности \(k\) называется STRESS.
Заметим, что \(\hat{d}_{i,j}\) не являются расстояниями. Это просто цифры, используемые в качестве ссылки
для оценки монотонности \(\hat{d}_{i,j}.\) Минимальное значение STRESS для всех возможных конфигураций точек можно найти по следующему
алгоритму.
Выберем значение k и начальную конфигурацию точек в k измерениях.
Первоначальной конфигурацией могут быть n точек, выбранных случайным образом.
Для начальной конфигурации точек найдем промежуточные расстояния \(d_{i,j}\) и, минимизируя значения STRESS,
определим соответствующие \(\hat{d}_{i,j}\).
Выберем новую конфигурацию точек, для которых расстояния \(d_{i,j}\) минимизируют \(S^2\) относительно \(\hat{d}_{i,j}\),
найденных на предыдущем шаге. Для этой цели можно использовать, например, метод наискорейшего спуска или метод Ньютона-Рафсона.
Используя монотонную регрессию, найдем новые \(\hat{d}_{i,j}\) для \(d_{i,j}\), которые найдены на шаге 3. Это
дает новое значение STRESS.
Повторяем шаги 3 и 4 до тех пор, пока STRESS не сходится к минимуму.
Используя предыдущие пять шагов, вычислить минимальное значение STRESS для величины k
начиная с k = 1. При увеличении k значения STRESS будут монотонно убывать. То значение k, при котором значения STRESS выравниваются,
показывает, что размерность k позволяет адекватно масштабировать исходные данные.
Описанный метод опирается на монотонность \(\hat{d}_{i,j}\), что не есть просто для нахождения минимального значения STRESS.
Существует метод, не использующий данного условия, он основан на минимизации величины
\[
S_\delta=\frac{\sum \delta_{i,j,k,l}\left(d_{i,j}-d_{k,l}\right)^2}{\sum \left(d_{i,j}-d_{k,l}\right)^2},
\]
где
\[
\delta_{i,j,k,l}=
\left\{
\begin{array}{ll}
1, & \hbox{ если } \hbox{sign} \left(d_{i,j}-d_{k,l}\right)\left(D_{i,j}-D_{k,l}\right)>0,\\
0, & \hbox{ иначе.}
\end{array}
\right.
\]
этот подход направлен на усиление монотонности отображения, то есть усиления \(d_{i,j}\lt d_{k,l}\) если \(D_{i,j}\lt D_{k,l}\).
В нелинейных методах размерность пространства задается изначально, и, с помощью градиентных методов оптимизируется функционал качества,
описывающий меру искажения матрицы удаленностей.
Формализуем постановку задачи. Итак, пусть даны точки \(x_1 ,x_2 ,...,x_n \) в
пространстве размерности \(k.\) Расстояние между точками \(x_i \) и \(x_j \) обозначим через
\(\delta _{i,j} \). Найдем точки \(y_1 ,y_2 ,...,y_n \) в пространстве меньшей
размерности (2 или 3) так, чтобы расстояние между ними, равное \(d_{i,j} \)
было поставлено в соответствии с \(\delta _{i,j} \). В идеале хотелось бы
получить прямое соответствие \(d_{i,j} = \delta _{i,j} \), но в нетривиальном
случае при переходе в пространство меньшей размерности получить такое
равенство невозможно. Но как-то эту задачу нужно решать, и, одним из
возможных методов нахождения зависимости \(d_{i,j} \) от \(\delta _{i,j} \)
является сведение к минимизации некоторой функции цели. В качестве такой
задачи можно использовать минимизацию среднеквадратической ошибки
\[J\left( y \right) = \frac{\sum\limits_{i \lt j}
{\left( {d_{i,j} - \delta _{i,j} } \right)^2} }{\sum\limits_{i \lt j} {\delta
_{i,j}^2 } }.\]
Минимизация функции цели является нетривиальной задачей. Для ее решения можно использовать метод градиентного спуска
\[
\nabla _{y_k } J\left( \delta \right) = \frac{2}{\sum\limits_{i \lt j} {\delta
_{i,j}^2 } }\sum\limits_{j \ne k} {\left( {d_{k,j} - \delta _{k,j} }
\right)\frac{\left( {y_k - y_j } \right)}{\sum_{i\lt j} {d_{k,j} } }}\to \min
\]
Координаты \(x_1 ,x_2 ,...,x_n \) выбираются так, чтобы получить наибольшую
вариацию.
Заметим, что многомерное распределение данных, отображенное на плоскость, не
решает всех вопросов визуализации исходных данных. Совершенно естественна
идея отображать на двумерную карту не только сами точки данных, но и
разнообразную информацию, сопутствующую исходным данным, например, положение
точек в исходном пространстве, плотности различных подмножеств, другие
непрерывно распределенные величины, заданные в исходном пространстве
признаков. Все приводит к идее более эффективного использования всей
первичной информации для отображения как количественной, так и качественной
информации.
Наконец, после того, как данные нанесены на двумерную плоскость, хотелось бы, чтобы появилась возможность расположить на двумерной плоскости те
данные, которые не участвовали в настройке отображения. Это позволило бы, с одной стороны, использовать полученную картину для построения
различного рода экспертных систем и решать задачи распознавания образов, с другой - использовать ее для восстановления данных с пробелами.
В результате приходим к идее использования для визуализации данных и извлечения информации некоторого вспомогательного объекта, называемого
картой. Этот объект представляет ограниченное двумерное нелинейное многообразие, вложенное в многомерное пространство данных таким образом,
чтобы служить моделью данных, то есть
форма и расположение такого многообразия должна отражать основные
особенности распределения множества точек данных.
Простой пример карты данных - плоскость первых двух главных компонент. Как уже отмечалось выше, среди всех двумерных плоскостей, вложенных в
пространство, именно плоскость первых двух главных компонент служит
оптимальным экраном, на котором можно отобразить основные закономерности, присущие данным. В качестве другой, еще более простой (но не оптимальной) карты можно использовать любую координатную плоскость любых двух выбранных координат.
Цель, как и ранее - проецировать имеющиеся данные в пространство меньшей размерности с сохранением соответствия расстояния между имеющимися точками
(объектами).
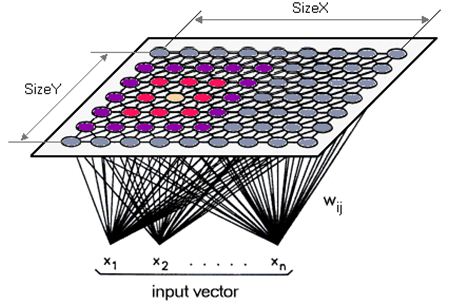
Карты Кохонена \cite{kohonen} производят картографию от многомерного входа на 1D или 2D решетку узлов с использованием идеологии нейронных сетей.
Важной особенностью этой картографии является сохранение топологии, между исходными данными и нейронами, на которые они проецируются.
Самоорганизующиеся карты Кохонена представляют собой нейронную сеть на основе жадного алгоритма, не требующего обучения. Заметим, что идея SOM
основана на организации функционирования головного мозга - активизация нейрона при восприятии информации приводит к возбуждению участков в соседних
частях мозга.
Перейдем к подробному изложению идеологии SOM. Нейросетевая архитектура, предложенная Тойво Кохоненом для автоматической кластеризации
(классификации без учителя), основана на идее использовании информации о взаимном расположении нейронов, которые образуют решетку.
Сигнал в такую нейросеть поступает сразу на все нейроны, а веса соответствующих синапсов интерпретируются как координаты положения узлов, и,
выходной сигнал формируется по принципу "победитель забирает все" - то есть ненулевой выходной сигнал имеет нейрон, ближайший
(в смысле весов синапсов) к подаваемому на вход объекту. В процессе обучения веса синапсов настраиваются таким образом, чтобы узлы решетки
"располагались" в местах локальных сгущений данных, то есть описывали кластерную структуру облака данных, с
другой стороны, связи между нейронами соответствуют отношениям соседства между соответствующими кластерами в пространстве признаков.
Изначально SOM представляет сетку из узлов, соединенных между собой связями.
Кохонен рассматривал два варианта соединения узлов - с прямоугольной и
гексагональной сеткой. В прямоугольной сетке каждый узел соединен с четырьмя соседними, а в гексагональной - с шестью ближайшими узлами.
Нейроны в прямоугольной решетке - каждый нейрон имеет 4 ближайших соседа.
Нейроны в гексагональной решетке - каждый нейрон имеет 6 ближайших соседей.
Примеры использования двумерных сеток нейронов Кохонена.
Заметим, что среди наиболее популярных топологий нейронных сетей Кохонена следует отметить следующие случаи
Линейный слой единичной высоты.
Круговой слой единичной высоты.
Одномерные сети Кохонена.
а также,
Цилиндрический слой.
Тороидальный слой.
Двумерные сети Кохонена.
Инициализация карты Кохонена
В основе SOM лежит связная структура нейронов, конкурирующих между собой при
воздействии сигнала. Каждому нейрону поставлен в соответствие вес \(w_{ij}\), число весов равно размерности входного сигнала.
Существует несколько способов начальной инициализации карты, путем
присвоения значений всем векторам весов нейронов \(w_{ij}\) следующими
способами:
Задание всех координат случайными числами.
Присвоение вектору веса значения случайного наблюдения из входных данных.
Выбор векторов веса из линейного пространства, натянутого на главные
компоненты набора входных данных.
Следует заметить, что каждый нейрон после инициализации становится
неподвижен на карте, т.е. вектор \(p \) не изменяется в течение всего обучения.
Алгоритм обучения
Алгоритм обучения производится по итерациям.
Пусть \(t \)- номер итерации. Положим, что инициализация имела номер итерации 0 .
Далее, выполняются следующие операции:
Выбираем случайный вектор \(x(t)\) из набора входных значений.
Находим расстояние до всех векторов весов всех нейронов карты. Для данной
операции выбирается какая-нибудь мера, чаще всего используется
среднеквадратическое отклонение. Ищем нейрон, наиболее близкий ко входному
значению \(x(t)\):
\[
d(x(t), w_{\nu \mu} (t)) \lt d(x(t), w_{ij} (t)),
\]
где \(w_{\nu \mu }(t) \)- вектор веса нейрона победителя (MBU, Winner) \(M_{\nu, \mu}(t)\), \(w_{i,j} (t) \)- вектор веса, \(d(x(t), w_{i,j} (t)) \)- некая мера отклонения.
В случае, если вышеуказанному условию удовлетворяет несколько нейронов, то нейрон-победитель выбирается случайным образом.
После этого узлы начинают перемещаться в пространстве. Однако, узел перемещается не один, а увлекает за собой определенное
количество ближайших узлов из некоторой окрестности на карте. Поясним сказанное: если радиус окрестности равен 1, то вместе с ближайшим узлом по
направлению к \(х \) двигаются 4 его соседа по карте, в случае прямоугольной сетки, и 6 соседей, в случае гексагональной сетки.
Самоорганизующиеся карта Кохонена (SOM).
В настройке карты различают два этапа - этап грубой (ordering) и этап тонкой (fine-tuning) настройки. На первом этапе выбираются большие значения окрестностей, и,
движение узлов носит коллективный характер - в результате карта "расправляется" и грубым образом отражает структуру данных; на этапе
тонкой настройки радиус окрестности равен 1-2 и настраиваются уже индивидуальные положения узлов.
О характере движения следует заметить следующее: обычно он настраивается так, чтобы среди всех двигающихся узлов наиболее сильно смещался центральный
- ближайший к точке данных - узел, а остальные испытывали тем меньшие смещения, чем дальше они от центра узла.
Характер движения формируется так называемыми затухающими функциями соседства (neighborhood function). Если это не так, и все соседи из
окружения испытывают равные смещения, то такая функция соседства называется пузырьковой (bubble), и, для нее характерно большее число актов перемещения
для обучения и менее гладкая сетка.
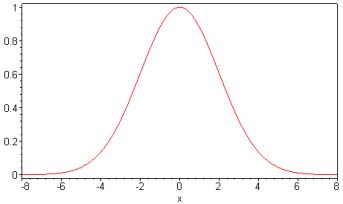
Рассмотрим подробнее определение меры соседства нейронов и изменение весов нейронов в карте. Выбираем меру соседства - функцию \(h(t)\). Обычно, в качестве
функции \(h(t) \) используется гауссовская функция:
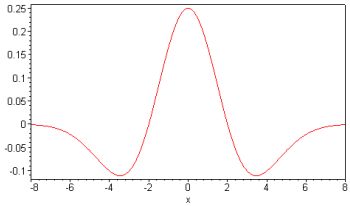
Мексиканская шляпа (нормированная вторая производная функции Гаусса)
Примеры функций соседства.
Пусть \(h(t) \) функция Гаусса, тогда "мера соседства" между нейронами \(M_{i,j}\) и
\(М_{\nu \mu }\). будет иметь вид
\[
h_{i,j}^{\nu ,\mu } (t) = \alpha \left( t \right)\exp \left( { -
\frac{\left\| {r_{i,j} - r_{\nu ,\mu } } \right\|^2}{2\delta ^2(t)}}
\right),
\]
где \(0\lt\alpha (t)\lt 1 \)- обучающий сомножитель, монотонно убывающий с каждой
последующей итерацией (то есть определяющий приближение значения векторов
веса нейрона-победителя и его соседей к наблюдению; чем больше шаг, тем
меньше уточнение);
\(r_{i,j}\), \(r_{\nu \mu }\) - координаты узлов \(M_{i,j} (t) \)и \(М_{\nu ,\mu } (t)\) на
карте;
\(\delta (t)\) - монотонно убывающий сомножитель, регулирующий количество соседей в
зависимости от итерации.
Параметры \(\alpha \), \(\delta \) и их характер убывания определяются экспертным путем.
Более простой способ задания функции соседства: \(h_{i,j}^{\nu ,\mu } (t) =
\alpha (t),\) если \(M_{i,j} (t) \) находится в окрестности \(М_{\nu ,\mu } (t) \) заранее
заданного радиуса, и 0 - в противном случае.
Функция \(h(t)\) равна \(\alpha (t)\) для нейрона-победителя и уменьшается с удалением от него.
Следующий этап - вычисление ошибки карты. Изменяем вектора весов по формуле:
\[
m_{i,j} (t) = m_{i,j} (t - 1) + h_{i,j}^{\nu ,\mu } (t)\left( {x(t) -
m_{i,j} (t - 1)} \right).
\]
Таким образом, все узлы, являющиеся соседями нейрона-победителя, приближаются к рассматриваемому наблюдению.
Наконец, рассмотрим выбор условия остановки процесса формирования карты.
Схема движения нейронов.
Для определения критерия остановки в большинстве случаев используется ошибка карты, например, как среднее арифметическое расстояние между наблюдениями и векторами веса соответствующих им нейрона-победителя:
\[
\frac{1}{N}\sum\limits_{i,j}^N {\left\| {x_{i,j} - w_{i,j} }
\right\|,}
\]
где \(N \)- количество элементов набора входных данных.
Алгоритм повторяется определенное число тактов. На первом этапе число тактов выбирается порядка тысяч, на втором - десятка тысяч (понятно, что число шагов может сильно изменяться в зависимости от задачи).
Отметим, что предложенный алгоритм не использует явно никакого критерия оптимизации. Хотя ясно, что, по крайней мере, будет уменьшаться среднее
расстояние от каждой точки данных до ближайшего узла карты. Средний квадрат такого расстояния служит критерием качества построенной карты. В этом
пакете, как правило, строится несколько десятков карт, из которых выбирается лучшая согласно упомянутому критерию.
В результате действия алгоритма строится карта, то есть двумерная сетка узлов, размещенных в многомерном пространстве. Для того, чтобы изобразить их
положение используются различные средства. Одно из них - такое раскрашивание карты, когда цвет отражает расстояние между узлами.
Примеры использования SOM.
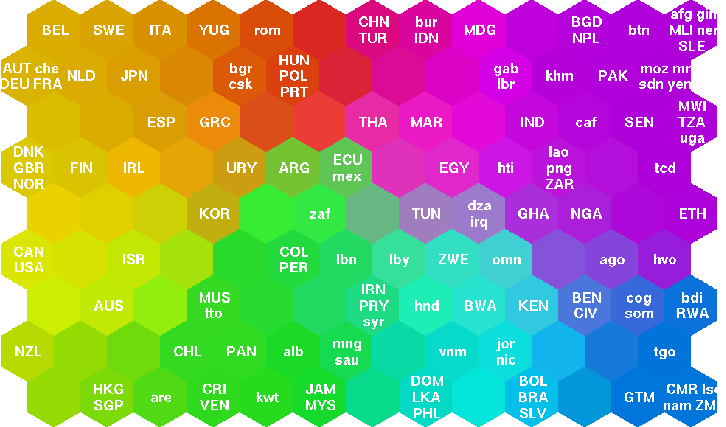
Всемирная карта бедности.
На страничке
Helsinki University of Technology Laboratory of Computer and Information Science приведен пример использования SOM для построения некоего
комплексного экономического показателя, по которому раскрашена обычная географическая карта. В результате, страны со сходной экономической
ситуацией изображены на карте цветами, близкими по спектру.
Для построения этой карты рассмотрено 39 особенностей (индикаторов), описывающих различные факторы качества жизни, например, уровень системы
здравоохранения, образовательные услуги, качество питания и пр. Государства, для которых имеющиеся значения индикаторов подобны, образовывают различные
кластеры, которые на карте автоматически кодировались различными цветами. В результате этого процесса, каждой стране было автоматически назначено
некоторое цветовое описание, характеризующее уровень бедности -- от желтого цвета благополучных стран до фиолетового.
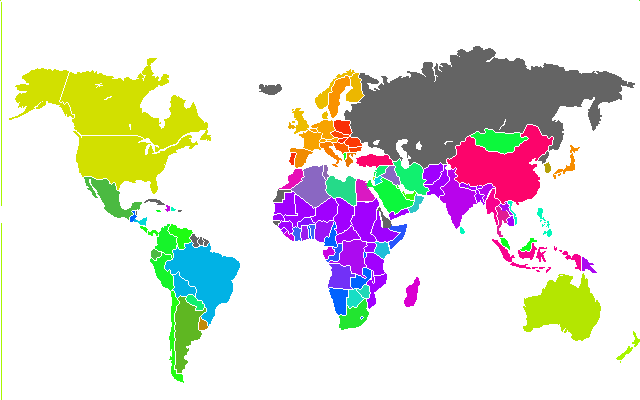
Распределение цветов карты бедности мира.
На данной карте каждая страна окрашена в цвет согласно уровню бедности. В серый цвет окрашены страны, для которых (на время исследования) необходимая
статистика была либо неполной, либо недоступной.
Карта бедности мира.
Пример использования сетей Кохонена - распознавание рукописного текста.
Провести визуализацию для следующих данных - схожесть украинских политиков по 10-бальной системе. 10- абсолютная схожесть, 0 - абсолютное отличие.
Порошенко П.
Тимошенко Ю.
Садовый А.
Вилкул А.
Ляшко О.
Турчинов А.
Порошенко П.
-
3
5
3
2
7
Тимошенко Ю.
3
-
2
8
9
3
Садовый А.
5
2
-
0
1
5
Вилкул А.
3
8
0
-
8
0
Ляшко О.
2
9
1
8
-
3
Турчинов А.
7
3
5
0
3
-
Задача 2.
Для десяти журналов по психологии
A
American Journal of Psychology
B
Journal of Abnormal and Social Psychology
C
Journal of Applied Psychology
D
Journal of Comparative and Physiological Psychology
E
Journal of Consulting Psychology
F
Journal of Educational Psychology
G
Journal of Experimental Psychology
H
Psychological Bulletin
I
Psychological Review
J
Psychometrika
есть статистика перекрестных ссылок (в течении одного года)
A
B
C
D
E
F
G
H
I
J
A
122
4
1
23
4
2
135
17
39
1
B
23
303
9
11
49
4
55
50
48
7
C
0
28
84
2
11
6
15
23
8
13
D
36
10
4
304
0
0
98
21
65
4
E
6
93
11
1
186
6
7
30
10
14
F
6
12
11
1
7
34
24
16
7
14
G
65
15
3
33
3
3
337
40
59
14
H
47
108
16
81
130
14
193
52
31
12
I
22
40
2
29
8
1
97
39
107
13
J
2
0
2
0
0
1
6
14
5
59
провести анализ схожести интересов журналов.
Задача 3.
Для кирилического алфавита легко различить три «чистых» группы букв, состоящих из остроугольных элементов (К, У, М. Л, А, И),
из прямоугольных элементов (И, П, Д, Т, Г, Е), из круглых элементов (О, С), и одну «смешанную», состоящую из букв, включающих элементы
двух типов—прямые и круглые (Б, В, Р).
На этой основе оцените степень несхожести букв и проведите их шкалирование.