Прежде всего, что такое информационный поиск. Под этим термином традиционно понимается процесс нахождения, отбора и выдачи информации
(в том числе - документов, их частей и/или данных) из массивов и записей любого вида в соответствии с информационной потребностью, выраженной
в форме информационного запроса.
Важной особенностью информационного поиска является то, что результатом его работы является не факт извлечения документов, а то, что он
информирует пользователя только о существовании и местонахождении документов, относящихся к его запросу.
При информационном поиске используются разнородные критерии и, в частности:
Критерий соответствия [match criterion] - Признак или совокупность признаков, по которым определяется степень соответствия между запросом или
поисковым предписанием и поисковым образом документа, самим документом или записью его части для принятия решения о выдаче или не выдаче
конкретного документа на информационный запрос, обрабатываемый системой.
Критерий смыслового соответствия, критерий релевантности (документов, данных) [relevansy criterion] - Признак или совокупность признаков,
по которым определяется степень смыслового соответствия между содержанием поискового предписания и поискового образа документа, самим документом
или записью его части для принятия решения о выдаче или не выдаче конкретного документа на информационный запрос, обрабатываемый системой.
Критерий формального соответствия [formal match criterion] - Признак или совокупность признаков, по которым определяется степень формального
соответствия между поисковым предписанием и поисковым образом документа, самим документом или записью его части для принятия решения о выдаче или
не выдаче конкретного документа на информационный запрос, обрабатываемый системой.
Релевантность [relevance] - Характеристика степени соответствия смыслового содержания документа, найденного в результате поиска, содержанию
информационного запроса.
Пертинентность [pertinence] - Характеристика степени соответствия документа или данных, найденных в результате поиска, информационной
потребности пользователя, выраженной в его запросе.
Точность поиска, коэффициент точности поиска/выдачи [precision ratio, accuracy ratio, precision coefficient, accuracy coefficient] -
Количественная характеристика результатов информационного поиска. Точность поиска определяется путем деления количества выданных в результате
выполнения поиска релевантных документов на общее число выданных документов (релевантных и не релевантных).
Коэффициент информационного шума, коэффициент шума [noise, noise ratio, noise coefficient] - Количественная характеристика информационного
поиска. Коэффициент информационного шума (ИШ) определяется путем деления количества выданных в результате выполнения поиска нерелевантных
документов (см. релевантность ) на общее число выданных документов (релевантных и не релевантных). Будучи выраженным в процентах, ИШ = 100%;- ТП=0.
Полнота поиска, коэффициент полноты поиска [recall, recall ratio, recall coefficient] - Количественная характеристика результатов
информационного поиска, которая определяется путем деления количества выданных в результате выполнения поиска релевантных документов на общее
число релевантных документов, имеющихся в информационно-поисковой системе (выданных и не выданных).
Коэффициент потерь [losses coefficent] - Количественная характеристика результатов информационного поиска.
Коэффициент потерь (КП) определяется путем деления количества не выданных в результате выполнения поиска релевантных документов на общее число
релевантных документов, имеющихся в информационно-поисковой системе (выданных и не выданных). Будучи выраженным в процентах, КП = 100% - полнота
поиска.
Оперативность (время) поиска [seek time].
В данном разделе рассмотрим малую часть из того, что перечислено выше. Прежде всего, это общие принципы организации информационного поиска и задачу
ранжирования (упорядочивания результатов информационного поиска в локальных хранилищах). Те или иные методы организации поиска и ранжирования в глобальной
сети Интернет нас интересуют только с точки зрения общего интереса (поэтому мы и рассмотрим лишь основные принципы). Разработкой и практической реализацией таких методов занимаются специалисты,
обслуживающие поисковые системы, вот пусть они ими и занимаются.
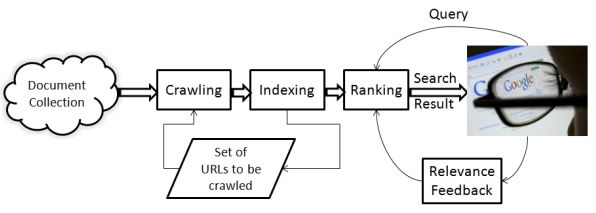
Общий принцип реализации информационного поиска.
Компоненты информационно-поисковой системы.
Основные функции поиска информации.
Сканирование или краулинг. Система просматривает хранилище документов и извлекает информацию о них.
Индексирование документов с целью ускорения поиска.
Формирование информационного запроса пользователем.
Система, используя имеющийся индекс, ищет документы, относящиеся к запросу и, после построения рейтинга найденных документов, отображает полученный
список для пользователя.
Пользователь может дать отзыв о релевантности полученного результата поисковой системе, результатом чего будет обратная связь по релевантности.
Целью любой информационно-поисковой системы является удовлетворение потребностей пользователя в информации.
К сожалению, характеристика потребности пользователей не проста. Часто запрос - это лишь смутное и неполное описание потребности в информации.
Результаты этого раздела любезно предоставлены С.Л. Сотником
(тех. директор Iveonik Systems, г.Каменское).
В процессе деятельности компании Iveonik Systems, возникла задача извлечения текстовой информации из произвольного набора страниц сайтов.
Данный процесс известен также под названием краулинга (crawling). Программный компонент, осуществляющий обход сайта, далее будет называть
краулером (crawler). Краулер является весьма важной составляющей частью таких сложных и известных программных комплексов, как поисковые
сервисы Google, Yahoo, Bing, Яндекс.
Одним из требований к краулеру является требование о поддержании информации о сайте в максимально релевантном состоянии.
Это несложно для относительно небольших сайтов. Но реалии таковы, что зачастую краулеру не удается обойти сайт «в один присест».
Это может происходить по разным причинам - небольшой канал у сайта, перегрузка сайта посетителями, огромные размеры сайта.
Наконец, есть сайты, которые настолько «живые», что даже за несколько минут их содержимое (на некоторых страницах) может существенно
измениться. Все это приводит к тому, что полученная при акте краулинга сайта информация оказывается неполной, либо неактуальной.
Рассмотрим задачу краулинга как задачу получения максимального количества информации при ограничении ресурсов.
Интуитивно понятно, что краулер может закачать и обработать за определенный промежуток времени конечное количество информации.
Это и есть тот самый ограниченный ресурс. Однако вопрос, как измерить практическую ценность добытой информации,
является уже не столь интуитивным. Будем считать, что информационная ценность страницы зависит от количества символов в её текстовом
представлении. Чем больше символов, тем более информативна страница.
С другой стороны, для человека зачастую очень длинные страницы имеют ценность, не пропорциональную их длине.
Попытаемся отразить это, используя логарифмическую меру:
\[
I(i)=\log\left(ActualSize(i)-DeletedSize(i)\right).
\]
Здесь ActualSize – размер актуального контента (который был в версии, сохраненной в индексе и имеется в существующем контенте),
DeletedSize – суммарный размер контента, который отсутствует в текущей версии, но был в индексированной, либо наоборот.
Суммарную же информационную емкость индекса мы можем оценить как:
\[
Q(j)=\sum_{i=0}^{N(j)}I(i).
\]
Здесь Q(j) – суммарная стоимость (цена) индекса для сайта j. N(j) – множество документов сайта (в том числе, удаленных сейчас).
Примем, что на проверку каждой страницы нам необходимо время:
\[
T(i)=A\times size(i)+B.
\]
Здесь A – коэффициент временных расходов, зависящих от размера документа (страницы), а B – накладные расходы на установление соединения и
другие операции, не зависящие от размера.
Теперь мы готовы описать задачу краулинга, как задачу максимизации информационной стоимости индекса при ограниченных временных ресурсах:
\[
Q(j)\to \max \sum T\lt T_{max}; \Delta t(0)\equiv const.
\]
Здесь мы также положили, что время между запусками краулера представляет собой константу. Т.е., расходы на индексацию сайта гораздо меньше,
чем расходы на индексацию всего множества сайтов, обрабатываемых краулером.
Предлагаемый алгоритм оптимизации обхода (названный S.C.E.N.T.) немного навеян муравьиными алгоритмами и является самоорганизующимся.
Каждая страница наделяется свойством "запаха" (scent). Проверка страницы уменьшает запах в 2 раза.
При этом, если "паучком"-краулером был собран "урожай" (информация), то запах страницы увеличивается на величину, пропорциональную "урожаю".
На каждом шаге выбираются страницы, у которых "запах" был самым сильным. После каждого шага, каждой странице (не только проверенные)
добавляется DeltaS единиц запаха. На псевдокоде это можно описать следующим образом:
Основной вопрос, который сейчас исследуется - характер оценочной функции (CalcInfo) и значение константы DeltaS,
от которой зависит характер обхода в случае, если сайт невозможно обойти за один "присест".
DeltaS=0 - Страницы, которые несколько раз оказались неизмененными, перестанут обходиться. DeltaS\(\to\infty\) -
Сайт будет обходиться равномерно, невзирая на то, что часть страниц изменяется чаще, часть - реже.
Оптимальное значение DeltaS, разумеется, находится где-то посредине. Эксперименты показывают, что при хорошо подобранных настройках,
данный алгоритм дает \(Q(j)\) до 98% от максимально возможной (для сайтов со статической и динамической составляющей).
Под термином ранжирование (построение рейтинга), как правило, понимают процесс выборки поисковой машиной документов из базы данных и упорядочивание их по степени
соответствия с информационным (поисковым) запросом.
Существует понятие текстового ранжирования и ранжирования по гипертекстовыми ссылками.
В первом случае поисковой машиной учитываются такие факторы как, например, плотность ключевых фраз в текстах статей (документов),
оформление заголовков. При ранжировании по гипертекстовыми ссылками принимаются во внимание ссылки на сайт с других ресурсов.
В основе большинства алгоритмов ранжирования документов лежит идея TF * IDF, которая учитывает частоту использования ключевых слов в текущем
документе и в других документах корпуса. Кроме того, среди использованных параметров могут быть
выделение ключевых слов тегами и их расстояние от начала документа;
размер документа;
количество пар слов, которые идут подряд в запросе и в таком же виде встречаются в тексте;
число ключевых слов из запроса, которые вообще встречаются в тексте;
встречается ли весь запрос в тексте и др.
Существующие методы ранжирования документов достаточно механистические и часто опираются на формальный вид документов, подлежащих
ранжированию. В случае, если документ представлен малым количеством ключевых слов и отсутствует возможность полнотекстового поиска,
используются модификации TF * IDF или PCA и прочее.
Классика жанра - алгоритм Google PageRank и его обобщения.
Алгоритм Google PageRank, разработанный в 1998 году аспирантами Стэнфордского университета Сергеем Брином и Ларри Пейджем (Larгy Page)
представляет собой тот трамплин, который позволил вывести Google в лидеры IT-корпораций. Поэтому, несмотря на то, что
еще в октябре 2014 года Джон Мюллер (John Mueller - ведущий аналитик компании Google) сообщил, что Google больше не будет обновлять PageRank,
последний апдейт которого состоялся в декабре 2013-го, и с начала 2016 года проект PageRank окончательно закрыт, есть смысл на нем остановиться.
Все же классика.
Ссылочное ранжирование (PageRank) представляет собой вариацию на тему индекса цитируемости. Значение PageRank лежит в пределах от нуля до десяти и
чем больше это значение, тем более высокий рейтинг у данного сайта. Критерием PageRank является количество обратных ссылок.
Значение PageRank (PR) определяется согласно соотношению
\[
PR=(1-d)+d\sum_{i=1}^n\frac{PR_i}{C_i},
\]
где \(PR\)-PageRank данного сайта, \(d-\) коэффициент демпфирования, который в классической постановке равен 0.85 (вероятность перехода по одной из ссылок,
имеющихся на текущей странице), \(PR_i\)-PageRank \(i-\)й страницы, ссылающейся на данный сайт, \(C_i-\) общее число ссылок на \(i-\)й странице.
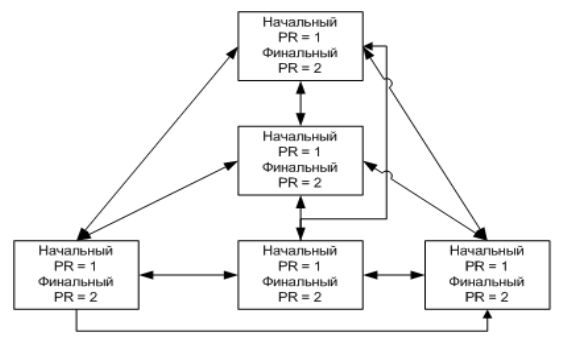
Рассмотрим модельную ситуацию. Пусть есть главная станица, с которой связаны еще две страницы A и B. Стартовые значения PageRank у каждой из них равны единице.
Ссылка со страницы В на страницу А повышает PageRank страницы А до двух, аналогично, переход на В повышает рейтинг В. Если добавляем страницу С и
связываем ее с предыдущими, то PageRank страницы А снизится с двух до полтора, в то время, как у страницы С повысится с одного до полтора.
Добавление дополнительных ссылок ничего не изменит.
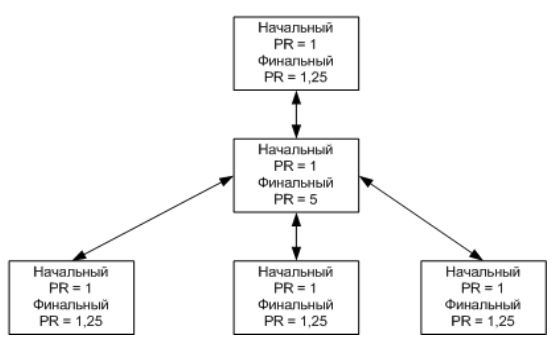
Теперь рассмотрим следующую конструкцию - сайт имеет главную страницу, страницу-каталог и три страницы, посвященные разной продукции.
Нетрудно видеть, что связь каждой страницы между собой даст странице-каталогу PageRank=2.
А связь всех страниц через страницу-каталог приведет к тому, что у этой страницы PageRank=5.
Итак, время алгоритма Google PageRank прошло, что дальше?
Google Panda выход - 23 февраля 2011 года.
Главной задачей этого алгоритма является очистка рейтинга от сайтов низкого качества. Как достигается эта цель?
Panda учитывает объем контента на странице и его обновляемость. Таким образом приоритет дается объемным часто обновляемым интернет-ресурсам.
Google Penguin выход - 24 апреля 2012 года.
Целью алгоритма является подавление сайтов с неестественными обратными ссылками.
Это могут быть сайты с ссылками из «ссылочных ферм» или других платных ссылок,
множество ссылок с сайтов, которые не имеют отношения к веб-сайту, ссылки на
низкокачественные сайты, и ссылки, которые неестественно оптимизированы ключевыми
словами. Кроме того, санкции фильтра Google Penguin можно получить за дублирование
контента и большое количество рекламы на главной странице.
Google Hummingbird выход - 26 сентября 2013 года.
Алгоритм Колибри был разработан для того, чтобы лучше понимать запросы
пользователей. Если ранее Google возвращал результаты, которые были
сосредоточены на ключевых словах, содержащихся в вопросе, то Hummingbird анализирует
вопрос, определяя его цель или смысл, а затем дает соответствующие ответы.
Например, если пользователь вводит запрос «Где можно вкусно поесть», поисковая система понимает, что под словом «где» пользователь подразумевает
рестораны и кафе.
Google Pigeon выход - 24 июля 2014 года.
Целью обновления является улучшение качества обработки локальных запросов путем предоставления пользователям более релевантных результатов.
В этом случае Google, опираясь на Google Maps, использует такие факторы, как местоположение и расстояние.
Google RankBrain выход - 26 октября 2015 года.
Данный алгоритм основан на механизме обучения с использованием нейронных сетей. Возможности его туманны.
Алгоритм ранжирования Yandex.
В основе построение рейтинга Yandex лежит следующее соотношение
\[
Score=W_{single}+W_{pair}+k_1\times W_{AllWords}+k_2\times W_{Phrase}+k_3\times W_{HalfPhrase}
\]
где \(W_{single}\)- вклад слов из запроса в документе,
\(W_{pair} -\) вклад пар слов из запроса в документе,
\(W_{Phrase} -\) вклад текста запроса в целом,
\(W_{AllWords} -\) вклад всех слов из запроса.
Детальнее,
Вклад слова из запроса
\[
W_{single}=\log(p)\times (TF_1+0.2\times TF_2)
\]
где
\[
TF_1=\frac{TF}{TF+k_1+k_2\times DocLength},k_1=1,k_2=\frac{1}{350},
TF_2=\frac{Hdr}{1+Hdr},
p=1-\exp\left(-1.5\times\frac{CF}{D}\right).
\]
Здесь
TF-число вхождений лексемы (слова) в документ,
DocLength - длина документа в словах,
Hdr - сумма весов слова за форматирование,
CF-количество вхождений лексемы слова в коллекцию,
D- количество документов в коллекции.
Учет пар слов.
\[
W_{pair}=0.3\times\left(\log{p_1}+\log{p_2}\right)\times\frac{TF}{1+TF},
\]
\(p_1,p_2\) те же, что и для \( W_{single}\).
Учет всех слов.
\[
W_{AllWords}=0.2\times\sum{\log{p_i}\times 0.03^{N_{miss}}}
\]
где \(N_{miss}-\) число слов запроса, которые отсутствуют в документе.
Учет запроса в целом
\[
W_{Phrase}=0.1\times\sum{\log{p_i}\times \frac{TF}{1+TF}}.
\]
Учет части запроса
\[
W_{HalfPhrase}=0.02\times\sum{\log{p_i}\times \frac{TF}{1+TF}}.
\]
Периодичность и масштабы обновлений контента. Добавление или удаление целых разделов является более значимым обновлением, чем
изменение порядка нескольких слов.
Наличие ключевого слова в первых сто словах содержимого страницы является значимым сигналом релевантности.
Изображения, видео и другие мультимедийные элементы могут выступать в качестве критерия качества контента.
Наличие страницы с обратной связью - «Свяжитесь с нами». Google предпочитает сайты с контактной информацией.
HTML ошибки/WC3 валидация. Большое количество HTML ошибок или некачественно написанный код, являются фактором низкого качества сайта,
что может сказаться на его рейтинге.
Еще несколько маленьких хитростей, позволяющих повысить рейтинг вашего сайта можно найти, например,
здесь.
Хотя, в некоторых случаях можно сделать проще - устанавливаем плагин WP PostRatings,
который отвечает за вывод звездочек и оценку постов. Немного фантазии и вуаля! Получаем желанный рейтинг!
Ранжирование документов по информационному запросу.
Рассмотрим несколько методов построения рейтинга документов, выбранных по информационному запросу.
В разделе "линейный дискриминантный анализ" была рассмотрена конструкция близости документов, представленных как
векторы. В качестве критерия близости использовалось значение косинуса угла между этими векторами.
Для этого случая на первом шаге последовательно обрабатываются все множества словоформ \(b^\nu ,\nu = 0,...,M- 1 \), принадлежащие множеству документов
\(B = \left\{ {b^\nu } \right\}_{\nu =0}^{M - 1} \). По множеству словоформ каждого обрабатываемого текста \(b^\nu \) строится множество
уникальных (неповторяющихся) словоформ и их счетчики -
\(\left( {w_i^\nu ,n_i^\nu } \right)\left( {i = 0,...,N^\nu - 1} \right) \).
Здесь \(N^\nu \)- количество уникальных словоформ для текста \(b^\nu \). После этого данные для каждого множества отдельно нормируются
\[
\overline {n} _i^\nu = \frac{n_i^\nu }{\sqrt {\sum\limits_{j = 0}^{N^\nu - 1}
{\left( {n_j^\nu } \right)^2} } }\left( {i = 0,...,N^\nu - 1} \right).
\]
Затем, упорядочиваем все слова для каждого документа в одном и том же
порядке (сам порядок слов не существенен, главное, чтобы слова в каждой из структур
\(\left( {w_i^\nu ,n_i^\nu } \right)\left( {i = 0,...,N^\nu - 1} \right) \) шли в одном и том же порядке) и находим сумму всех векторов
\(n_i\left( B \right) = \sum\limits_{j = 0}^{M - 1} {\overline {n}_i^\nu } \left(i = 0,...,N\left( B \right) \right)\)
(где \(N(B)- \) количество уникальных словоформ для \(B \) в целом) и нормируем ее единицей
\[
\overline {n}_i\left( B \right) = \frac{n_i\left( B \right)}{\sqrt
{\sum\limits_{j = 0}^{N(B)} {\left(n_j\left( B \right) \right)^2} } }.
\]
В результате каждому документу (в также и информационному запросу) ставится в соответствие единичный вектор, критерием близости документа к информационному запросу будет значение угла между соответствующими векторами.
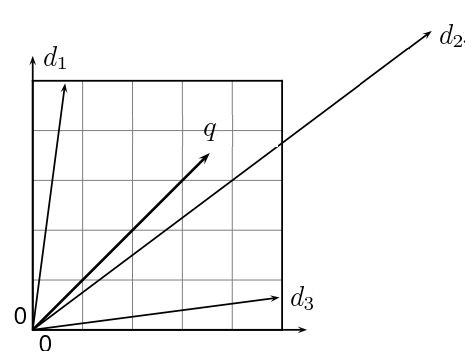
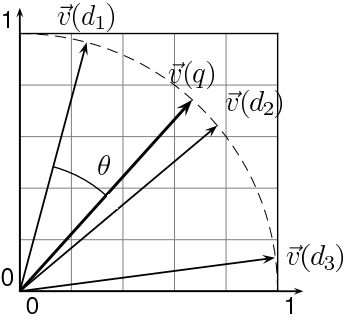
Приведем иллюстрацию, если \(d_i -\) множество документов и \(q -\) информационный запрос
то \(\vec{v}(d_i) -\) нормированный вектор документа \(d_i\) и \(\vec{v}(q) -\) нормированный вектор информационного запроса
Чем меньше угол между вектром информационного запроса и документом, тем более высокий рейтинг у данного документа.
Предложенный метод неэффективен, если слово (словоформа, лексема) из информационного запроса отсутствует в документе, или же используется синоним, например,
"спортсмен"-"атлет", "приближение"-"аппроксимация" и пр. В этом случае используется семантический поиск, что существенно усложняет алгоритм.
J.Rocchio (Rocchio J. Relevance Feedback in Information Retrieval, in Salton / J. Rocchio // The SMART Retrieval System: Expriments in Automatic
Document Processing .− Prentice-Hall, 1971 .− Chapter 14 .− P. 313-323) для решения задачи автоматической классификации объектов аэрокосмической
съемки, предложил алгоритм TF-IDF (term frequency / inverse document frequency).
По сути, TF-IDF - статистическая мера, используемая для оценки важности слова в контексте документа, являющегося частью коллекции документов или корпуса. Вес некоторого слова пропорционален количеству использований этого слова в документе и обратно пропорционален частоте использования слова в других документах коллекции.
Мера TF-IDF часто используется в задачах анализа текстов и информационного поиска, например, как один из критериев релевантности документа поисковому запросу, при расчёте меры близости документов при кластеризации.
TF (term frequency — частота слова) — отношение числа вхождения некоторого слова к общему количеству слов документа.
Таким образом, оценивается важность слова \(t_i\) в пределах отдельного документа \(d\)
\[
TF(d,t_i)=\frac{n_i}{\sum_{k}n_k},
\]
где \(n_i\) есть число вхождений слова \(t_i\) в документ, а в знаменателе — общее число слов в данном документе.
IDF (inverse document frequency — обратная частота документа) — инверсия частоты, с которой некоторое слово \(t_i\) встречается в документах коллекции. Учёт IDF уменьшает вес широкоупотребительных слов
\[
IDF(t_i)=\log\frac{|D|}{|d\supset t_i|},
\]
где \(|D|\) — количество документов в корпусе; \(|d\supset t_i|\) — количество документов, в которых встречается \(t_i\) (когда \(n_i\ne 0\)).
Таким образом, мера TF-IDF является произведением двух сомножителей: TF*IDF. Большой вес в TF-IDF получат слова с высокой частотой в пределах конкретного документа и с низкой частотой употреблений в других документах.
С точки зрения теории информации, если словоформа \(t_i\) встречается в \(n_i\) документах среди всех \(N\) документов, то \(t_i\) будет
в случайно выбранном документе с вероятностью \(n_i/N\). Таким образом, доля информации, содержащейся в утверждении «документ \(d\) содержит слово
\(t_i\)» равна
\[
-\log\frac{n_i}{N}=\log\frac{N}{n_i}.
\]
Таким образом, если \(q=\{t_i\}\) - информационный запрос, состоящий из словоформ \(t_i\), то критерием близости информационного
запроса к документу \(d\), может служить значение
\[
score(q,d)=\sum_{t\in q}IDF(t)\times \frac{TF(d,t)}{|d|},
\]
где \(|d|\) - количество слов (словоформ, лексем) в документе \(d\).
Алгоритм Okapi BM25 – модификация TF-IDF.
BM25 – представляет собой обобщение TF-IDF, полученное Стивеном Робертсоном и Кареном Спарк Джоунсом еще в 1994 году.
Приведем расчетные формулы:
\[
TF(d,t_i)=\frac{n_i*(k_1+1)}{n_i+k_1*\left(1-b+b*\frac{\sum_{k}n_k}{avDoc}\right)},
\]
где, как и ранее, \(n_i\) число вхождений слова \(t_i\) в документ \(d\), \(\sum_{k}n_k\) — общее число слов в данном документе \(d\) и
\(avDoc\) - средняя длина документа в корпусе, а \(k_1\) и \(b\) — свободные коэффициенты, чаще всего выбираются \(k_1=2, b=0.75\).
\[
IDF(t_i)=\log\frac{|D|-|d\supset t_i|+0.5}{(|d\supset t_i|+0.5)},
\]
и функция качества
\[
score(q,d)=\sum_{t\in q}IDF(t)\times TF(d,t).
\]
Основной вопрос вероятностного ранжирования состоит в следующем: «Какова вероятность того, что документ является релевантным с учетом данного запроса?»
Здесь предполагается, что релевантность документа относительно информационного запроса не зависит от других документов в коллекции.
Таким образом, вероятностный принцип ранжирования состоит в следующем:
Если ранжирование документа в коллекции проводится в порядке убывания вероятности релевантности относительно информационного запроса,
то вероятности оцениваются точно так же.
Формально, учитывая документ \(d\) и запрос \(q\), мы оцениваем документ согласно вероятности того, что этот документ является релевантным
\(P(R=1|d,q)\), где \(R\) - случайная величина, принимающая значение 1, если \(d\) является релевантным относительно \(q\) и значение 0,
в противном случае.
Таким образом, если мы выбираем документы, наиболее подходящие к информационному запросу, то эти документы должны удовлетворять условию
\[
P(R=1|d,q)\gt P(R=0|d,q).
\]
Положим
\[
RF()=\frac{P(R=1|d,q)}{P(R=0|d,q)}.
\]
Используя теорему Байеса, получаем
\[
RF()=\frac{\frac{P(R=1|q)P(d|R=1,q)}{P(d|q)}}{\frac{P(R=0|q)P(d|R=0,q)}{P(d|q)}}=
\frac{P(R=1|q)}{P(R=0|q)}\times \frac{P(d|R=1,q)}{P(d|R=0,q)}.
\]
Так как первая дробь от документа не зависит, то
\[
RF()= \frac{P(d|R=1,q)}{P(d|R=0,q)}=
\frac{P(t_1|R=1,q)\cdot P(t_2|t_1,R=1,q)\cdots P(t_m|t_1\cdot t_{m-1},R=1,q)}
{P(t_1|R=0,q)\cdot P(t_2|t_1,R=0,q)\cdots P(t_m|t_1\cdots t_{m-1},R=0,q)}=
\prod_{i=0}^m\frac{P(t_i|t_1\cdots t_{i-1},R=1,q)}{P(t_i|t_1\cdots t_{i-1},R=0,q)},
\]
где \(m -\)количество слов информационного запроса.
Если считать, что если выпадение каждого слова является независимой случайной величиной (наивное Байесовское предположение), то получаем
\[
RF()= \prod_{i=0}^m\frac{P(t_i|R=1,q)}{P(t_i|,R=0,q)}.
\]
Пусть
\[
x_t=\left\{
\begin{array}{ll}
1, & \hbox{ если \(t\in d\);} \\
0, & \hbox{ если \(t\neq d\).}
\end{array}
\right.
\]
Тогда
\[
RF()= \prod_{t:x_t=1}\frac{P(t|R=1,q)}{P(t|,R=0,q)}\cdot \prod_{t:x_t=0}\frac{P(t|R=1,q)}{P(t|,R=0,q)}.
\]
Пусть \(p_t=P(t|R=1,q)\)- вероятность того, что слово \(t\) будет в релевантном документе, и \(u_t=P(t|R=0,q)\) - вероятность того,
что слово \(t\) будет в нерелевантном документе, тогда
\[
RF()= \prod_{t:x_t=1}\frac{p_t}{u_t}\cdot \prod_{t:x_t=0}\frac{1-p_t}{1-u_t}.
\]
Сделаем еще одно предположение - пусть слова, отсутствующие в информационном запросе могут появиться в любом
документе (\(y_t=1\)), то есть они никаким образом не влияют на релевантность относительно информационного запроса, тогда
\[
RF()= \prod_{t:x_t=y_t=1}\frac{p_t}{u_t}\cdot \prod_{t:x_t=0,y_t=1}\frac{1-p_t}{1-u_t}=
\prod_{t:x_t=y_t=1}\frac{p_t(1-u_t)}{u_t(1-p_t)}\cdot \prod_{t:[x_t=0\vee 1],y_t=1}\frac{1-p_t}{1-u_t}.
\]
Тогда, учитывая, что последнее произведение от \(x_t\) не зависит, переопределим RF()
\[
RF()= \prod_{t:x_t=y_t=1}\frac{p_t(1-u_t)}{u_t(1-p_t)}.
\]
Далее, прологарифмируем это соотношение, снова переопределив RF()
\[
RF()= \log\prod_{t:x_t=y_t=1}\frac{p_t(1-u_t)}{u_t(1-p_t)}=
\sum_{t:x_t=y_t=1}\log\frac{p_t(1-u_t)}{u_t(1-p_t)}=
\sum_{t:x_t=y_t=1}\log\frac{p_t}{1-p_t}+\log\frac{1-u_t}{u_t}=\sum_{t:x_t=y_t=1}c_t.
\]
Таким образом, \(c_t\)- логарифм отношения вероятности того, что слово \(t\) будет в релевантном документе, к
вероятности того, что \(t\) попадет в нерелевантный документ.
Найдем оценку \(c_t\). Пусть \(N\) общее число документов, \(R-\) общее число релевантных документов, \(r_t\) число релевантныхдокументов, содержащих
слово \(t\) и \(n_t\) количество документов, в которых встречается слово \(t\).
Документ
Релевантный
Нерелевантный
Всего
Слово присутствует
\(x_t=1\)
\(r_t\)
\(n_t-r_t\)
\(n_t\)
Слово отсутствует
\(x_t=0\)
\(R-r_t\)
\((N-n_t)-(R-r_t)\)
\(N-n_t\)
Всего
\(R\)
\(N-R\)
\(N\)
Тогда
\[
p_t=\frac{r_t}{R},u_t=\frac{n_t-r_t}{N-R}
\]
и
\[
c_t=\log\frac{r_t(N-n_t-R+r_t)}{(R-r_t)(n_t-r_t)}.
\]
Чтобы избежать нулей (слово присутствует/отсутствует в каждом документе), применим сглаживание, прибавив константу, в нашем случае это 0.5
\[
c_t=\log\frac{(r_t+0.5)(N-n_t-R+r_t+0.5)}{(R-r_t+0.5)(n_t-r_t+0.5)}.
\]
В случае, если информация о релевантности отсутствует, положим \(p_t=0.5\), тогда \(c_t\) зависят только от \(u_t\).
Считая, что слова в нерелевантных документах распеределены равномерно, то есть \(u_t\approx n_t/N\), получаем
\[
c_t\approx \log\frac{0.5}{1-0.5}+\frac{1-\frac{n_t}{N}}{\frac{n_t}{N}}=\log\frac{N-n_t}{n_t}.
\]
А так как \(n_t\) по отношению к общему числу документов \(N\), достаточно мало, то
\[
c_t\approx \log\frac{N}{n_t}.
\]
Заметим, что в этом случае критерий ранжирования совпадает с IDF.
Рассмотрим метод построения текстового ранжирования имеющегося корпуса документов в соответствии с информационным вкладом в них
составляющих информационного запроса.
Пусть имеется корпус документов, каждый из которых определен частотным словарем словоформ, входящих в него
\(D_k=\left\{w^k_i:n^k_i\right\} (k=1,...,N)\), а через \(S=\{s_i\}\) обозначим информационный запрос.
Нужно провести ранжирование корпуса документов \(\{D_k\}_{k=1}^N\) в соответствии с информационным запросом \(S\).
В основе предложенного метода ранжирования лежит идея использования изменения значения энтропии при объединении документов.
Отметим, что такого рода конструкции используются при решении оптимизационных задач теории информации, например,
при построении деревьев решений С4.5 и др.
В дальнейшем нам потребуются следующие понятия:
В качестве меры неопределенности случайного объекта (системы) \(A\) с конечным множеством возможных состояний \(A_1,A_2,...,A_n\)
и соответствующей вероятностью выпадения \(p_1,p_2,...,p_n\), Клод Шеннон предложил использовать функционал
\[
H(A)=H(p_1,...,p_n)=-\sum_{k=1}^np_k\log{p_k},
\]
называемый информационной энтропией. Логарифмы берутся при произвольному основанию, но в случае, если за единицу измерения степени
неопределенности принять неопределенность, содержащуюся в опыте с ровно двумя вероятными результатами (например, присутствует элемент
в некотором множестве или отсутствует), то следует брать основание равным двум. Отметим, что при заданном \(n\) величина энтропии
максимальна и равна \(\log{n}\) лишь в случае, когда все \(p_i\) равны между собой, то есть \(p_1=p_1=...=p_n=\frac{1}{n}\).
Таким образом
\[
H(D_k)=-\sum_{i=1}^{N_i}\frac{n_i^k}{N_k}\log_2\frac{n_i^k}{N_k},
\]
где \(N_k\)- общее число словоформ в документе \(D_k\), а \(n_i^k=num(w_i^k)\)- число вхождений словоформы \(w_i^k\) в данном текущем
документе (\(num (s)\) - число вхождений слова \(s\)).
Для двоичного случае, в случае, если среди \(n\) состояний системы \(A\) имеются \(m\), которые обладают некоторым свойством \(V\),
то энтропия по отношению к свойству \(V\) будет равна
\[
H(A,V)=-\frac{m}{n}\log_2\frac{m}{n}-\frac{n-m}{n}\log_2\frac{n-m}{n}.
\]
Если использовать некий атрибут \(Q\), который имеет \(q\) значений, то необходимо определить прирост информации, который измеряет
ожидаемый уровень энтропии (разницу между информацией от \(A\) и информацией, необходимой для определения элемента из \(A\) после
того, как значение атрибута \(Q\) было определено, то есть, прирост информации благодаря атрибуту \(Q\)):
\[
G(A,Q)=H(A)-\sum_{j=1}^q\frac{|A_j|}{|A|}H(A_j,V),
\]
где \(A_j\)- множество состояний \(A\), для которых атрибут \(Q\) принимает \(i\)-е значение, а \(|X|\) - число элементов множества
\(X\).
Для нашего случая, величина энтропии документа \(D_k\) относительно слова \(s_i\) из информационного запроса \(S\) будет равна
\[
H(D_k,s_i)=-\frac{num(s_i)}{N_k}\log_2\frac{num(s_i)}{N_k}-\frac{N_k-num(s_i)}{N_k}\log_2\frac{N_k-num(s_i)}{N_k}.
\]
Величина прироста энтропии будет равна
\[
H(D_k,S)=H(D_k)-\sum\left\{\left.\frac{num(s_i)}{N_k}H(D_k,s_i)\right|s_i\in S\right\}.
\]
Чем больше будет значение прироста энтропии, тем больше наш документ будет отличаться от информационного запроса.
С другой стороны, значение энтропии зависит от количества состояний системы (в нашем случае от количества словоформ, которые описывают документ), поэтому для ранжирования нам надо определение не абсолютного значения изменения значения энтропии, а относительного, то есть
\[
\bar{H}(D_k,S)=\frac{1}{H(D_k)}\left(H(D_k)-\sum\left\{\left.\frac{num(s_i)}{N_k}H(D_k,s_i)\right|s_i\in S\right\}\right),
\]
которое позволяет оценить снижение уровня энтропии документа, если известна информация о ключевых словах
(составляющих информационного поиска). Значение \(\bar{H}(D_k,S)=1\) указывает на тот факт, что данный документ \(D_k\) никакого
отношения к данному информационному запросу не имеет, то есть информация \(s_i\in S\) не меняет общий объем информации об \(D_k\),
и чем меньше значение \(\bar{H}(D_k,S)\), тем меньше степень неопределенности \(D_k\) относительно \(S\).
Рассмотрим пример.
№
Документ
Описание документа
1
Васильев Ф.П. "Методы оптимизации"
оптимизация, функция, минимизация, дифференциальные уравнения, численные методы
2
Корнейчук Н. П., Лигун А. А., Доронин В.Г. "Аппроксимация с ограничениями"
Лебедев П. Д., Ушаков А. В. "Аппроксимация множеств на плоскости оптимальными наборами кругов"
сеть, круг, аппроксимация, кривая, многоугольник
6
Бляшке В. "Круг и шар"
круг, слой, минимизация, симметрия
7
Леонтьев В. "Экономические эссе"
круг, интерес, экономика, политика
8
Смит Р. С, Эренберг Р. Дж. "Coвременная экономика труда"
труд, политика, экономика
Добавим к описанию документа словоформы из названия документа и получим для каждого документа частотный словарь.
После вычисления значения энтропии получим
В качестве примера информационного запроса возьмем текстовую строку «аппроксимация круговым сплайнами», который после
преобразования в словоформы будет иметь вид «аппроксимация, круг, сплайн».
Далее найдем количество информации, необходимой для определения элемента из текущего документа, если известное слово (словоформа)
из информационного запроса.
№
аппроксимация
круг
сплайн
1
0,000000
0,000000
0,000000
2
0,918296
0,000000
0,650022
3
0,863121
0,000000
0,591673
4
0,721928
0,000000
0,000000
5
0,811278
0,811278
0,000000
6
0,000000
0,918296
0,000000
7
0,000000
0,721928
0,000000
8
0,000000
0,000000
0, 000000
Значение 0 показывает, что данное слово в описании документа отсутствует, поэтому никоим образом не влияет на соотношение
текущего документа с данным словом из информационного запроса.
Далее найдем общий объем информации, необходимой для определения элемента из текущего документа по всему множеству
составляющих информационного поиска, затем вычислим абсолютное значение изменения энтропии при условии наличия информации
по составляющим информационного поиска, и, наконец, значение относительного изменения уровня энтропии. По полученным значениям
найдем рейтинг документов относительно данного информационного запроса.
Отметим, что так как данный метод не несет семантической составляющей, то, к сожалению, никак не учитывается общая направленность документа,
поэтому имеет смысл сделать некоторое обобщение алгоритма, формируя новый запрос на основе полученной информации.
В результате наших построений, имеем значение вклада слов информационного поиска в каждый документ \(D_k\), тогда можно считать,
что и другие слова данного документа связанны со словоформам информационного запроса.
Таким образом, вес каждого слова документа (относительно словоформ информационного поиска) может быть рассчитан следующим образом
\[
\bar{W}(D_k,S)=\frac{1}{H(D_k)}\left(\sum\left\{\left.\frac{num(s_i)}{N_k}H(D_k,s_i)\right|s_i\in S\right\}\right),
\]
кроме оригинальных словоформ информационного поиска, вес которых равен 1, то есть
\[
\bar{W}(D_k,s_i)=
\left\{
\begin{array}{ll}
\bar{W}(D_k,S), & s_i\notin S \\
1, & s_i\in S.
\end{array}
\right.
\]
№
1
2
3
4
5
6
7
8
\(\bar{W}(D_k,S)\)
0
0,18406
0,1481
0,06218
0,16226
0,15957
0,07513
0
Общее весовое значение для каждого слова из нового информационного запроса вычислим следующим образом
\[
\bar{W}(s_i)=
\left\{
\begin{array}{ll}
\frac{1}{\sum\left\{1|s_i\in D_k\right\}}\sum\left\{\left.\bar{W}(D_k,S)\right|s_i\in D_k\right\}, & s_i\notin S \\
1, & s_i\in S.
\end{array}
\right.
\]
Сформируем новый информационный запрос, который будет состоять со всех ключевых слов документов корпуса, кроме тех, которые имеют
нулевой рейтинг и найдем относительный прирост энтропии с учетом веса
\[
\bar{H}(D_k,S)=\frac{1}{H(D_k)}\left(H(D_k)-\sum\left\{\left.\bar{W}(s_i)\frac{num(s_i)}{N_k}H(D_k,s_i)\right|s_i\in S\right\}\right),
\]
и уже по данной величине определим рейтинг документов с учетом всей информации, которая входит в корпус и связана с информационным запросом.
Таким образом, рейтинг документов изменился с учетом словоформ расширенного информационного запроса.
Можно вообще снять приоритет словоформ информационного запроса и приравнять права запроса с правами документа.
В этом случае считаем, что на первом этапе мы указали на приоритеты поиска, а на втором позволяем подправить поиск с учетом всех
документов, то есть
\[
\bar{W}(s_i)=\frac{\sum\left\{\left.\bar{W}(D_k,S)\right|s_i\in D_k\right\}}{\sum\left\{1\left|s_i\in D_k\right.\right\}}
\]
для всех словоформ. В этом случае имеем
Поисковая оптимизация сайта, является важным элементом “Semantic WEB”, позволяющая повысить эффективность ведения бизнеса с использованием
возможностей Internet. Одним из узловых элементов поисковой оптимизации является подбор ключевых слов, которые соответствуют продукту или услуг,
размещенных на продвигаемом сайте. Традиционно в выборку ключевых слов включаются, как высокочастотные запросы, так и группы ключевых слов,
которые относятся к низкочастотным запросам. Например, слово «игра» является высокочастотным запросом, а словосочетание «on-line игра-стратегия»
относится к низкочастотным. Ясно, что, несмотря на то, что высокочастотные запросы приводят к большему трафику (количеству заходов клиентов на сайт),
они в целом, неэффективны, так как пришедшие по таким запросам клиенты, не формируют устойчивую целевую аудиторию сайта. Низкочастотные запросы не
могут похвастаться высоким трафиком, однако имеются все предпосылки, что посетители, которые пришли по низкочастотным запросам, приобретут товар
или услугу, предлагаемые на продвигаемом сайте.
Не существует единого универсального метода оптимизации подбора ключевых слов, например, для одностраничного приложения (каковым является, например, on-line игра), нужно использовать такие ключевые слова, которые максимально отражают тему веб-сайта, а для мультистраничного, например, для интернет-магазина, необходимо выбирать такие ключевые слова, которые соответствуют как содержанию каждой отдельной страницы сайта, так и общей теме сайта. Так, страницы с профильным контентом (содержанием) лучше всего оптимизировать узкоспециализированными ключевыми словами, а общие ключевые слова подходят для оптимизации страниц с обобщенным содержанием. При этом главная страница сайта должна быть первой в результатах поиска по отношению к другим страницами сайта, что достигается за счет использования общих и популярных ключевых слов. Остальные страницы сайта оптимизируют по средне- и низкочастотным поисковым запросам.
Рассмотрим задачу прогнозированию рейтинга нового ключевого слова основываясь на статистике существующего множества ключевых слов, описывающих возможности информационного ресурса.
Для описания предложенного алгоритма используются статистические данные компании, разрабатывающей on-line игры.
Традиционно для прогнозирования рейтинга ключевых слов используется следующая схема.
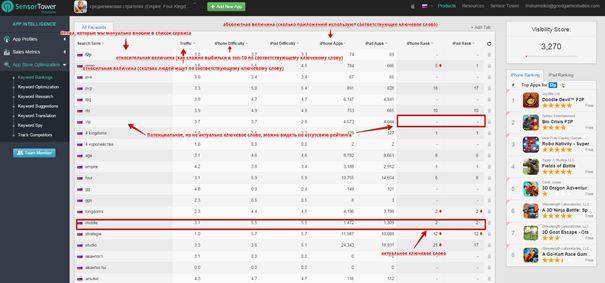
Для получения статистических данных об актуальных ключевых словах и потенциальных ключевых словах используется сервис SensorTower.
Получение статистики ключевых слов от сервиса SensorTower.
Этот сервис так же дает возможность получить отчет по рейтингу за последние 5 недель.
По полученной информации о рейтингах, получаем среднее значение рейтинга за это время. Следующим шагом является получение регрессионной модели,
только по актуальным ключевым словам, так как у них имеется рейтинг (зависимая переменная), как правило, это линейная модель.
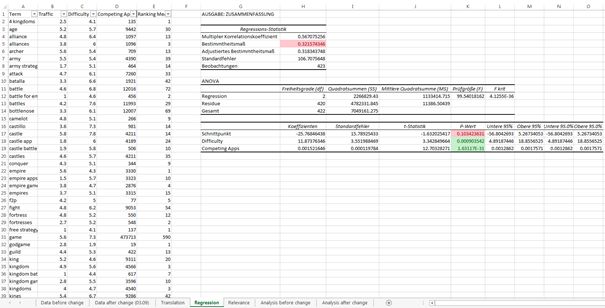
Построение регрессионной модели.
С помощью найденных коэффициентов строится прогноз рейтинга для каждого из потенциальных ключевых слов.
Получение прогноза по линейной регрессионной модели.
Ввиду того, что полученное значение прогноза может выйти за границы шкалы (от 0 до 10), то на следующем шаге проводится нормировка данных и оценка рейтинга по 10-ти бальной шкале.
Получение прогноза по нормированной шкале.
Таким, образом, единственным инструментом, используемым для построения прогноза, является линейная регрессия. Построение регрессионных моделей на сегодняшний день, без всяких сомнений, является наиболее распространенным методом многомерного статистического анализа данных. Подавляющее большинство статей, анализирующих эмпирические данные, основаны на использовании регрессионных моделей. Вместе с тем многие особенности и ограничения регрессионных моделей обычно остаются вне сферы внимания исследователей, что, подчас, приводит к неточным, а иногда, и просто ошибочным результатам.
Применительно к рассматриваемой задаче, традиционная модель множественного линейного регрессионного анализа подразумевает поиск показателей,
определяющих значение отдельной количественной переменной, обозначаемой \(y\) по множеству имеющихся данных
\[
\mathbb{P}=\{P_i(x_i^0,x_i^1,x_i^2,y_i) (i=0,1,…,n)\}.
\]
Структура связи в данной модели предполагается линейной:
\[
y=a^0 x^0+a^1 x^1+a^2 x^2+b
\]
где \(b\) - остаточный член, фиксирующий ту часть информации y, которая не описывается переменными \((x^0,x^1,x^2)\).
Регрессионный анализ показывает, во-первых, качество модели, то есть степень того, насколько данная совокупность \(\mathbb{P}=\{P_i(x_i^0,x_i^1,x_i^2,y_i) (i=0,1,…,n)\}.\)
объясняет \(y\). Показатель качества называется коэффициентом детерминации \(R^2\) и показывает, какой процент информации \(Y=\{y_i\}\)
можно объяснить поведением \(X=\{x_i^0,x_i^1,x_i^2\}\). Во-вторых, регрессионный анализ вычисляет значения коэффициентов \(a^0,a^1,a^2,b\),
то есть определяет, с какой силой каждый из \(X=\{x_i^0,x_i^1,x_i^2\}\) влияет на \(Y=\{y_i\}\).
Методологическим недостатком такого подхода является то, что данная зависимость ищется единой для всей совокупности исходных данных.
Иными словами, предполагаем, что для всех ключевых слов характер зависимости \(Y\) от \(X\) единый.
В том случае, когда выборочная совокупность достаточно однородна, такого рода допущение имеет под собой определенные основания, однако,
если анализируются, малое число «хороших» ключевых слов совместно с большим числом «плохих», то допущение об однородности данных выглядит не
очень убедительным. Единая форма уравнения в этой ситуации сильно огрубляет реальную зависимость, качество модели неизбежно оказывается весьма
низким, а смысл регрессионных коэффициентов, фиксирующих степень влияния множества \(X\) на \(Y\),
будет скорее отражать влияние «плохих» данных, чем «хороших».
Вполне очевидно, что гораздо разумнее строить отдельные модели для существенно различающихся между собой групп данных.
Рассмотрим эту задачу.
В нашем случае прогнозирование рейтинга ключевых слов можно формализовать следующим образом. Даны точки \(P_i (x_i^0,x_i^1,x_i^2,y_i)
(i=0,1,…,n)\), для \((\tilde{x}^0,\tilde{x}^1,\tilde{x}^2 )\) нужно спрогнозировать значение \(\tilde{y}\).
По сути, точки \(P_i (x_i^0,x_i^1,x_i^2,y_i)\) описывают тело, где \((x_i^0,x_i^1,x_i^2)\) – его координаты, а \(y_i\)- плотность.
Для более точного прогноза плотности тела в точке \((\tilde{x}^0,\tilde{x}^1,\tilde{x}^2 )\) нужно использовать те точки \((x_i^0,x_i^1,x_i^2)
(i=0,1,…,n)\), которые лежат наиболее близко к прогнозируемой точке. Поэтому предлагается следующий алгоритм, основанный на том факте,
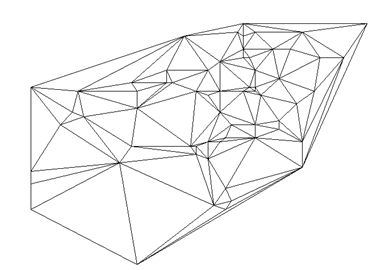
для любого набора точек, существует регулярное (наиболее близкое к правильному) разбиение на симплексы.
Такое симплициальное разбиение названо именем Делоне.
Множеством Делоне назовем множество \(D\subset E^d\), для которого существуют положительные числа \(r\) и \(R\) такие, что для любого открытого
\(d\)-шара \(B_r^0\) и замкнутого шара \(B_R\) радиусов \(r\) и \(R\) соответственно, выполнены неравенства
\(|B_r^0 \cap D|\le 1\) и \(|B_R \cap D|\ge 1\), где \(|Z|\) означает мощность множества \(Z\).
В общем смысле, никакое подмножество этого множества, состоящее из \(d+2\) точек, не лежит на одной \((d-1)\)-сфере.
Другими словами - что понимается под регулярной триангуляцией (под триангуляцией понимаем симплициальное разбиение), - через вершины
невырожденного симплекса (в простейшем случае это невырожденный треугольник, то есть все вершины не лежат на одной прямой) можно провести одну и
только одну сферу. Если триангуляция такова, что внутрь симплекса не попадает ни одна точка разбиения, то такое разбиение будем называть
регулярным (множество Делоне). В этом случае, если точка \((\tilde{x}^0,\tilde{x}^1,\tilde{x}^2 )\) лежит в \(j\)-м симплексе регулярной
триангуляции, то вершины этого симплекса представляют собой точки \((x_i^0,x_i^1,x_i^2,y_i)\) наиболее «плотно» прилегающие к искомой точке
\((\tilde{x}^0,\tilde{x}^1,\tilde{x}^2 )\), и, соответственно, наилучшим образом могут ее описать, то есть прогноз \(y_i\) будет наилучшим
среди всех остальных.
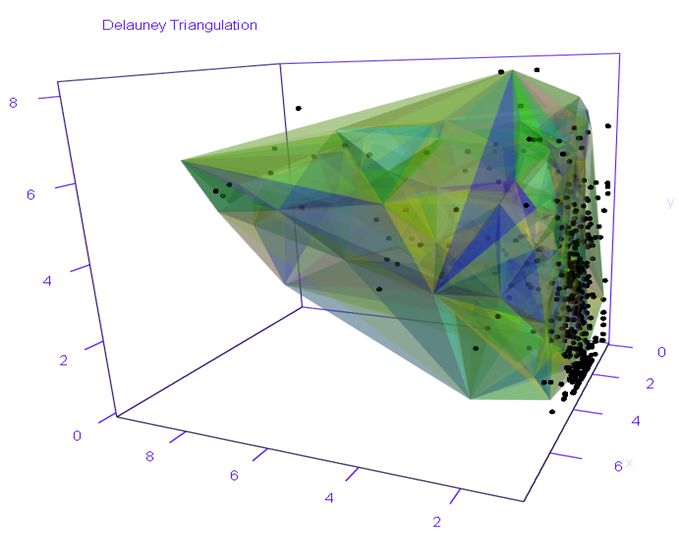
Иллюстрация триангуляции Делоне
Алгоритм. Итак, пусть дана точка \((\tilde{x}^0,\tilde{x}^1,\tilde{x}^2 )\). Найдем четыре точки \((x_i^0,x_i^1,x_i^2)(i=k,k+1,k+2,k+3)\)
такие, что расстояние
\[
\varepsilon_i=\sqrt{\sum_{m=0}^2\left(x^m_i-\tilde{x}^m\right)^2}
\]
наименьшее и все эти точки не лежат на одной плоскости, то есть
\[
\left|
\begin{array}{ccc}
x_{k+1}^0-x_k^0 & x_{k+1}^1-x_k^1 & x_{k+1}^2-x_k^2 \\
x_{k+2}^0-x_k^0 & x_{k+2}^1-x_k^1 & x_{k+2}^2-x_k^2 \\
x_{k+3}^0-x_k^0 & x_{k+3}^1-x_k^1 & x_{k+3}^2-x_k^2 \\
\end{array}
\right|\ne 0.
\]
Проведем через эти точки сферу. Центр сферы \((x^0,x^1,x^2 )\) находится из системы линейных уравнений
\[
(x_{k+1}^0-x_k^0)(x^0-(x_{k+1}^0+x_k^0)/2)+(x_{k+1}^1-x_k^1)(x^1-(x_{k+1}^1+x_k^1)/2)+(x_{k+1}^2-x_k^2)(x^2-(x_{k+1}^2+x_k^2)/2)=0,
\]
\[
(x_{k+2}^0-x_k^0)(x^0-(x_{k+2}^0+x_k^0)/2)+(x_{k+2}^1-x_k^1)(x^1-(x_{k+2}^1+x_k^1)/2)+(x_{k+2}^2-x_k^2)(x^2-(x_{k+2}^2+x_k^2)/2)=0,
\]
\[
(x_{k+3}^0-x_k^0)(x^0-(x_{k+3}^0+x_k^0)/2)+(x_{k+3}^1-x_k^1)(x^1-(x_{k+3}^1+x_k^1)/2)+(x_{k+3}^2-x_k^2)(x^2-(x_{k+3}^2+x_k^2)/2)=0.
\]
А радиус
\[
r^0=\sqrt{\sum_{m=0}^2\left(x^m-x^m_k\right)^2}
\]
Если найдется точка \((x_i^0,x_i^1,x_i^2)(i\ne k,k+1,k+2,k+3)\), которая лежит от центра этой окружности на расстоянии,
меньше радиуса, то ее включаем в список прилегающих точек и строим новые четверки точек, пока не получим такую четверку,
для которой сфера, построенная по этим точкам не будет содержать никакую другую точку. Понятное, что данный алгоритм не нацелен на
построение триангуляции Делоне всего множества данных.
Результатом является только один симплекс, содержащий данную точку \((\tilde{x}^0,\tilde{x}^1,\tilde{x}^2 )\)). Но нам, по большому счету, ничего иного и не нужно.
Любая точка симплекса может быть записана в барицентрических координатах
\[
P=\sum_{m=0}^3\lambda_m P_{k+m}, \hbox{ где } \sum_{m=0}^3\lambda_m=1.
\]
Барицентрические координаты \(\lambda_m (m=0,1,2,3)\) легко найти из системы
\[
x^j=\sum_{m=0}^3\lambda_mx^j_{k+m}(j=0,1,2).
\]
И, наконец, прогноз рейтинга будет равен
\[
\tilde{y}=\sum_{m=0}^3\lambda_my_{k+m}.
\]
Рассмотренная конструкция не дает возможности найти прогноз ключевых слов, не лежащих внутри облака исходных данных,
другими словами, если точка, соответствующая ключевому слову, лежит внутри облака (тела), то прогнозирование ее значения
можно описать термином «интерполяция», а вне – «экстраполяцией».
Для решения задачи экстраполяции данных, сведем ее к интерполяции, с этой целью для точки \(\tilde{P}(\tilde{x}^0,\tilde{x}^1,\tilde{x}^2)\) найдем в
множестве \(\hat{\mathbb{P}}=\{\hat{P}_i(x_i^0,x_i^1,x_i^2,y_i) (i=0,1,…,n)\}\) ближайшую к \(\tilde{P}(\tilde{x}^0,\tilde{x}^1,\tilde{x}^2)\) точку
\(\hat{P}_{i0}(x_{i0}^0,x_{i0}^1,x_{i0}^2)\)
\[
\hat{P}_{i0}=\arg\left\{\min\left\{|\tilde{P}-\hat{P}_i||i=0,1,…,n\right\}\right\}.
\]
Рассмотрим множество \( \tilde{\mathbb{P}}=\left\{\hat{\mathbb{P}}\setminus \hat{P}_{i0}\right\}\cup \tilde{P}\),
то есть, выбросим из множества исходных данных \(\hat{\mathbb{P}}=\{\hat{P}_i(x_i^0,x_i^1,x_i^2,y_i) (i=0,1,…,n)\}\) точку
\(\hat{P}_{i0}(x_{i0}^0,x_{i0}^1,x_{i0}^2)\) и добавим точку \(\tilde{P}(\tilde{x}^0,\tilde{x}^1,\tilde{x}^2)\).
Для полученного множества построим триангуляцию Делоне и выберем симплекс с вершиной в точке \(\tilde{P}(\tilde{x}^0,\tilde{x}^1,\tilde{x}^2)\) внутри которого находится точка P ̂_i0. Такой симплекс существует и он единственный (что следует из теоремы о существовании триангуляции Делоне).
Тогда
\[
\hat{P}_{i0}=\lambda_0\tilde{P}+\lambda_1\hat{P}_{k}+\lambda_2\hat{P}_{k+1}+\lambda_3\hat{P}_{k+2},\hbox{ где }
\sum_{m=0}^3\lambda_m=1,
\]
и, следовательно,
\[
\tilde{P}=\frac{1}{\lambda_0}\left(\hat{P}_{i0}-\lambda_1\hat{P}_{k}-\lambda_2\hat{P}_{k+1}-\lambda_3\hat{P}_{k+2}\right).
\]
Тогда прогноз рейтинга будет равен
\[
\tilde{y}=\frac{1}{\lambda_0}\left(y_{i0}-\lambda_1y_{k}-\lambda_2y_{k+1}-\lambda_3y_{k+2}\right).
\]
Если \(\lambda_0=0\), то точка \(\hat{P}_{i0}\) лежит на гиперплоскости, образуемой точками \(\hat{P}_{k},\hat{P}_{k+1},\hat{P}_{k+2}\),
следовательно из множества \(\hat{\mathbb{P}}\) нужно выбросить точку \(\hat{P}_{i0}\) и начать все заново.
Триангуляция Делоне по множеству ключевых слов.
Разбиение нормированного в единичный куб множества ключевых слов
на регулярные симплексы с учетом плотности каждого симплекса.
В предложенном подходе есть «подводные камни». Ключевые слова, получаемые из сервисной службы, принадлежат разным группам потребителей,
как по национальному, так и по территориальному признаку. Поэтому, одно и то же ключевое слово, набранное в разных странах, будет иметь
разный рейтинг, что приводит к появлению в корпусе ключевых слов большого количества данных, которые можно классифицировать как шум.
Выходом может быть, либо фрагментация статистических данных по тем или иным признакам, либо их фильтрация, позволяющая производить поиск
только на корпусе ключевых слов, которые отражают интерес клиента к нашему ресурсу. С нашей точки зрения, второй подход более
предпочтительный. Для этой цели приведем модификацию под наши задачи алгоритма кластеризации DBSCAN (Density Based Spatial Clustering of
Application with Noise). Идея данного метода основана на гипотезе, что элементы одного кластера формируют область,
плотность объектов внутри которого, по некоторому заданному порогу , превышает плотность за его пределами.
По отношении к нашей задаче, в кластере должна присутствовать некоторая «непрерывность» данных, другими словами,
если точки лежат недалеко друг от друга, то и значения функции в них не должны сильно отличаться.
Итак, пусть дано множество точек \(\mathbb{P}=\{P_i(x_i^0,x_i^1,x_i^2,y_i) (i=0,1,…,n)\}\) и \(\mathbb{S}_r(P_i)\) -сфера с центром в
точке \(P_i\) радиуса \(r\). Через \(M_r (P_i )\) обозначим множество точек из \(\mathbb{P}\), лежащих в сфере \(\mathbb{S}_r(P_i)\),
и пусть \(|M_r (P_i )|\) их количество. Зафиксируем два числа – \(r\) и \(m\) и введем обозначения-
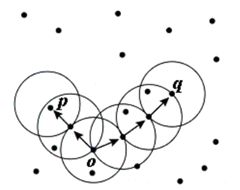
Точку \(P\in\mathbb{P}\) будем называть внутренней точкой кластера \(K_{r,m}\), если \(|M_r (P_i )| \ge m\).
Точка \(\tilde{P}\in\mathbb{P}\) непосредственно достижима по плотности от точки \(P_i\in\mathbb{P}\), если \(\tilde{P}\)
лежит в сфере \(\mathbb{S}_r(P_i)\), то есть \(\tilde{P}\in M_r (P_i )\).
Точка \(\tilde{P}\in\mathbb{P}\) достижима по плотности от точки \(\hat{P}\in\mathbb{P}\), если существует путь
(упорядоченный набор точек) \(\bar{P}_0,\bar{P}_1,...,\bar{P}_k (\bar{P}_i\in\mathbb{P},i=0,1,2,…,k)\), где
\(\bar{P}_0=\tilde{P}\) и \(\bar{P}_k=\hat{P}\),все \(\bar{P}_i\) при \(i=1,2,…,k\) являются внутренними точками кластера и каждая
точка \(\bar{P}_i\) непосредственно достижима по плотности от точки \(\bar{P}_{i+1}\).
Если точка \(\tilde{P}\in\mathbb{P}\) достижима по плотности от внутренней точки \(\hat{P}\in\mathbb{P}\), но выполняется
\(|M_r (P ̃ )|\lt m\), то точка \(\tilde{P}\) будет граничной точкой кластера.
Если \(P\) является внутренней точкой, то она образует кластер вместе со всеми точками, которые от нее достижимы по плотности.
Достижимость по плотности – это транзитивное замыкание непосредственно достижимой по плотности точки. Если точка \(\tilde{P}\)
достижима по плотности из точки \(P_i\), то это не говорит о том, что точка \(P_i\) достижима по плотности из точки \(\tilde{P}\).
Иллюстрация достижимости по плотности с m=3. Точка p достижима от о, но не наоборот.
Заметим, что для нашей задачи внутренней точкой кластера можно взять точку с максимальным рейтингом, а число \(m\) выбрать равным количеству вершин
симплекса, то есть, равным 4. Выбор радиуса \(r\) обусловлен размером используемого корпуса ключевых слов, то есть, выберем значение радиуса таким,
чтобы полученный кластер включил в себя все ключевые слова, для которых есть соответствие степени релевантности, и для прогноза потенциального
ключевого слова будем использовать только слова полученного кластера.
Триангуляция Делоне по очищенному (кластеризированному) множеству ключевых слов.
Следующим этапом работы над потенциальными ключевыми словами является определение степени соответствия релевантности этого слова.
Релевантность ключевого слова– это содержательное соответствие поисковому запросу и ссылке, которая на нее ведет.
Релевантность является важным критерием как в поисковой оптимизации, так и при размещении контекстной рекламы.
Поисковым машинам важно, чтобы на продвигаемом ресурсе действительно присутствовал ключевой запрос, который пользователь ввел в строке поиска.
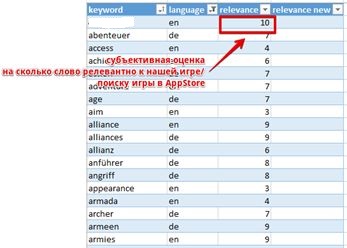
Значение релевантности можно записать в виде соотношения \(r=P_r*(T+L)\), где \(T\) – уровень соответствия внутренних критериев ресурса заданным
требованиям поисковиков (релевантность текста), \(L\) – степень ссылочной ранжировки, т.е. степень совпадения текстов ссылок «на вход» поисковому
запросу (ссылочная релевантность) и \(P_r\) – показатель внешнего мерила документа, который не зависит от запроса (авторитет ресурса).
Так как используемые переменные достаточно субъективны, то будем считать, что релевантность определена по 10-бальной шкале,
где 10 соответствует наивысшему уровню соответствия используемого ключевого слова нашему ресурсу.
Значения релевантности используемых ключевых слов.
Опишем используемый критерий выбора ключевого слова с учетом его релевантности.
Традиционно используемый критерий качества ключевого слова \(k\) c рейтингом \(R\) и релевантностью \(r\) вычисляется следующим образом
\[
\varepsilon(k)=\sqrt{(10-r)^2+(1-R)^2},
\]
то есть, \(\varepsilon(k)\) равна расстоянию от точки с координатами \((R,r)\) до идеальной точки \((1,10)\)- с наивысшим рейтингом и наилучшей
релевантностью. Чем меньше значение \(\varepsilon(k)\), тем лучше ключевое слово.
Заметим, что к достоинствам этой конструкции можно отнести только ее лаконичность.
Рассмотрим данную задачу подробнее. Так как, в данной постановке, между рейтингом и релевантностью существует обратная корреляционная зависимость, то критерием отбора ключевого слова должно служить увеличение по модулю коэффициента корреляции, то есть увеличение зависимости этих двух характеристик. То есть, если добавление конкретного ключевого слова увеличило зависимость, то есть коэффициент корреляции стал ближе к минус единице, то это слово хорошо описывает наш продукт, если коэффициент корреляции стал ближе к нулю, то это слово только ухудшает общую ситуацию, и его удаление только улучшит зависимость между рейтингом и релевантностью.
С другой стороны, если рейтинг слова низкий и релевантность близка к нулю, даже при высокой корреляционной зависимости такое слово никакой пользы не принесет, например, при существующем множестве ключевых слов коэффициент корреляции равен -0.12230467, а при удалении слова с рейтингом 216, получаем -0.12122318, то есть корреляционная зависимость ухудшилась, но это говорит лишь о том, что низкая релевантность правильно соотносится с низким уровнем рейтинга и не более того.
Следовательно, выбор ключевого слова обусловлен выполнением, по крайней мере, двух условий, с одной стороны, повышением корреляционной связи между
рейтингом и релевантностью, с другой, повышением среднего рейтинга набора ключевых слов. Таким образом, использование предложенного критерия качества не позволяет решить ни одной из этих проблем.
Для решения поставленной задачи предложен следующий алгоритм.
Пусть каждому ключевому слову \(k_i\in K\) соответствует пара \((R_i,\delta_i)\), где \(R_i\) – рейтинг этого слова и \(\delta_i\)
значение изменения коэффициента корреляции, равное \(\delta_i=corr(K)-corr(K\setminus k_i)\), где
\[
corr(K)=\frac{cov(R,r)}{\sigma_R\sigma_r}=\frac{\sum_{i=1}^n(R_i-\bar{R})(r_i-\bar{r})}{\sqrt{\sum_{i=1}^n(R_i-\bar{R})^2\sum_{i=1}^n(r_i-\bar{r})^2}}
\]
и
\[
\bar{R}=\frac{1}{n}\sum_{i=1}^nR_i,\bar{r}=\frac{1}{n}\sum_{i=1}^nr_i.
\]
И пусть есть слово \(\tilde{k}\) со значениями \((\tilde{R},\tilde{\delta})\), претендующее стать ключевым словом.
Пусть, вначале, \(p(\Delta^+ (\tilde{\delta})│R)\) – вероятность того, что при данном значении рейтинга \(R\), встретится слово такое,
что его значение изменения коэффициента корреляции будет больше \(\tilde{\delta}\) и, соответственно, \(p(\Delta^- (\tilde{\delta})│R)\) –
вероятность того, что при данном значении рейтинга \(R\), значение изменения коэффициента корреляции будет меньше \(\tilde{\delta}\).
Тогда задача определения рейтинга, при котором значение изменения коэффициента корреляции будет больше \(\tilde{\delta}\), имеет вид
\begin{equation}\label{2}
p(\Delta^+ (\tilde{\delta})│R)\gt p(\Delta^- (\tilde{\delta})│R)
\end{equation}
В соответствии с теоремой Байеса,
\[
p(\Delta^+ (\tilde{\delta})│R)=\frac{p(R|\Delta^+ (\tilde{\delta}))p(\Delta^+ (\tilde{\delta}))}{p(R)}
\]
где \(p(R|\Delta^+ (\tilde{\delta}))\)- вероятность встречи слова с рейтингом \(R\) при выполнении условия, что значение изменения
коэффициента корреляции будет больше \(\tilde{\delta}\), \(p(\Delta^+ (\tilde{\delta}))\)- вероятность встречи ключевого слова,
соответствующего условию \(\Delta^+ (\tilde{\delta})\) и \(p(R)\)- вероятность встречи слова с рейтингом \(R\).
Тогда условие (\ref{2}) примет вид
\[
\frac{p(R|\Delta^+ (\tilde{\delta}))p(\Delta^+ (\tilde{\delta}))}{p(R)}\gt
\frac{p(R|\Delta^- (\tilde{\delta}))p(\Delta^- (\tilde{\delta}))}{p(R)}
\]
или, что то же самое,
\[
p(R|\Delta^+ (\tilde{\delta}))p(\Delta^+ (\tilde{\delta}))\gt
p(R|\Delta^- (\tilde{\delta}))p(\Delta^- (\tilde{\delta})).
\]
В предположении, что слова по рейтингу распределены по нормальному закону,
\[
p(R|\Delta^+ (\tilde{\delta}))=\frac{1}{\sigma(R|\Delta^+ (\tilde{\delta}))\sqrt{2\pi}}
\exp\left(-\frac{\left(R-\bar{R}^+(\tilde{\delta})\right)^2}{2\sigma^2(R|\Delta^+ (\tilde{\delta}))}\right)
\]
где
\[
\sigma(R|\Delta^+ (\tilde{\delta}))=\left(\sum\left\{1|i:\delta_i\gt \tilde{\delta}\right\}\right)^{-1}
\sqrt{\sum\left\{\left(R_i-\bar{R}^+(\tilde{\delta})\right)^2|i:\delta_i\gt \tilde{\delta}\right\}}
\]
и
\[
\bar{R}^+(\tilde{\delta})=\left(\sum\left\{1|i:\delta_i\gt \tilde{\delta}\right\}\right)^{-1}
\sum\left\{R_i|i:\delta_i\gt \tilde{\delta}\right\}.
\]
Аналогично,
\[
p(R|\Delta^- (\tilde{\delta}))=\frac{1}{\sigma(R|\Delta^- (\tilde{\delta}))\sqrt{2\pi}}
\exp\left(-\frac{\left(R-\bar{R}^-(\tilde{\delta})\right)^2}{2\sigma^2(R|\Delta^- (\tilde{\delta}))}\right)
\]
где
\[
\sigma(R|\Delta^- (\tilde{\delta}))=\left(\sum\left\{1|i:\delta_i\lt \tilde{\delta}\right\}\right)^{-1}
\sqrt{\sum\left\{\left(R_i-\bar{R}^-(\tilde{\delta})\right)^2|i:\delta_i\lt \tilde{\delta}\right\}}
\]
и
\[
\bar{R}^-(\tilde{\delta})=\left(\sum\left\{1|i:\delta_i\lt \tilde{\delta}\right\}\right)^{-1}
\sum\left\{R_i|i:\delta_i\lt \tilde{\delta}\right\}.
\]
Соответственно,
\[
p(\Delta^+ (\tilde{\delta}))=\frac{1}{mes(K)}\sum\left\{1|i:\delta_i\gt \tilde{\delta}\right\},
p(\Delta^- (\tilde{\delta}))=\frac{1}{mes(K)}\sum\left\{1|i:\delta_i\lt \tilde{\delta}\right\},
\]
где \(mes(K)\)- общее количество используемых ключевых слов множества \(K\).
Используя полученные соотношения в (\ref{2}), получаем неравенство
\[
\frac{1}{\sigma(R|\Delta^+ (\tilde{\delta}))\sqrt{2\pi}}
\exp\left(-\frac{\left(R-\bar{R}^+(\tilde{\delta})\right)^2}{2\sigma^2(R|\Delta^+ (\tilde{\delta}))}\right)
\frac{1}{mes(K)}\sum\left\{1|i:\delta_i\gt \tilde{\delta}\right\}\gt
\frac{1}{\sigma(R|\Delta^- (\tilde{\delta}))\sqrt{2\pi}}
\exp\left(-\frac{\left(R-\bar{R}^-(\tilde{\delta})\right)^2}{2\sigma^2(R|\Delta^- (\tilde{\delta}))}\right)
\frac{1}{mes(K)}\sum\left\{1|i:\delta_i\lt \tilde{\delta}\right\}
\]
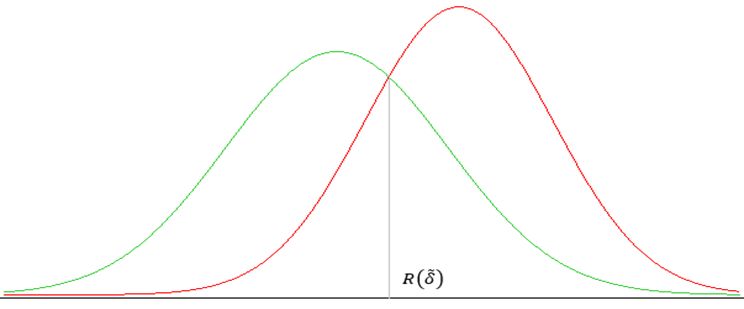
решая его, получаем значение \(R(\tilde{\delta})\), такое, что при \(R\gt R(\tilde{\delta})\) принимаем решение,
что корреляционная зависимость между рейтингом и релевантностью будет лучше, в противном случае, хуже.
Обозначим через \(\mathfrak{K}(\tilde{\delta})\) множество ключевых слов \(k_i\), таких, что \(R_i\lt R(\tilde{\delta})\).
Пусть теперь \(p(\Delta^+ (\tilde{R})|\delta)\) – вероятность того, что при данном значении изменения коэффициента корреляции \(\delta\),
встретится слово такое, что его рейтинг будет больше \(\tilde{R}\) и, соответственно введем \(p(\Delta^- (\tilde{R})|\delta)\).
Иллюстрация нахождения точки \(R(\tilde{\delta})\).
Сделав аналогичные построения, получаем значение \(\delta(\tilde{R})\), такое, что при \(\delta\gt\delta(\tilde{R})\) принимаем решение,
что рейтинг будет выше, а в противном случае, ниже. Через \(\mathfrak{K}(\tilde{R})\) обозначим множество ключевых слов \(k_i\),
таких, что \(\delta\lt\delta(\tilde{R})\).
Результатом полученных построений является множество ключевых слов
\[
\mathfrak{K}(\tilde{R},\tilde{\delta})=\mathfrak{K}(\tilde{R})\cap \mathfrak{K}(\tilde{\delta})
\]
таких, что замена любого ключевого слова \(k\in \mathfrak{K}(\tilde{R},\tilde{\delta})\) ключевым словом \(\tilde{k}\) только улучшит качество используемого корпуса ключевых слов. Выбор слова, удаляемого из используемого корпуса ключевых слов определяется необходимостью или увеличить средний рейтинг (попадание в верхнюю часть списка поиска по ключевым словам) или усилить корреляционную связь между релевантностью и рейтингом (соответствия ключевым словам содержанию ресурса).
Мультимедийный поиск по картинке.
Рассмотрим задачу ранжирования изображений. Пусть дано множество изображений \(\mathfrak{I}=\{\mathcal{I}_i\}_{i=1}^n\), среди которых нужно выбрать
изображения, "похожие" на данное \(\mathcal{I}^0\). Чтобы найти степень похожести нужно использовать какие-то характеристики, простейший случай -
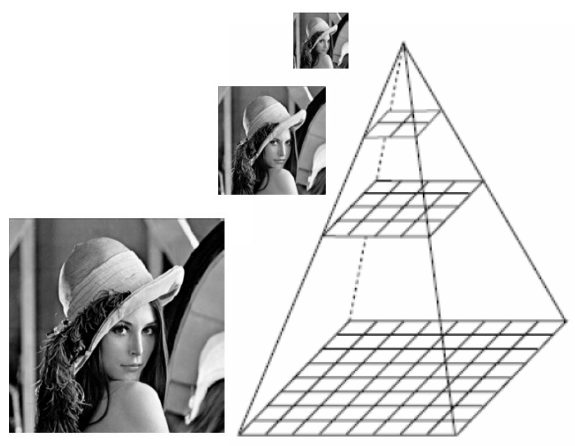
использование пространственных или же частотных характеристик. С этого и начнем. В качестве тестового изображения будем использовать изображение Lena.
Для того, чтобы изображения "уравнять в правах", всю коллекцию преобразуем в картинки одного и того же размера, например, 8×8 px.
Чтобы не зависеть от цветовых характеристик, имеет смысл рассматривать только освещенность, грубо говоря - изображение в градациях серого.
В простейшем случае это
\[
Gray=\frac{1}{3}(Red+Blue+Green),
\]
хотя лучше сделать так
\[
Gray=\frac{1}{256}(77\times Red+150\times Green + 29\times Blue+128).
\]
Теперь можно найти среднее значение и преобразовать полученное изображение и битовое, то есть, если цвет больше среднего значения, это единица,
меньше - ноль.
По сути, мы имеем код в 64 бита, которые характеризуют изображение, если у двух изображений эти коды совпадают, то можно считать, что и
соответствующие изображения совпадают, чем больше отличаются изображения друг от друга, тем больше отличие этих кодов. Тем самым получаем
достаточно простой алгоритм ранжирования изображений. Для более точного вычисления "похожести" изображений можно брать в качестве кода
значения цвета каждого пикселя изображения 8×8 px в градациях серого.
У данного метода есть много недостатков, среди которых, первый состоит в том, что метод очень чувствителен к освещенности, поэтому, если, например,
провести гамма-коррекцию, то получим другой код. Второй недостаток состоит в том, что если будем сравнивать с фрагментом изображения, а не изображения в целом,
то ничего хорошего не получим.
Для того, чтобы обойти первый недостаток, можно использовать для построения кода какие-нибудь частотные характеристики.
Для этой цели можно взять какое-нибудь ортогональное преобразование.
Традиционно для этой цели используется преобразование Фурье, более того, дискретное косинус-преобразование. По большому счету, выбор преобразования
не имеет большого значения, можно взять преобразование Хаара, Уолша, использовать ортогональные вейвлеты Добеши или биортогональные, вместо
косинус-преобразования использовать полное преобразование Фурье или же преобразование Хартли. Все это не по сути. Выбор дискретного преобразования
объясняется только лишь тем, что его использует JPEG. Ну что же, будем и мы его использовать, почему нет.
Прямое преобразование
\[
h(x,y)=C(x)C(y)\sum_{i=0}^{N-1}\sum_{j=0}^{N-1}Gray(i,j)\cos\frac{(2i+1)x\pi}{2N}\cos\frac{(2j+1)y\pi}{2N},
C(i)=\sqrt{\frac{2}{N}},i=0,C(i)=\sqrt{\frac{1}{N}},i=1,...,N-1.
\]
Обратное преобразование
\[
Gray(x,y)=\sum_{i=0}^{N-1}\sum_{j=0}^{N-1}c(i)c(j)h(i,j)\cos\frac{(2x+1)i\pi}{2N}\cos\frac{(2y+1)j\pi}{2N}.
c(i)=\sqrt{\frac{1}{N}},i=0,c(i)=\sqrt{\frac{2}{N}},i=1,...,N-1.
\]
Для использования в качестве кода значений частотных характеристик имеет смысл выбирать те, которые соответствуют низким частотам, как наиболее
информативным с точки зрения описания изображения в целом. Построим, как и в предыдущем случае, код из 64 чисел. Лучше всего для этой цели
найти коэффициенты Фурье от всего изображения в целом и выбрать \(h(i,j),i,j=0,...,7\), которые и использовать в качестве кода. К сожалению,
вычисление коэффициентов Фурье является достатосно затратной процедурой, поэтому нужно либо использовать быстрое преобразование Фурье, либо применять его к уменьшенной картинке.
Заметим, что чем меньше картинка, к которой применим этот алгоритм, тем хуже код. Таким образом, нужен компромис.
Для изображения 128×128 px
код будет иметь вид
Понятно, что из него несложно получить бинарный код.
Масштабонезависимое преобразование признаков (SIFT),
предложенное Дэвидом Лоу, является описанием дескрипторов изображения для согласования изображений.
Данное описание дескрипторов достаточно быстро пробило себе дорогу и сейчас используется в широком спектре задач компьютерного зрения, прежде всего
связанных с сопоставлением между различными проекциями трехмерной сцены и распознаванием объектов на основе визуальных представлений.
Дескрипторы SIFT инвариантны к поворотам, вращениям и масштабирующим преобразованиям, а также устойчивы к умеренным преобразованиям перспективы и
освещения.
Важной особенностью дескрипторов SIFT оказалось их эффективность для сопоставления изображений и распознавания объектов.
Далее рассмотрим краткое описание дескрипторов SIFT.
В своей первоначальной формулировке дескриптор SIFT состоял из метода определения точек интереса для изображения в градациях серого с целью
сопоставления соответствующих точек интереса между разными изображениями.
Далее метод был расширен с серого на цветные изображения и с двухмерных изображений на пространственно-временное видео.
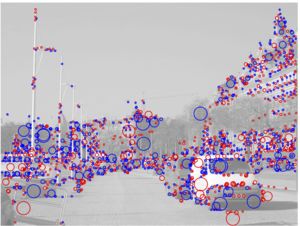
Масштабно-инвариантные точки интереса. Радиусы окружностей иллюстрируют выбранные шкалы обнаружения точек интереса.
Красные круги показывают экстремумы ярких мест изображения \(\nabla^2L\lt 0\), тогда как синие круги - темных, то есть, где
\(\nabla^2L\gt 0\).
Идея, лежащая в основе построения дескрипторов, достаточно очевидна - особые точки изображения, на то они и особые, видны при разных масштабах.
Ясно, что при приближении объекта мы видим больше деталей, а при его отдалении, детали скрадываются и пока объект можно распознать, видно лишь то,
что характеризует его в целом. Для выделения точек интереса (характеризующих изображение), используется пирамида гауссианов и разностей гауссианов.
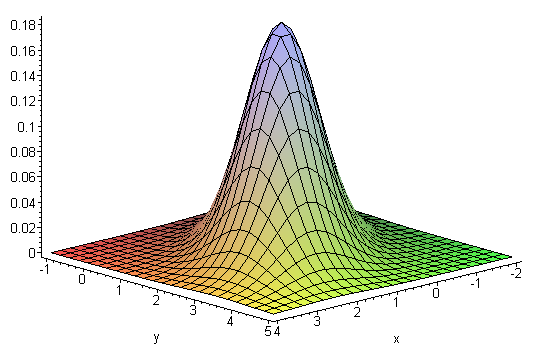
Гауссиан – это изображение, которое было размыто с помощью фильтра Гаусса.
Введем некоторые необходимые обозначение. Пространственным фильтром \(A\) назовем матрицу (для простоты будем считать ее квадратной
\((2N+1)\times (2N+1)\))
\(A=(a_{i,j})_{i,j=-N}^N\), такую, что \(\sum_{i,j=-N}^Na_{i,j}=1.\) Сверткой матрицы \(B={b_{i,j}}\) с фильтром \(A\) назовем матрицу \(H=A*B\),
определяемую следующим образом
\[
h_{\nu,\mu}=\sum_{i=-N}^N\sum_{j=-N}^Na_{i,j}b_{\nu+i,\mu+j}.
\]
Построение дескрипторов SIFT использует фильтры, значения которых снимаются с функции Гаусса
\[
G(x,y,\sigma)=\frac{1}{2\pi\sigma^2}\exp\left(-\frac{x^2+y^2}{2\sigma^2}\right),
\]
то есть \(a_{i,j}=g_{i,j}(\sigma)/|g|\), где
\[
g_{i,j}(\sigma)=\frac{1}{2\pi\sigma^2}\exp\left(-\frac{i^2+j^2}{2\sigma^2}\right),
|g|=\sum_{i,j=-N}^Ng_{i,j}(\sigma).
\]
Первый этап обнаружения ключевых точек (точек интереса) состоит в определении мест на изображении, которые повторяются при разных представлениях одного и того
же объекта. Обнаружение местоположений точек, инвариантных к изменению масштаба изображения может быть выполнено путем поиска стабильных
признаков во всех возможных масштабах. Для этой цели используется свертка изображения \(I(x,y)\) с Гауссовским фильтром
\[
L(x,y,\sigma)=G(x,y,\sigma)*I(x,y).
\]
Результат применения фильтров Гаусса с разным радиусом.
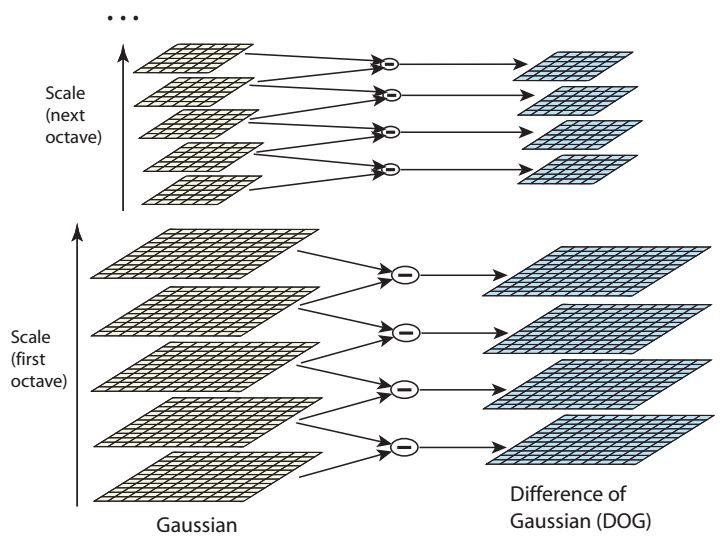
Для нахождения устойчивых местоположений ключевых точек используется разность между гауссианами (difference of-Gaussian -DoG)
\[
D(x,y,\sigma)=(G(x,y,k\sigma)-G(x,y,\sigma))*I(x,y)=L(x,y,k\sigma)-G(x,y,\sigma).
\]
Использование шкалы значений \(k\) и \(\sigma\), позволяет получить набор изображений с разной степенью сглаживания и масштабирования. Данная процедура
называется SIFT Octaves. Один масштаб - одна октава.
Как правило используют четыре октавы.
После построения октав находятся особые точки. Точка считается особой, если она является локальным экстремумом разности гауссианов.
Прежде всего выпишем нормализованный лапласиан
\[\nabla^2_{norm} L(x, y; s) = s \, (L_{xx} + L_{yy}) = s \, \left( \frac{\partial^2 L}{\partial x^2} + \frac{\partial^2 L}{\partial y^2} \right) =
s \, \nabla^2 (G(x, y; s) * I(x, y))\]
от разности \(L(x, y; s)\) входного изображения \(I(x, y)\) и свертки с гауссовыми ядрами разной ширины \(s = \sigma^2\) (\(\sigma\) дисперсия гауссова ядра).
Тогда
\[D(x, y; s) = L(x, y; s + \Delta s) - L(x, y; s) \approx \frac{\Delta s}{2} \nabla^2 L(x, y; s).\]
Оператор Лапласа является вращательно-инвариантным, поэтому точки интереса также будут вращательно-инвариантными.
Проблема состоит в том, что на местах, где присутствуют углообразные структуры изображений, оператор Лапласа может приводить к сильным
возмущениям. Чтобы подавить такого рода помехи, Дэвид Лоу сформулировал критерий соотношения между собственными значениями матрицы Гессе
\[{\cal H} L =
\begin{bmatrix}
L_{xx} & L_{xy} \\
L_{xy} & L_{yy}
\end{bmatrix}
\]
Это связано с тем, что если предполагаемая точка интереса лежит на контуре объекта, или же эта точка плохо освещена, то ее следует исключить,
что может быть переформулировано в терминах следа и определителя матрицы Гессе
\[\frac{\mbox{det}{\cal H} L}{\mbox{trace}^2{\cal H} L} = \frac{L_{xx} L_{yy} - L_{xy}^2}{(L_{xx} + L_{yy})^2} \geq \frac{r}{(r+1)^2},\]
где \(r \geq 1\) обозначает верхний предел допустимого отношения между большим и меньшим собственными значениями.
После того, провели очистку точек интереса, нужно найти ориентацию каждой оставшейся точки, то есть найти направление градиентов ее соседних точек.
Для этой цели используем пирамиду гауссианов. Найдем величину градиента и направление градиента в точке с координатами \((x,y)\)
\[
|\nabla L|=\sqrt{L^2_x+L^2_y},\arg\nabla L=arctg\frac{L_y}{L_x},L_x=L(x+1,y)-L(x-1,y),L_y=L(x,y+1)-L(x,y-1).
\]
Далее определяется окрестность особой точки, в которой будут рассмотрены градиенты. Как правило, это круг или квадрат (все равно это
круг в манхеттеновской метрике).
В каждой точке интереса, вычисляется дескриптор изображения.
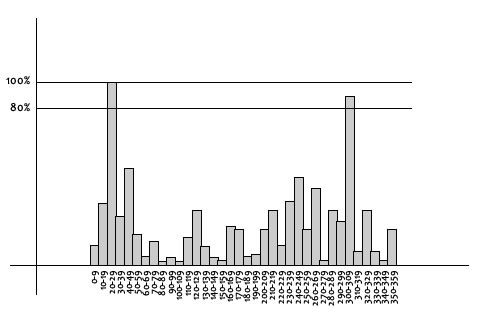
Дескриптор SIFT можно рассматривать как зависящую от позиции гистограмму локальных градиентных направлений вокруг точки интереса.
Величина и ориентация вычисляются для всех пикселей вокруг ключевой точки. По полученным значениям создается гистограмма
На этой гистограмме 360 градусов ориентации разбиты на 36 ячеек (каждые 10 градусов).
Любые пики выше 80% самого высокого пика преобразуются в новую ключевую точку.
Эта новая ключевая точка имеет то же местоположение и масштаб, что и оригинал, но ориентация равна значению другого пика.
Таким образом, ориентация может разделить одну ключевую точку на несколько ключевых точек.
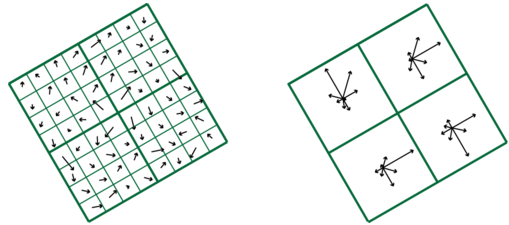
Стрелки на левом рисунке указывают векторы градиента, вычисленные из данных изображения, тогда как стрелки на правой фигуре
представляют результирующие записи в гистограммах ориентации, как квантованные в восемь разных направлений градиента.
Приведем иллюстрацию этапов получения дескрипторов SIFT:
Получить код изображения Lena на основе преобразования Хаара.
Задача 2.
Применить метод ранжирования документов TF-IDF к примеру из раздела "Использование информационного вклада для ранжирования документов по запросу."
Задача 3.
Применить метод вероятностного ранжирования документов к примеру из раздела "Использование информационного вклада для ранжирования документов по запросу."
Задача 4.
Используя векторную модель документов, применить ранжирование к примеру из раздела "Использование информационного вклада для ранжирования документов по запросу."