Метод главных компонент (Principal Component Analysis - PCA) находит самое точное отображение данных в пространстве меньшей размерности,
линейный дискриминантный анализ Фишера (Fisher Linear Discriminat Analysis- LDA) в своей идее имеет иной характер.
Различные инструменты для классификации данных можно найти на веб-сайте Science Hunter.
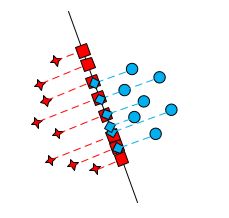
Главная идея состоит в нахождении гиперплоскости, проекция на которую позволяет наиболее точно разделить классы данных.
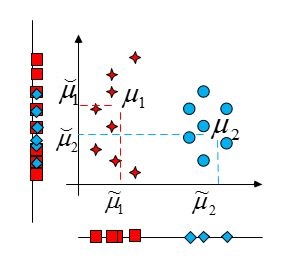
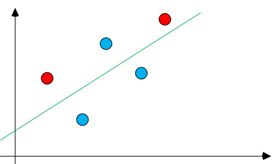
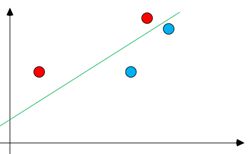
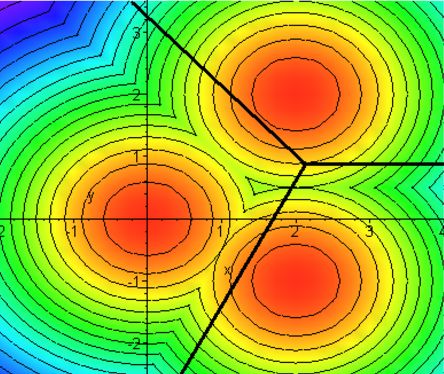
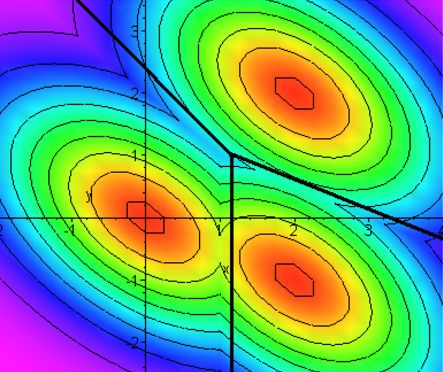
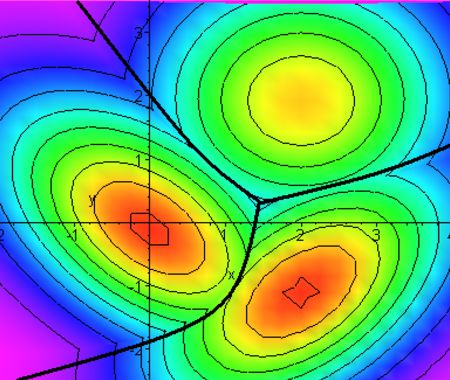
Плохое разделение классов точек.
Хорошее разделение классов точек.
Пусть имеем точки \(x_1,x_2,...,x_n\) из двух классов в пространстве \(d\)- измерений, из которых \(n_1\) точек принадлежит одному классу и \(n_2\)- второму.
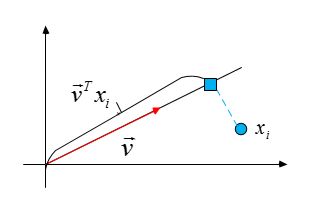
Для единичного вектора \(\vec{\nu}\) построим проекции этих точек на направление данного вектора.
Тогда скалярное произведение \(\vec{\nu}^Tx_i\) совпадает с расстоянием от начала координат до проекции точки \(x_i\) на направление вектора \(\vec{\nu}\),
другими словами, \(\vec{\nu}^Tx_i\) есть проекция \(x_i\) на пространство меньшей размерности.
Оценим степень разделения проекций различных классов. Пусть \(\mu_1\) и \(\mu_2\) средние значения первого и второго классов, а \(\tilde{\mu}_1\)
и \(\tilde{\mu}_2\) средние значения проекций первого и второго классов, тогда
\[
\tilde{\mu}_1=\frac{1}{n_1}\sum\left\{\left.\vec{\nu}^Tx_i\right|x_i\in c_1\right\}=
\vec{\nu}^T\left(\frac{1}{n_1}\sum\left\{\left.x_i\right|x_i\in c_1\right\}\right)=\vec{\nu}^T\mu_1.
\]
и, соответственно, \(\tilde{\mu}_2=\vec{\nu}^T\mu_2\).
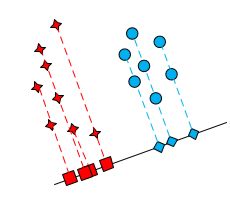
Величина \(|\tilde{\mu}_1-\tilde{\mu}_2|\) может быть хорошей мерой для разделения классов.
Для данного изображения горизонтальная ось лучше разделяет классы и, соответственно,
\[ |\tilde{\mu}_1-\tilde{\mu}_2|>|\breve{\mu}_1-\breve{\mu}_2|.\]
С другой стороны, эта характеристика разделяет только центры классов, что не всегда соответствует хорошему разделению самих классов.
Нам необходимо нормализовать \(|\tilde{\mu}_1-\tilde{\mu}_2|\) на коэффициент, который пропорционален разбросу данных класса (дисперсии).
Итак, пусть имеются данные \(z_1,z_2,...,z_n\). Их среднее значение \(\mu_z=\frac{1}{n}\sum_{i=1}^nz_i\) и дисперсия \(s=\sum_{i=1}^n(z_i-\mu_z)^2\).
Таким образом, разброс просто равен произведению дисперсии на \(n\), то есть, разброс от дисперсии отличается только масштабом.
Фишер предложил следующее решение – нормализация \(|\tilde{\mu}_1-\tilde{\mu}_2|\) по разбросу данных.
Пусть \(y_i=\vec{\nu}^Tx_i\) - проекция точки \(x_i\) на направление вектора \(\vec{\nu}\).
Тогда разброс проекций первого класса равен \(\tilde{s}^2_1=\sum\left\{\left. (y_i-\tilde{\mu}_1)^2\right|x_i\in c_1\right\}\) и второго
\(\tilde{s}^2_2=\sum\left\{\left. (y_i-\tilde{\mu}_2)^2\right|x_i\in c_2\right\}\).
Проведем совместную нормализацию для обоих классов. Тогда линейным дискриминантом Фишера будет гиперплоскость, направление которой \(\vec{\nu}\)
максимизирует величину
\[J(\nu)=\frac{|\tilde{\mu}_1-\tilde{\mu}_2|}{\tilde{s}^2_1+\tilde{s}^2_2}.\]
Все, что нам нужно сделать сейчас, чтобы выразить \(J\) явным образом как функцию \(\vec{\nu}\) и максимизировать его величину.
Определим матрицы оценивания разброса исходных данных (до проекции)
\[
S_1=\sum\left\{\left. (x_i-\mu_1)(x_i-\mu_1)^T\right|x_i\in c_1\right\},
S_2=\sum\left\{\left. (x_i-\mu_2)(x_i-\mu_2)^T\right|x_i\in c_2\right\}.
\]
Теперь определим матрицу разброса между классами \(S_W=S_1+S_2.\)
Замечая, что \(\tilde{s}^2_1=\sum\left\{\left. (y_i-\tilde{\mu_1})^2\right|x_i\in c_1\right\}\) и учитывая, что \(y_i=\vec{\nu}^Tx_i\) и
\(\tilde{\mu}_1=\vec{\nu}^T\mu_1\)
\[
\tilde{s}^2_1=\sum\left\{\left. (y_i-\tilde{\mu_1})^2\right|x_i\in c_1\right\}=
\sum\left\{\left. (\vec{\nu}^Tx_i-\vec{\nu}^T\mu_1)^2\right|x_i\in c_1\right\}=
\sum\left\{\left. \left(\vec{\nu}^T(x_i-\mu_1)\right)^T\left(\vec{\nu}^T(x_i-\mu_1)\right)\right|x_i\in c_1\right\}=\]
\[
\sum\left\{\left. \left((x_i-\mu_1)^T\vec{\nu}\right)^T\left((x_i-\mu_1)^T\vec{\nu}\right)\right|x_i\in c_1\right\}=
\sum\left\{\left. \vec{\nu}^T\left((x_i-\mu_1)(x_i-\mu_1)^T\right)\vec{\nu}\right|x_i\in c_1\right\}=\vec{\nu}^TS_1\vec{\nu}.
\]
Аналогично, \(\tilde{s}^2_2=\vec{\nu}^TS_2\vec{\nu}\) и, соответственно,
\[\tilde{s}^2_1+\tilde{s}^2_2=\vec{\nu}^TS_1\vec{\nu}+\vec{\nu}^TS_2\vec{\nu}=\vec{\nu}^TS_W\vec{\nu}.
\]
Определим матрицу разброса между классами
\[S_B=(\mu_1-\mu_2)(\mu_1-\mu_2)^T.\]
Кроме того,
\[
|\tilde{\mu}_1-\tilde{\mu}_2|^2=\left(\vec{\nu}^T\mu_1-\vec{\nu}^T\mu_2\right)^2=
\vec{\nu}^T(\mu_1-\mu_2)(\mu_1-\mu_2)^T\vec{\nu}=\vec{\nu}^TS_B\vec{\nu}.
\]
С учетом этих построений, функцию цели можно записать в виде
\[J(\nu)=\frac{|\tilde{\mu}_1-\tilde{\mu}_2|}{\tilde{s}^2_1+\tilde{s}^2_2}=
\frac{\vec{\nu}^TS_B\vec{\nu}}{\vec{\nu}^TS_W\vec{\nu}}.
\]
Далее просто найдем экстремум этой функции
\[\frac{d}{d\nu}J(\nu)=\frac{\left(\frac{d}{d\nu}\vec{\nu}^TS_B\vec{\nu}\right)\vec{\nu}^TS_W\vec{\nu}-
\left(\frac{d}{d\nu}\vec{\nu}^TS_W\vec{\nu}\right)\vec{\nu}^TS_B\vec{\nu}
}{\left(\vec{\nu}^TS_W\vec{\nu}\right)^2}=
\frac{\left(2S_B\vec{\nu}\right)\vec{\nu}^TS_W\vec{\nu}-
\left(2S_W\vec{\nu}\right)\vec{\nu}^TS_B\vec{\nu}
}{\left(\vec{\nu}^TS_W\vec{\nu}\right)^2}=0.
\]
То есть
\[
\left(S_B\vec{\nu}\right)\vec{\nu}^TS_W\vec{\nu}-
\left(S_W\vec{\nu}\right)\vec{\nu}^TS_B\vec{\nu}=0
\]
или, что то же
\[
\frac{\left(S_B\vec{\nu}\right)\vec{\nu}^TS_W\vec{\nu}- \left(S_W\vec{\nu}\right)\vec{\nu}^TS_B\vec{\nu}
}{\vec{\nu}^TS_W\vec{\nu}}=
\frac{\left(S_B\vec{\nu}\right)\vec{\nu}^TS_W\vec{\nu}}{\vec{\nu}^TS_W\vec{\nu}}-
\frac{\left(S_W\vec{\nu}\right)\vec{\nu}^TS_B\vec{\nu}}{\vec{\nu}^TS_W\vec{\nu}}=
S_B\vec{\nu}-\lambda S_W\vec{\nu}=0,
\hbox{ где } \lambda=\frac{\vec{\nu}^TS_B\vec{\nu}}{\vec{\nu}^TS_W\vec{\nu}}.
\]
Таким образом задача поиска дискриминанта свелась к задаче поиска собственных векторов и собственных чисел, если \(S_W\) имеет полный ранг,
то есть существует обратная матрица, то
\[
S_B\vec{\nu}-\lambda S_W\vec{\nu}=0 \Leftrightarrow S_W^{-1}S_B\vec{\nu}=\lambda \vec{\nu}.
\]
Для любого вектора \(x\) рассмотрим \(S_Bx\)
\[
S_Bx=(\mu_1-\mu_2)\left((\mu_1-\mu_2)^Tx\right)=\alpha(\mu_1-\mu_2), \hbox{ где } \alpha=(\mu_1-\mu_2)^Tx.
\]
Получим решение задачи на собственные числа и собственные значения
\[
S_W^{-1}S_B\underbrace{\left(S_W^{-1}(\mu_1-\mu_2)\right)}_{\vec{\nu}}=S^{-1}_W\left(\alpha(\mu_1-\mu_2)\right)=
\alpha\underbrace{\left(S_W^{-1}(\mu_1-\mu_2)\right)}_{\vec{\nu}}, \hbox{ где } \vec{\nu}=S^{-1}_W(\mu_1-\mu_2).
\]
Рассмотрим пример.
Пусть есть классы \(c_1=\)[(1,2),(2,3),(3,3),(4,5),(5,5)] и \(c_2=\)[(1,0),(2,1),(3,1),(5,3),(6,5)]
PCA позволяет получить направление с наибольшим разбросом данных, что не позволяет разделить классы.
Вначале найдем средние значения \(\mu_1=\)[3, 3.6] и \(\mu_2=\)[3, 3.2]. Найдем матрицы разброса
S1=
10
8.0
8.0
7.2
S2=
17.7
16.0
16.0
16.0
И для обоих классов
SW=S1+S2=
27.3
14.0
24.0
23.2
Матрица обратима и
\(S^{-1}_W=\)
0.39
-0.41
-0.41
0.47
и вектор, определяющий оптимальное направление \(\vec{\nu}\)
\(\vec{\nu}=S^{-1}_W(\mu_1-\mu_2)=\)
-0.79
0.89
Последним шагом будет вычисление вектора \(y\), и, соответственно, разделение классов
Можно обобщить ЛДА для случая нескольких классов. В этом случае для \(с\) классов, можно уменьшить размерность до \(1,2,3,…,с-1\).
Рассмотрим проекцию \(x_i\) на линейное подпространство \(y_i=V^Tx_i\), \(V\) называют проекционной матрицей.
Пусть \(n_i\) число элементов \(i\)-го класса, \(\mu_i\) -среднее значение этого класса и \(\mu\)-среднее значение всех элементов
\[
\mu_i=\frac{1}{n_i}\sum\{x|x\in c_i\}, \mu=\frac{1}{n}\sum_{i=1}^nx_i.
\]
Выпишем функцию цели
\[
J(\nu)=\frac{det(V^TS_BV)}{det(V^TS_WV)}.
\]
Матрица разброса будет
\[
S_W=\sum_{i=1}^cS_i=\sum_{i=1}^c\sum{\left\{\left.(x_k-\mu_i)(x_k-\mu_i)^T\right|x_k\in c_i\right\}}.
\]
Матрица рассеивания между классами будет
\[
S_B=\sum_{i=1}^cn_i(\mu_i-\mu)(\mu_i-\mu)^T.
\]
Пусть матрица имеет максимальный \(rank=c-1\), тогда решение сводится к решению задачи на собственные числа
\[
S_BV=\lambda S_WV.
\]
Тогда оптимальная проекция будет на вектор, который соответствует максимальному собственному числу.
Параметрические методы и дискриминантные функции
Использование параметрических методов предполагает наличие информации о плотности распределения классов по известным
\(p_1(x|\theta_1),p_2(x|\theta_2),\ldots \) с оцениванием параметров \(\theta_1,\theta_2,\ldots\) и последующим применением байесовского
классификатора.
Использование линейных дискриминантных функций \(\ell(\theta_1),\ell(\theta_2),\ldots\) с параметрами \(\theta_1,\theta_2,\ldots\) также
позволяет разделить классы.
Чисто теоретически, классификатор Байеса минимизирует риски, но на практике у нас нет информации о функции плотности и, по-большому счету,
это для разделения классов не так уже и важно. Да и точное определение параметров функций плотности намного сложнее, чем оценка
дискриминантных функций.
Поэтому достаточно часто возникает такая ситуация, что оценку плотностей нужно пропустить.
Естественно, что дискриминантные функции совсем не обязательно могут быть линейными, но линейные методы достаточно популярны и их следует
рассмотреть, хотя бы по той причине, что линейные дискриминантные функции оптимальны для Гауссовских распределений с равной ковариацией.
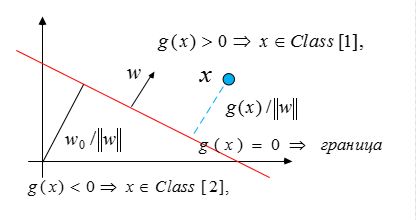
Дискриминантная функция \(g(x)\) называется линейной, если \(g(x)=w^Tx+w_0\), где \(w\) весовой вектор и \(w_0\) смещение или сдвиг.
При этом
Здесь \(w\) определяет ориентацию разделяющей гиперплоскости, а \(w_0\) –место расположения поверхности решения.
Для случая нескольких классов ситуация аналогичная. Определим \(m\) линейных дискриминантных функций
\(g_i(x)=w^T_ix+w_{i,0}, i=1,2,\ldots,m\). Элемент \(x\) принадлежит классу \(c_i\), если \(g_i(x)\ge g_j(x),\forall j\ne i.\)
Такой классификатор называется линейной машиной. Линейная машина разбивает пространство на \(k\)-классов, причем для элементов \(i\)-го
класса наибольшее значение среди всех дискриминантных функций будет у \(g_i(x)\).
Для двух классов \(c_i,c_j\) граница, разделяющая эти множество будет гиперплоскостью \(h_{i,j}\), определяемой соотношением
\[
g_i(x)=g_j(x)\Leftrightarrow w_i^Tx+w_{i,0}=w_j^Tx+w_{j,0}\Leftrightarrow (w_i-w_j)^Tx+(w_{i,0}-w_{j,0})=0.
\]
Таким образом, \(w_i-w_j\) будет нормалью \(h_{i,j}\) и расстояние от \(x\) до \(h_{i,j}\) будет равно
\[
d(x,h_{i,j})=\frac{g_i(x)-g_j(x)}{\|w_i-w_j\|}.
\]
Кроме того, линейная машина дает разбиение на выпуклые множества
\[
x,y\in c_i\Rightarrow \alpha x+(1-\alpha)y\in c_i
\]
Так как
\[
\forall j\ne i\hbox{ } g_i(x)\ge g_j(x), g_i(y)\ge g_j(y) \Rightarrow \forall j\ne i\hbox{ } g_i(\alpha x+(1-\alpha)y)\ge g_j(\alpha x+(1-\alpha)y),
\]
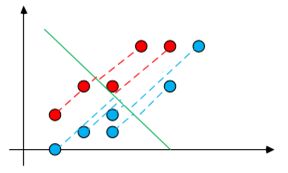
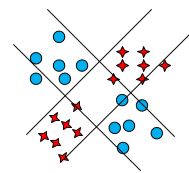
то результатом работы линейной машины будут односвязные области, поэтому применимость линейной машины по большей части ограничено унимодальностью
условной плотности \(p(x|\theta)\). Для множеств приведенных на иллюстрации
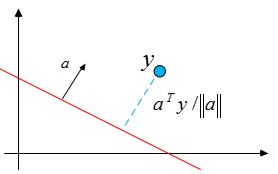
линейная машина заведомо не может отработать хорошо. Для решения этой проблемы перепишем линейную дискриминантную функцию \(g(x)=w^T+w_0\) в виде
\[
g(x)=\left[w_0,w^T\right]\left[\begin{array}{c}1\\x\end{array}\right]=a^Ty=g(y), \hbox{ где }
a=[w_0,w^T] \hbox{ и } y=[1, x]^T.
\]
Тогда если \(g(x)=w^T+w_0\), то для вектора \([x_1,...,x_d]^T\) эквивалентная задача будет иметь вид \(g(y)=a^Ty\), для вектора \([1,x_1,...,x_d]^T\)
и условие разделения классов будет иметь вид
\[
\left\{
\begin{array}{ll}
a^Ty_i\gt 0, & \forall y_i\in c_1 \\
a^Ty_i\lt 0, & \forall y_i\in c_2
\end{array}
\right.
\hbox{ или, что то же }
\left\{
\begin{array}{ll}
a^Ty_i\gt 0, & \forall y_i\in c_1 \\
a^T(-y_i)\gt 0, & \forall y_i\in c_2
\end{array}
\right.
\]
Таким образом нужно найти такой вектор \(a\), чтобы для всех элементов \(y_i(i=1,2,...,n)\) одного класса выполнялось неравенство
\[
a^Ty_i=\sum_{k=0}^da_ky_i^{(k)}>0.
\]
Таких решений может быть достаточно много, поэтому нужен критерий наилучшего отбора.
Так или иначе каким бы не был критерий отбора нужно искать его экстремум, скажем – минимум. Приведем один достаточно общий алгоритм поиска
экстремума – метод градиентного спуска.
Пусть нужно найти минимум функции нескольких переменных \(J(X)=J(x_1,x_2,...,x_d)\). Как известно, для поиска экстремума нужно найти производную
и приравнять ее нулю, в данном случае найти градиент и приравнять нулю
\[
\left[\frac{\partial}{\partial x_1}J(X),\ldots,\frac{\partial}{\partial x_d}J(X)\right]^T=\nabla J(X)=0.
\]
Как известно, градиент это вектор, идущий в направлении наибольшего изменения функции, соответственно, \(-\nabla J(X)\)- в направлении наибольшего
убывания.
Таким образом, для того, чтобы из точки \(x^{(k)}\) перейти в точку, где значение функции цели меньше, нужно сдвинуться на вектор градиента,
пока выполняется условие \(\eta^{(k)}\left|\nabla J\left(x^{(k)}\right)\right|\gt \varepsilon\), где \(\eta^{(k)}\) некоторый шаг, регулирующий скорость и
точность работы алгоритма, то есть
\[
x^{(k+1)}=x^{(k)}-\eta^{(k)}\nabla J_p(a).
\]
К сожалению, градиентный спуск может найти локальный экстремум и не найти глобальный.
Принцип персептрона.
Пусть \(Y_M(a)=\{y_i:a^Ty_i\lt 0\}\) - множество неправильно классифицированных элементов для классификатора с вектором \(a\).
Тогда минимизация этой величины может быть критерием качества классификатора.
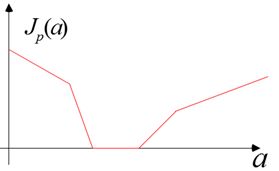
Возьмем функцию цели \(J_p(a)=\sum\left\{\left.\left(-a^Ty\right)\right|y\in Y_M\right\}\), тогда при неправильной классификации будет выполняться
условие \(a^Ty\lt 0\), то есть \(J_p(a)\ge 0\) и \(J_p(a)\) есть \(\|a\|\) раз взятая сумма расстояний неправильно классифицированных элементов до границы
\(J_p(a)\) является кусочно-линейной функцией, к которой применим метод градиентного спуска, тогда
\[
\nabla J_p(a)=\sum\left\{(-y)|y\in Y_M\right\}.
\]
Сделаем шаг в направлении градиента
\[
x^{(k+1)}=x^{(k)}-\eta^{(k)}\nabla J_p(a).
\]
И вычислим новое значение вектора в этой точке
\[
a^{(k+1)}=a^{(k)}+\eta^{(k)}\sum\left\{y|y\in Y_M\right\}.
\]
А для каждого конкретного неправильно классифицированного элемента получаем
\[
a^{(k+1)}=a^{(k)}+\eta^{(k)}y_M.
\]
Геометрическая интерпретация состоит в следующем: \(\left(a^{(k)}\right)^Ty_M\le 0\) говорит о том, что элемент \(y_M\) лежит не с той стороны
разделяющей гиперплоскости, а прибавление \(\eta^{(k)}y_M\) к \(a\) двигает разделяющую гиперплоскость в нужном направлении относительно
элемента \(y_M\).
Рассмотрим пример.
Имя
Посещение
Активность
На занятиях спит
На занятиях жует жвачку
Класс
Петя
1 (true)
1(true)
-1(false)
-1(false)
A
Вова
1
1
1
1
F
Ваня
-1
-1
-1
1
F
Дина
1
-1
-1
1
A
Построим линейную дискриминантную функцию, разделяющую эти классы.
Вначале конвертируем \(x_1,\ldots,x_n\) в \(y_1,\ldots,y_n\), \(y_i\to -y_i\) \(\forall y_i\in c_2\) расширив пространство на одно измерение
Имя
Доп.
Посещение
Активность
На занятиях спит
На занятиях жует жвачку
Класс
Петя
1
1 (true)
1(true)
-1(false)
-1(false)
A
Вова
-1
-1
-1
-1
-1
F
Ваня
-1
1
1
1
-1
F
Дина
1
1
-1
-1
1
A
Полагая \(\eta^{(k)}=1\), получим \(a^{(k+1)}=a^{(k)}+y_M.\)
Выберем в качестве стартового вектора \(a^{(1)}=\left[0.25,0.25,0.25,0.25\right]\) и проверим полученный классификатор
Следуя алгоритму персептрона, выберем инициализующий вектор a(1)=[1,1,1], и, соответственно, разделяющую гиперплоскость \(x^{(1)}+x^{(2)}+1=0\).
Зафиксируем шаг \(\eta=1\) и получим итерационное решение \(a^{(k+1)}=a^{(k)}+y_M\). Проверим условие выполнения разделимости классов
\[
y^T_1a^{(1)}=[1,1,1]\times [1,2,1]^T>0-true,
\]
\[
y^T_2a^{(1)}=[1,1,1]\times [1,4,3]^T>0-true,
\]
\[
y^T_3a^{(1)}=[1,1,1]\times [1,3,5]^T>0-true,
\]
\[
y^T_4a^{(1)}=[1,1,1]\times [-1,-2,-3]^T=-5 \lt 0-false.
\]
Пересчитаем нормаль разделяющей гиперплоскости
\[
a^{(2)}=a^{(1)}+y_M=[1,1,1]+[-1,-1,-3]=[0,0,-2].
\]
Тогда
\[
y^T_5a^{(2)}=[0,0,-2]\times [-1,-5,-5]^T=12 \gt 0-true.
\]
Теперь все с начала
\[
y^T_1a^{(2)}=[0,0,-2]\times [1,2,1]^T \lt 0-false.
\]
Пересчитаем вектор
\[
a^{(3)}=a^{(2)}+y_M=[0,0,-2]+[1,2,1]=[1,2,-1].
\]
И так далее по кругу. Ясно, что алгоритм не сойдется.
Можно изменять шаг обучения персептрона \(\eta^{(k)}=\eta^{(1)}/k\), что позволит найти решение более точно (если оно существует). Но оно может и не существовать.
Использование метода наименьших квадратов
Один из подходов состоит в использовании метода наименьших квадратов, основная идея которого состоит в заменен системы неравенств на систему уравнений.
Если \(\|a\|=1\), то \(a^Ty_i=b_i\) есть расстояние от точки \(y_i\) до гиперплоскости с нормалью \(a\), тогда для всех точек наших классов имеем систему
\[
\left\{
\begin{array}{l}
a^Ty_1=b_1 \\
\vdots \\
a^Ty_n=b_n
\end{array}
\right.
\Rightarrow
\left[
\begin{array}{cccc}
y_1^{(0)} & y_1^{(1)}&\cdots & y_1^{(d)} \\
y_2^{(0)} & y_2^{(1)}&\cdots & y_2^{(d)} \\
\vdots & \vdots & \ddots & \vdots \\
y_n^{(0)} & y_n^{(1)}&\cdots & y_n^{(d)}
\end{array}
\right]
\left[
\begin{array}{c}
a_0 \\
a_1 \\
\vdots \\
a_d
\end{array}
\right]=
\left[
\begin{array}{c}
b_0 \\
b_1 \\
\vdots \\
b_d
\end{array}
\right] \Leftrightarrow Ya=b.
\]
Если \(Y\) невырождена, то \(a=Y^{-1}b\), а если нет, что тогда? Ну хотя бы найти какое-то приближение.
Пусть \(\varepsilon=Ya-b\), выпишем функцию цели
\[
J(a)=\|Ya-b\|^2=\sum_{i=1}^n\left(a^Ty_i-b_i\right)^2,
\]
тогда
\[
\nabla J(a)=\left[\frac{\partial}{\partial a_1}J(a),\ldots,\frac{\partial}{\partial a_d}J(a)\right]^T=\frac{d J(a)}{d a}=
\sum_{i=1}^n\frac{d}{d a}\left(a^Ty_i-b_i\right)^2=
\sum_{i=1}^n2\left(a^Ty_i-b_i\right)\frac{d}{d a}\left(a^Ty_i-b_i\right)=
\sum_{i=1}^n2\left(a^Ty_i-b_i\right)y_i=2Y^T(Ya-b)=0\Rightarrow Y^TYa=Y^Tb.
\]
Матрица \(Y^TY\) невырожденная, и, тогда, \(a=(Y^TY)^{-1}Y^Tb\).
Процедура МНК эквивалента нахождению гиперплоскости, наилучшим образом соответствующей имеющейся выборке (как правило, называемую обучающей
выборкой). Но при этом можно гарантировать нахождение решения только в том случае, если \(Ya>0\), то есть, все координаты вектора
\(Ya=\left[a^Ty_1,\ldots,a^Ty_n\right]^T\) положительны, но реально \(Ya\approx b\) и \(Ya=\left[b_1+\varepsilon_1,\ldots,b_n+\varepsilon_n\right]^T\),
где не обязательно, что все значения \(\varepsilon_i\) положительны, причем, если \(b_i+\varepsilon_i\gt 0\), то получим разделение множеств,
а если – нет (что возможно для элементов , лежащим близко к разделяющей гиперплоскости), то ответ будет неверен.
Таким образом, для случая линейно неразделимых классов МНК не даст разделяющую гиперплоскость.
Может появиться искушение так провести гиперплоскость, чтобы расстояние от элемента до разделяющей гиперплоскости удовлетворяло условию
\(Ya\approx b>0\),
но это все равно не приведет к желаемому результату, так, если мы вместо \(b\) используем \(\beta b\), то если \(a^*\) решение МНК \(Ya=b\),
то для \(Ya=\beta b\) метод наименьших квадратов даст
\[
\arg\min_a\|Ya-\beta b\|^2=\arg\min_a\beta^2\left\|Y\left(\frac{a}{\beta}\right)- b\right\|^2=
\arg\min_a\left\|Y\left(\frac{a}{\beta}\right)- b\right\|^2=\beta a^*.
\]
Так для любого элемента \(Ya\), который меньше нуля \(y_i^Ta\lt 0\), получаем \(y_i^T(\beta a)\lt 0\).
Если положить \(b_1=b_2=\ldots =b_n=1\), то МНК приведет к линейному дискриминанту Фишера, при выборке, стремящейся к бесконечности, получим метод Байеса
\[
g_B(x)=P(c_1|x)-P(c_2|x).
\]
Чтобы оценить плюсы и минусы МНК, рассмотрим несколько примеров.
Проведем «нормализацию», добавив одно измерение
\[
y_1=[1,6,9]^T, y_2=[1,5,7]^T, y_3=[-1,-5,-9]^T, y_4=[-1,0,-10]^T,
\]
и, соответственно, получаем матрицу
\[
\left[
\begin{array}{rrr}
1 & 6 & 9 \\
1 & 5 & 7 \\
-1 & -5 & -9 \\
-1 & 0 & -10
\end{array}
\right]
\hbox{ выберем }
b=\left[
\begin{array}{r}
1 \\
1 \\
1 \\
1
\end{array}
\right]
\hbox{ и, применяя МНК, получим }
a=[3.2,0.2,-0.4]^T.
\]
Отсюда получаем \(Ya=[0.2,0.9,-0.04,1.16]^T\ne [1,1,1,1]^T\) и \(Ya\lt 0\), что НЕ дает разделяющую гиперплоскость
За счет чего получается такой парадоксальный ответ? МНК тянет ко всем значениям выборки, минимизируем общее расстояние, что делает его
чувствительным к «выбросам» и «шуму». Но, используя весовые коэффициенты, то есть, придавая разным элементам разную «важность» для их классификации, можно подправить результат, получив приемлемое решение, так придав элементам, далеко лежащим от разделяющей гиперплоскости больший вес, получим следующее:
Выберем \(b=[1,1,1,10]^T\) и, применяя МНК, получим \(a=[-1.1,1.7,-0.9]^T\) отсюда получаем \(Ya=[0.9,1.0,0.8,10.0]^T\ne [1,1,1,10]^T\) но \(Ya\gt 0\),
Заметим что для большой размерности найти решение системы уравнений может быть затруднительно, особенно в условиях, когда значение дискриминанта
матрицы близко к нулю. В этом случае достаточно использовать поиск приближенного решения, применяя, тот же метод градиентного спуска.
Итак, есть функция цели \(J(a)=\|Ya-b\|^2=\sum_{i=1}^n\left(a^Ty_i-b_i\right)^2\), ее градиент равен \(\nabla J(a)=2Y^T(Ya-b)\)
и, следуя спуску по градиенту, получаем каждый последующий шаг определения весового вектора \(a^{(k+1)}=a^{(k)}-\eta^{(k)}\nabla J(a)=a^{(k)}-\eta^{(k)}Y^T(Ya-b)\).
Если \(\eta^{(k)}=\eta^{(1)}/k\), то для получения точного решения метода наименьших квадратов нужно добиться выполнения условия \(Y^T(Ya-b)=0\). Алгоритм спуска всегда дает решение, не зависимо от того, вырождена матрица или нет.
Процедура Widrow-Hoff.
Процедура Уидроу-Хоффа разработана применительно к «чёрному ящику», в котором между входами и выходами существуют только линейные связи. Процедура обучения основывается на минимизации ошибки обучения в процессе подачи на вход сети входных образов, путем использования градиентного спуска по настраиваемым параметрам нейронной сети.
В нашем случае \(a^{(k+1)}=a^{(k)}-\eta^{(k)}y_i(y_i^Ta^{(k)}-b_i)\), то есть, правило Видроу-Хоффа обеспечивает коррекцию вектора \(a\)
в том случае, когда \(y_i^Ta^{(k)}\) не равно \(b_i\).
Процедура Ho-Kashyap.
Рассмотренные методы позволяют найти весовой вектор для линейно разделимых классов, и если вектор допуска \(b\) выбран произвольно, то
результатом метода наименьших квадратов будет минимизация выражения \(\|Ya-b\|^2\), при этом если классы разделимы, то существуют такие \(a\) и \(b\),
что \(Ya=b\gt 0\). Проблема в том, что \(b\) заранее не известно. Процедура Хо-Кашьпа предполагает одновременное нахождение как разделяющего
вектора \(a\), так и вектора допуска \(b\). Идея состоит в том, что если выборки (классы) разделимы, то минимальное значение \(J(a)=\|Ya-b\|^2\)
равно нулю, а вектор \(a\), при котором это значение достигается, будет разделяющим вектором.
Из необходимого условия экстремума функции двух переменных получаем
\[
\left\{
\begin{array}{l}
\nabla_a J(a,b)=2Y^T(Ya-b)=0, \\
\nabla_b J(a,b)=-2(Ya-b)=0.
\end{array}
\right.
\]
Процедура Хо-Кашьпа предлагает для решения этой задачи использовать двушаговый алгоритм.
Для любого фиксированного \(b\) из первого уравнения находим \(a\).
После этого фиксируем \(a\) и из второго уравнения находим \(b\).
Первый шаг предполагает использование псевдо-обратной матрицы, то есть из условия \(2Y^T(Ya-b)=0\)
получаем \(a=(Y^TY)^{-1}Y^Tb\).
Второй шаг предполагает для фиксированного \(a\), получить решение \(b\), которое вроде бы как равно \(b=Ya\), но \(b\) должны быть
положительными, в чем мы не можем быть уверены, поэтому для поиска \(b\) используем метод градиентного спуска
\[
b^{(k+1)}=b^{(k)}-\eta^{(k)}\nabla_bJ(a^{(k)},b^{(k)}).
\]
Но при малых значениях \(b\) и большом значении градиента можем опять таки получить отрицательные значения \(b\). Для того, чтобы решить эту проблему, можно в случае положительного значения градиента взять ноль.
\[
b^{(k+1)}=b^{(k)}-\eta \frac{1}{2}\left(\nabla_bJ(a^{(k)},b^{(k)})-\left|\nabla_bJ(a^{(k)},b^{(k)})\right|\right).
\]
Пусть \(\varepsilon^{(k)}=Ya^{(k)}-b^{(k)}=-\frac{1}{2}\nabla_bJ(a^{(k)},b^{(k)})\) значение ошибки, тогда
\[
b^{(k+1)}=b^{(k)}-\eta \frac{1}{2}\left(-2\varepsilon^{(k)}-\left|2\varepsilon^{(k)}\right|\right)=
b^{(k)}+\eta \left(\varepsilon^{(k)}+\left|\varepsilon^{(k)}\right|\right).
\]
Формализуем процедуру Хо-Кашьпа.
Пусть, вначале, \(k=1\) для любых стартовых значений \(a^{(k)},b^{(k)}\) выполним следующие шаги
\(k=k+1\) пока не выполнится условие останова, которым может быть, например, ограничение числа шагов \(k\), стабилизация вектора \(b\) или
значения ошибки \(\varepsilon\).
Квадратичный дискриминантный анализ
Пусть даны классы \(c_i (i = 1,2,...,k)\), функция \(g_i (x)\), такая, что если
\[
g_i (x) > g_j (x)
\quad
\forall i \ne j,\mbox{ то }
\quad
x \in c_i ,
\]
то такая функция называется дискриминантной или разделяющей классы.
В качестве дискриминантной функции совершенно естественно использовать
априорную вероятность попадания в класс \(c_{i}\) при выпадении события \(x\)
\[
g_i \left( x \right) = P\left( {c_i \vert x} \right).
\]
Тогда в соответствии с теоремой Байеса
\[
g_i \left( x \right) = \frac{P\left( {x\vert c_i } \right)P\left( {c_i }
\right)}{P\left( x \right)},
\]
так как \(P(x)\) не зависит от классов, то в качестве дискриминантной функции можно взять
\[
g_i \left( x \right) = P\left( {x\vert c_i } \right)P\left( {c_i } \right).
\]
В силу монотонности логарифмической функции, можно в качестве дискриминантной функции использовать эквивалентную
\[
g_i \left( x \right) = \ln P\left( {x\vert c_i } \right) + \ln P\left( {c_i} \right).
\]
Тогда, если данные класса \(c_{i }\) распределены по нормальному закону \(N\left({\mu _i ,\Sigma _i } \right)\)
\[
p\left( {x\vert c_i } \right) = \frac{1}{\left( {2\pi } \right)^{n /
2}\left| {\Sigma _i^{ - 1} } \right|^{1 / 2}}\exp \left( { -
\frac{1}{2}\left( {x - \mu _i } \right)^T\Sigma _i^{ - 1} \left( {x - \mu _i
} \right)} \right),
\]
то
\[
g_i \left( x \right) = - \frac{1}{2}\left( {x - \mu _i } \right)^T\Sigma
_i^{ - 1} \left( {x - \mu _i } \right) - \frac{n}{2}\ln \left( {2\pi }
\right) - \frac{1}{2}\ln \left| {\Sigma _i^{ - 1} } \right| + \ln P(c_i ).
\]
Так как \(\frac{n}{2}\ln \left( {2\pi } \right)\) постоянная, то дискриминантную функцию можно записать в эквивалентном виде
\begin{equation}
\label{eq5.7}
g_i \left( x \right) = - \frac{1}{2}\left( {x - \mu _i } \right)^T\Sigma
_i^{ - 1} \left( {x - \mu _i } \right) - \frac{1}{2}\ln \left| {\Sigma _i^{
- 1} } \right| + \ln P(c_i ).
\end{equation}
Отсюда, перемножая, получаем
\[
g_i \left( x \right) = - \frac{1}{2}\left( {x^T\Sigma _i^{ - 1} x - 2\mu
_i^T \Sigma _i^{ - 1} x + \mu _i^T \Sigma _i^{ - 1} \mu _i } \right) -
\frac{1}{2}\ln \left| {\Sigma _i^{ - 1} } \right| + \ln P(c_i ) =
\]
\begin{equation} \label{eq5.8}
= x^T\left( { - \frac{1}{2}\Sigma _i^{ - 1} } \right)x + \mu _i^T \Sigma
_i^{ - 1} x + \left( { - \frac{1}{2}\mu _i^T \Sigma _i^{ - 1} \mu _i -
\frac{1}{2}\ln \left| {\Sigma _i^{ - 1} } \right| + \ln P(c_i )} \right).
\end{equation}
Замечая, что
\[
x^TWx = \sum_{i = 1}^n {\sum_{j = 1}^n {w_{i,j} x_i x_j } } ,
\]
получаем квадратичную функцию
\[
g_i (x) = x^TA_i x + B_i x + D_i ,
\]
где
\[
A = - \frac{1}{2}\Sigma _i^{ - 1} ,B_i = \mu _i^T \Sigma _i^{ - 1} ,D_i = -
\frac{1}{2}\mu _i^T \Sigma _i^{ - 1} \mu _i - \frac{1}{2}\ln \left| {\Sigma
_i^{ - 1} } \right| + \ln P(c_i ).
\]
Таким образом, дискриминантная функция будет состоять из дуг кривых второго порядка (эллипсов, парабол и пр.).
Приведем важный частный случай построения дискриминантной функции.
Пусть
\[
\Sigma _i = \sigma ^2I = \left( {{\begin{array}{*{20}c}
{\sigma ^2} \hfill & 0 \hfill & \cdots \hfill & 0 \hfill \\
0 \hfill & {\sigma ^2} \hfill & \cdots \hfill & 0 \hfill \\
\vdots \hfill & \vdots \hfill & \ddots \hfill & \vdots \hfill \\
0 \hfill & 0 \hfill & \cdots \hfill & {\sigma ^2} \hfill \\
\end{array} }} \right)
\quad
(i = 1,...,k),
\]
то есть случайные величины \(\left( {X_1 ,X_2 ,...,X_n } \right)\) независимы с разным математическим ожиданием, но с одной и той же дисперсией. В этом случае
\[
\Sigma _i^{ - 1} = \frac{1}{\sigma ^2}I = \left( {{\begin{array}{*{20}c}
{\frac{1}{\sigma ^2}} \hfill & 0 \hfill & \cdots \hfill & 0 \hfill \\
0 \hfill & {\frac{1}{\sigma ^2}} \hfill & \cdots \hfill & 0 \hfill \\
\vdots \hfill & \vdots \hfill & \ddots \hfill & \vdots \hfill \\
0 \hfill & 0 \hfill & \cdots \hfill & {\frac{1}{\sigma ^2}} \hfill \\
\end{array} }} \right)\mbox{ и }
\quad
\left| {\Sigma _i } \right| = \sigma ^{2n}.
\]
Замечая, что при этом \(\frac{1}{2}\ln \left| {\Sigma _i^{ - 1} } \right|\) является постоянной, то из (\ref{eq5.7}) получаем следующую дискриминантную функцию
\[
g_i \left( x \right) = - \frac{1}{2\sigma ^2}\left( {x - \mu _i }
\right)^T\left( {x - \mu _i } \right) + \ln P(c_i ) =\]
\[= - \frac{1}{2\sigma
^2}\left( {x^Tx - \mu _i^T x - x^T\mu _i + \mu _i^T \mu _i } \right) + \ln
P(c_i ),
\]
а так как \(x^Tx\) не зависит от классов, то получаем
\begin{equation}
\label{eq5.9}
g_i \left( x \right) = - \frac{1}{2\sigma ^2}\left( { - 2\mu _i^T x + \mu
_i^T \mu _i } \right) + \ln P(c_i ) = a_i x + b_i ,
\end{equation}
где
\[
a_i = \frac{\mu _i^T }{\sigma ^2}\mbox{ и }
\quad
b_i = \ln P(c_i ) - \frac{\mu _i^T \mu _i }{2\sigma ^2}.
\]
Таким образом, в этом случае дискриминантная функция является линейной, то есть, для двух переменных это прямая, для трех - плоскость,
а в общем случае -гиперплоскость.
Заметим, что если при этом все \(P(c_i ) = \frac{1}{k},i = 1,2,...,k\), то линейные дискриминантные функции приводят к разбиению Вороного.
Рассмотрим метод классификации, основанный не на понятии расстояния между элементами, а на критерии близости, построенном на вычислении косинуса
угла между двумя векторами. Все построения приведем на примере классификации текстов.
Первый шаг состоит в первичной обработке данных - построение множеств статистики для имеющихся классов. Для построения множества статистики
последовательно обрабатываются все множества словоформ \(b^\nu ,\nu = 0,...,M- 1 \), принадлежащие одному классу
\(B = \left\{ {b^\nu } \right\}_{\nu =0}^{M - 1} \). По множеству словоформ каждого обрабатываемого текста \(b^\nu \) строится множество
уникальных (неповторяющихся) словоформ и их счетчики -
\(\left( {w_i^\nu ,n_i^\nu } \right)\left( {i = 0,...,N^\nu - 1} \right) \).
Здесь \(N^\nu \)- количество уникальных словоформ для текста \(b^\nu \). После этого данные для каждого множества отдельно нормируются
\[
\overline {n} _i^\nu = \frac{n_i^\nu }{\sqrt {\sum\limits_{j = 0}^{N^\nu - 1}
{\left( {n_j^\nu } \right)^2} } }\left( {i = 0,...,N^\nu - 1} \right).
\]
Затем, упорядочиваем все слова для каждого документа в одном и том же
порядке (сам порядок слов не существенен, главное, чтобы слова в каждой из структур
\(\left( {w_i^\nu ,n_i^\nu } \right)\left( {i = 0,...,N^\nu - 1} \right) \) шли в одном и том же порядке) и находим сумму всех векторов
\(n_i\left( B \right) = \sum\limits_{j = 0}^{M - 1} {\overline {n}_i^\nu } \left(i = 0,...,N\left( B \right) \right)\)
(где \(N(B)- \) количество уникальных словоформ для класса \(B \) в целом) и нормируем ее единицей
\[
\overline {n}_i\left( B \right) = \frac{n_i\left( B \right)}{\sqrt
{\sum\limits_{j = 0}^{N(B)} {\left(n_j\left( B \right) \right)^2} } }.
\]
Для полученной центральной точки класса формируем множество статистики, записывая в него значения
\(\left( {w_i\left( B \right),\overline {n} _i \left( B \right)} \right)\left( {i = 0,...,N\left( B \right)} \right) \).
Для построения центрального вектора классов \(\left\{ {B^\mu } \right\}_{\mu = 0}^{K - 1} \) , где каждый класс \(B^\mu \)
описывается своим центральным вектором \(\left( {w_i\left( {B^\mu } \right),\overline {n} _i\left( {B^\mu} \right)} \right) \)
\(\left( {i = 0,...,N\left( {B^\mu } \right)} \right) \), нужно найти их сумму,
просуммировав все координаты из всех суммируемых векторов для каждого значения словоформы, то есть для словоформы \(\omega \) получаем координату
\[
n\left( \omega \right) = \sum\limits_{\mu = 0}^{K - 1} {\left\{ {\left.
{\overline {n} _i\left( B^\mu \right)} \right|w_i\left( ^\mu
\right) = \omega ,i = 0,...N\left(B^\mu \right)} \right\}} ,
\]
следовательно, нужно составить список уникальных словоформ по всем
центральным векторам классов \(\left\{ {B^\mu } \right\}_{\mu = 0}^{K - 1} \) и просуммировать их координаты.
Результатом будет множество, состоящее их уникальных (неповторяющихся) словоформ и их координат
\[
\left( {w_i\left( {\left\{ {B^\mu } \right\}_{\mu = 0}^{K - 1} }
\right),n_i\left( {\left\{ {B^\mu } \right\}_{\mu = 0}^{K - 1} } \right)}
\right)\left( {i = 0,...,N\left( {\left\{ {B^\mu } \right\}_{\mu = 0}^{K -1} } \right)} \right),
\]
где \(N\left( {\left\{ {B^\mu } \right\}_{\mu = 0}^{K - 1} } \right) \) -
количество уникальных словоформ множества классов \(\left\{ {B^\mu }
\right\}_{\mu = 0}^{K - 1} \). Остается пронормировать полученные координаты
\[
\overline {n} _i\left( {\left\{ {B^\mu } \right\}_{\mu = 0}^{K - 1} }
\right) = \frac{n_i\left( {\left\{ {B^\mu } \right\}_{\mu = 0}^{K - 1} }
\right)}{\sqrt {\sum\limits_{j = 0}^{N\left( {\left\{ {B^\mu } \right\}_{\mu
= 0}^{K - 1} } \right)} {\left( {n_j\left( {\left\{ {B^\mu } \right\}_{\mu
= 0}^{K - 1} } \right)} \right)^2} } },
\]
и, полученный вектор \(\left( {w_i\left( {\left\{ {B^\mu } \right\}_{\mu =0}^{K - 1} } \right),\hat {n}_i\left( {\left\{ {B^\mu } \right\}_{\mu =0}^{K - 1} } \right)} \right)\left( {i = 0,...,N\left( {\left\{ {B^\mu }\right\}_{\mu = 0}^{K - 1} } \right)} \right)\)
будет центральным вектором множества \(\left\{ {B^\mu } \right\}_{\mu = 0}^{K - 1} \).
Идеально сформированной классификацией векторного метода является такой набор классов \(\left\{ {B^\mu } \right\}_{\mu = 0}^{K - 1} \), для которого выполняется следующее условие: \(\forall b \in B^\mu ,\mu = 0,...,K - 1 \) имеет место соотношение
\begin{equation}\label{eq5.11}
\left\langle {\overline {n} \left( b \right),\overline {n} \left( {B^\mu }
\right)} \right\rangle \lt \left\langle {\overline {n} \left( b
\right),\overline {n} \left( {B^\nu } \right)} \right\rangle ,\nu \ne \mu .
\end{equation}
Рассмотрим вектор \(\Lambda \) (управление) размерностью \(N\left( {B^\mu }\right) \),
координаты которого принимают только одно из двух допустимых значений
\[
\lambda _i = \left\{ {{\begin{array}{*{20}c}
{0,} \hfill \\
{1.} \hfill \\
\end{array} }} \right.
\]
Через \(\Lambda b \) обозначим прямое произведение векторов \(\Lambda \) и \(b \), то есть
\[
\Lambda b = \left( {\lambda _0 \overline {n} _0 \left( b \right),\lambda _1
\overline {n} _1 \left( b \right),...,\lambda _{N(B^\mu )} \overline n
_{N(B^\mu )} \left( b \right)} \right).
\]
Управление \(\Lambda \) будем называть допустимым на классе \(B^\mu = \left\{ {b^k} \right\}_{k = 0}^{M - 1} \), если выполняется условие
\begin{equation}
\label{eq5.12}
\left\langle {\overline {\Lambda \overline {n} } \left( {b^k}
\right),\overline {\Lambda \overline {n} } \left( {B^\mu } \right)}
\right\rangle \lt \left\langle {\overline {\Lambda \overline {n} } \left( {b^k}\right),\overline {n} \left( {B^\nu } \right)} \right\rangle ,\nu \ne \mu ,k =0,1,...,M - 1.
\end{equation}
Допустимое управление, для которого имеет место это соотношение и при этом
\(\sum\limits_{k = 0}^{M - 1} {\left( {\Lambda b^k} \right)^2 \to \max } \), называется оптимальным.
Если для \(\nu \ne \mu \) множество допустимых управлений вырождено, то класс \(B^\mu = \left\{ {b^k} \right\}_{k = 0}^{M - 1} \)
определен некорректно, то есть он неразделим с классом \(B^\nu \).
Задача нахождения оптимального управления классическими методами достаточно сложна, поэтому для ее решения мы применим генетические алгоритмы.
В нашем случае используется одноточечный кроссинговер (Single-point crossover), который моделируется следующим образом - пусть имеются две
родительские особи с хромосомами \(X = \left\{ {x_i ,i \in \left\{ {0,...,L} \right\}} \right\} \) и
\(Y = \left\{ {y_i ,i \in \left\{ {0,...,L} \right\}} \right\} \).
Случайным образом определяется точка внутри хромосомы (точка разрыва), в которой обе хромосомы делятся на две части и обмениваются ими.
После процесса воспроизводства происходят мутации (mutation). Это
достигается за счет того, что изменяется случайно выбранный ген в хромосоме.
Для создания новой популяции нами использован элитарный отбор (Elite selection). Создается промежуточная популяция,
которая включает в себя как родителей, так и их потомков. Члены этой популяции оцениваются, а за тем из них выбираются \(N\) самых лучших
(пригодных), которые и войдут в следующее поколение.
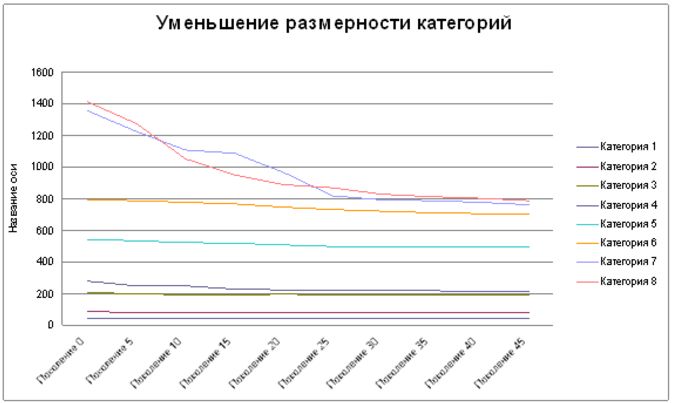
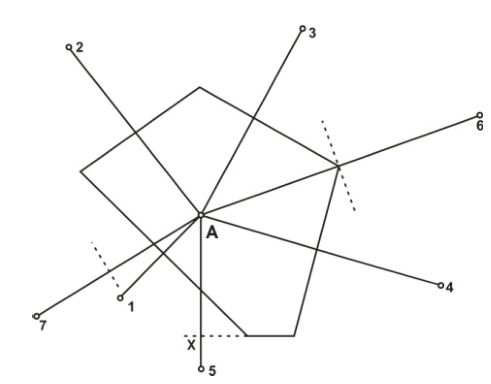
Результат применения генетического алгоритма к задаче сокращения размерности класса, приведен на рисунке
Диаграмма уменьшения размерности категорий при использовании генетических алгоритмов.
Заметим, что векторный метод в качестве критерия качества использует величину скалярного произведения ортов, таким образом, класс единичных
векторов (документов) ограничен на сфере окружностью с центром в конце центрального вектора класса.
Так как срезы сферы по окружности не могут плотно упаковать всю поверхность единичной сферы, то появляется множество точек (ортов),
которые принципиально не могут попасть ни в один класс. Таким образом, возникает необходимость разбить множество точек на единичной сфере,
так, чтобы элементы этого разбиения плотно упаковывали всю поверхность единичной сферы, то есть позволяли однозначно классифицировать любой
документ.
Использование диаграмм Вороного в задаче классификации текстов.
Для любого центра системы \(\{A\} \) можно указать область пространства, все точки которой ближе к данному центру, чем к любому другому центру
системы. Такая область называется многогранником Вороного или областью Вороного. К многограннику Вороного обычно относят и его поверхность.
В трехмерном пространстве область Вороного любого центра \(i \) системы \(\{A\} \) есть выпуклый многогранник, в двумерном - выпуклый многоугольник.
Другими словами, диаграммы Вороного представляют собой частный случай квадратичного дискриминантного анализа, при условиях, что случайные
величины с разным математическим ожиданием и с одной и той же дисперсией, а априорные вероятности выпадения классов равны между собой.
Формально многоугольники Вороного \(T_i \) определяются следующим образом:
\[
T_i = \left\{ {x \in R^2:d\left( {x,x_i } \right) \lt d\left( {x,x_j }
\right)\forall j \ne i} \right\}.
\]
Построение аппроксимации опирается на фундаментальное свойство для
произвольно заданных \(n \) точек множества \(S \) на плоскости. Для любого узла из \(n \) на плоскости существует множество натуральных соседей
\(N \). Понятие натуральных соседей тесно связано с разбиением области ячейками Вороного.
Для непустой ячейки Вороного \(V(R), R \subset S \) натуральные соседи для \(r\in R \) - вершины треугольников Делоне, инцидентных к \(V(R) \). Двумерный многогранник Вороного показан на следующем рисунке.
Многогранник Вороного для центра \(i \) двумерной системы.
Плоскости Вороного, которые породили грани у данного многогранника, называются образующими плоскостями Вороного, а соответствующие центры системы --- геометрическими соседями данного центра \(i \).
Среди геометрических соседей различают основные (естественные) и не
основные. Для первых - середина отрезка, соединяющая его с центральным
узлом, лежит на грани многогранника Вороного. Для вторых - вне грани и, следовательно, вне самого многогранника.
Многогранники Вороного, построенные для каждого центра системы \(\{A\}\)
дают мозаику многогранников - разбиение Вороного.
Диаграмма Вороного на плоскости.
Многогранники Вороного системы \(\{A\} \) не входят друг в друга и заполняют пространство, будучи смежными по целым
граням. Разбиение пространства на многогранники Вороного однозначно
определяется системой \(\{A\} \) и, наоборот, однозначно ее определяет.
Используя конструкцию диаграмм Вороного применительно к точкам на
многомерной единичной сфере, получаем разбиение всех ортов документов на естественные классы.
Границами классов будут являться гиперплоскости, разделяющие сферические многогранники Вороного.
При этом к одному классу будут относиться точки на единичной сфере (концы ортов документов), которые по отношению ко всем гиперплоскостям,
ограничивающим данный класс, лежат с одной ее стороны, что и центральный вектор этого класса.
Проверка классификации на корректность.
Пусть проверяются на корректность разбиения классы документов \(C_\nu \) и \(C_\mu \).
Для соответствующих орт (центральных векторов) \(\hat {C}_\nu \), \(\hat {C}_\mu \) строим вектор разности
\[
\vec {\Delta }_{\nu ,\mu } = \hat {C}_\nu - \hat {C}_\mu = \left\{ {\hat
{n}^\nu \left( {w_i } \right) - \hat {n}^\mu \left( {w_i } \right)}
\right\}
\]
и вектор суммы
\[
\vec {\Xi }_{\nu ,\mu } = \frac{1}{2}\left( {\hat {C}_\nu + \hat {C}_\mu }
\right) = \frac{1}{2}\left\{ {\hat {n}^\nu \left( {w_i } \right) + \hat
{n}^\mu \left( {w_i } \right)} \right\}.
\]
Конец вектора полусуммы численно совпадает с координатами этого вектора. Обозначим его через \(\Xi _{\nu ,\mu } \).
Проведем через точку \(\Sigma _{\nu ,\mu } \) плоскость с нормальным вектором \(\vec {\Delta }_{\nu ,\mu } \)
\begin{equation}
\label{eq5.13}
\Omega _{\nu ,\mu } = \left\langle {\vec {\Delta }_{\nu ,\mu } \cdot \left(
{{\rm P} - \Xi _{\nu ,\mu } } \right)} \right\rangle = 0.
\end{equation}
Эта плоскость разделяет классы. Для того, чтобы метод корректно разделял классы, нужно, чтобы все точки (документы) одного класса
находились с одной стороны плоскости, то есть, если \(b \in C_\nu \), то
\[
\left\langle {\vec {\Delta }_{\nu ,\mu } \cdot \left( {\hat {C}_\nu - \Xi
_{\nu ,\mu } } \right)} \right\rangle \left\langle {\vec {\Delta }_{\nu ,\mu
} \cdot \left( {\hat {b} - \Xi _{\nu ,\mu } } \right)} \right\rangle \ge 0.
\]
Точки, в которых это условие не выполняется нужно рассмотреть на вопрос принадлежности к категории \(C_\mu \).
Возможна ситуация, когда категории имеют непустое пересечение. Например, категория "АВТОР" содержит документы по математике (этого автора)
и категория "НАУКА" содержит документы по математике того же автора.
В этом случае нужно выделить непустое пересечение этих категорий и, в дальнейшем, либо эту категорию локализовать, либо проводить адресацию
в обе категории.
Для решения этой проблемы предлагается следующий метод. Рассмотрим категории \(C_\nu \) и \(C_\mu \).
Разделим их плоскостью (\ref{eq5.13}), и все точки, лежащие с одной стороны, соберем в новые две категории
\(C_\nu ^\ast \) и \(C_\mu ^\ast \).
Пусть
\[
d\left( {B,\Omega _{\nu ,\mu } } \right) = \frac{\left| {\left\langle {\vec
{\Delta }_{\nu ,\mu } \cdot \left( {B - \Xi _{\nu ,\mu } } \right)}
\right\rangle } \right|}{\left| {\vec {\Delta }_{\nu ,\mu } } \right|}
\]
расстояние от точки \(B = \left\{ {b_i } \right\} \) до плоскости \(\Omega _{\nu,\mu } \).
Если выполняется условие (то есть, после отсечения данных обе категории отодвигаются друг от друга)
\[
\left\{ {{\begin{array}{*{20}c}
{d\left( {C_\nu ^\ast ,\Omega _{\nu ,\mu } } \right) - d\left( {C_\nu
,\Omega _{\nu ,\mu } } \right) > 0,} \hfill \\
{d\left( {C_\mu ^\ast ,\Omega _{\nu ,\mu } } \right) - d\left( {C_\mu
,\Omega _{\nu ,\mu } } \right) > 0,} \hfill \\
\end{array} }} \right.
\]
то категории \(C_\nu \) и \(C_\mu \) имеют непустое пересечение \(\tilde {C} \), которое можно определить следующим образом,
\(b \in \tilde {C} \) если \(b \in C_\nu \) и при этом
\[
\left\langle {\vec {\Delta }_{\nu ,\mu } \cdot \left( {\hat {C}_\nu - \Xi
_{\nu ,\mu } } \right)} \right\rangle \left\langle {\vec {\Delta }_{\nu ,\mu
} \cdot \left( {\hat {b} - \Xi _{\nu ,\mu } } \right)} \right\rangle \lt 0,
\]
или, если \(b \in C_\mu \), то
\[
\left\langle {\vec {\Delta }_{\nu ,\mu } \cdot \left( {\hat {C}_\mu - \Xi
_{\nu ,\mu } } \right)} \right\rangle \left\langle {\vec {\Delta }_{\nu ,\mu
} \cdot \left( {\hat {b} - \Xi _{\nu ,\mu } } \right)} \right\rangle \lt 0.
\]
Естественно, что для метода, построенного на диаграммах Вороного также
актуальна задача сокращения размерности классов. Для этой цели, так же, как и в предыдущем случае, использовались генетические алгоритмы.
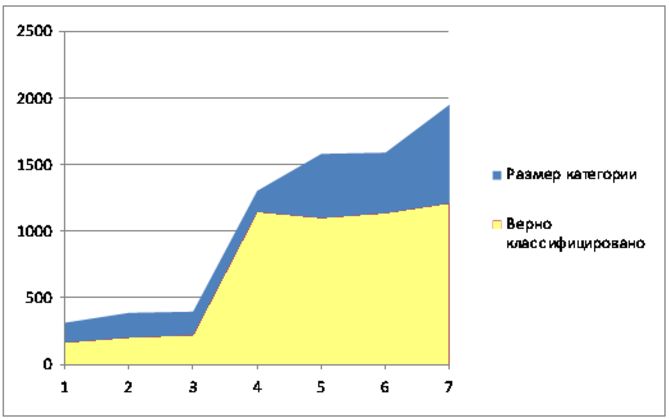
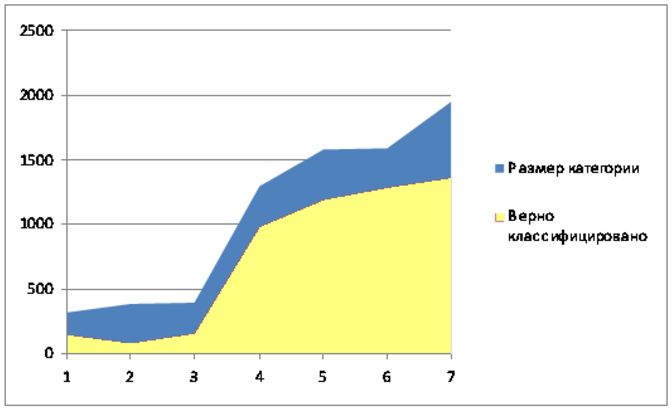
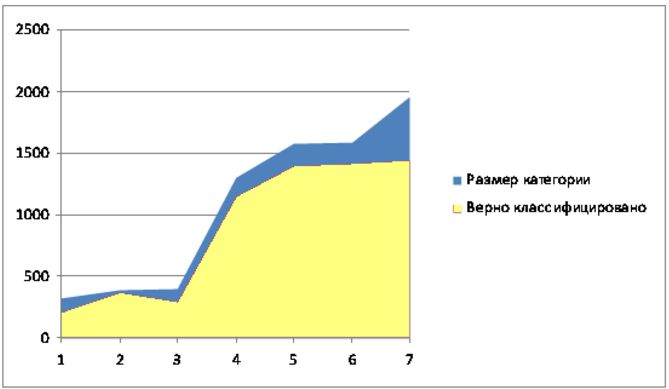
Сравнительный анализ применения различных методов классификации к тестовой базе документов Reuters (
Reuters-21578 text categorization test collection. ) приведен на следующих диаграммах.
Результат применения алгоритма Байеса.
Результат применения векторного алгоритма.
Результат применения алгоритма основанного на диаграммах Вороного.
Таким образом, для тестовой базы Reuters при условии попадания в класс не менее 90% документов, удалось сократить размерность классов
от 10% до 50%.
С чего выросла вся эта тематика -
ирисы Фишера.
Построить классификатор для трех видов ирисов - Iris setosa, Iris virginica и Iris versicolor.
Задача 2.
Даны антропометрические данные
Пол
Рост (см.)
Вес (кг.)
Длина ноги (см.)
Длина руки (см.)
Ширина плеч (см.)
Диаметр головы (см.)
Расстояние между коленом и лодыжкой (см.)
Построить дискриминантную функцию, разделяющую данные по полу и проверить корректность полученной классификации на своих личных значениях.
Задача 3.
По результатам голосования на первом туре президентских выборов 2019 года в Украине (по данным Центральной избирательной комиссии)
считая, что территориально сторонники каждой политической силы имеют нормальное распределение, построить дискриминантную функцию, показывающую
где проживают большая часть сторонников блока Петра Порошенко (15.95%), партии "Батьківщина" (13.40%), движения "Слуга народа" (30.24%) и
регионалов (Бойко Ю. (11.67%) и Вилкул А. (4.15%)).
Замечание: Всех избирателей области ассоциируем с обласным центром.