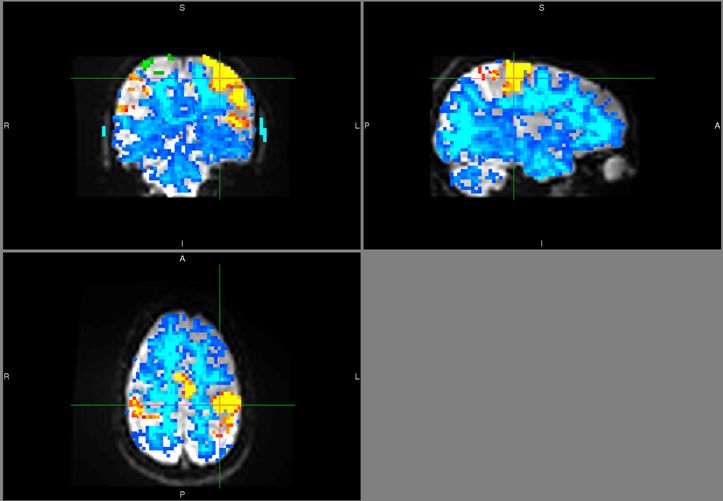
В качестве иллюстрации ЕМ-алгоритма используем пример, приведенный
Andrew Moore’s tutorial:
Начальное приближение.
Результат первой итерации.
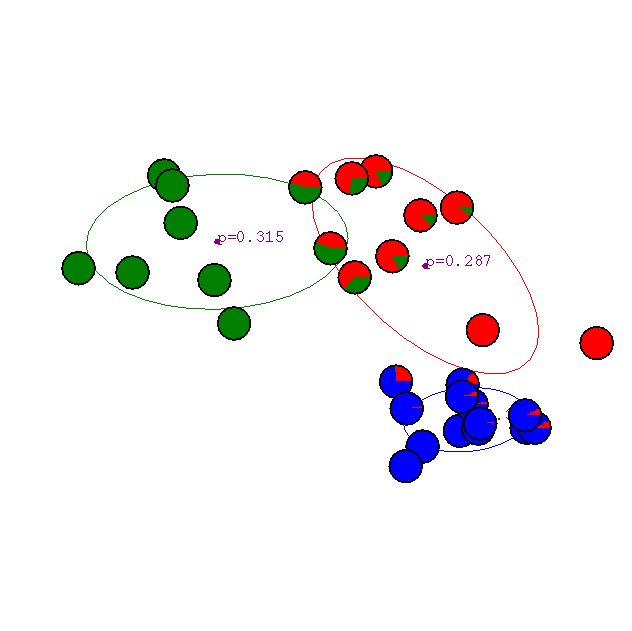
Что получилось после шестой итерации.
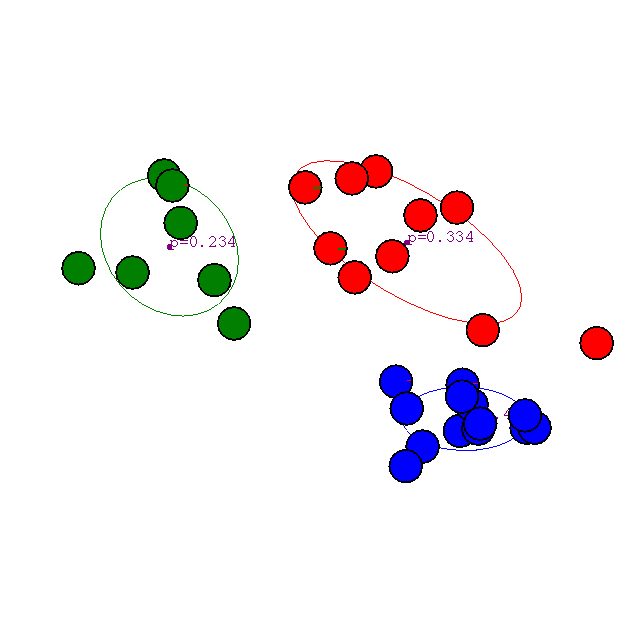
Результат применения двадцати итераций
Приведем простой пример применения EM-алгоритма для случая одной переменной.
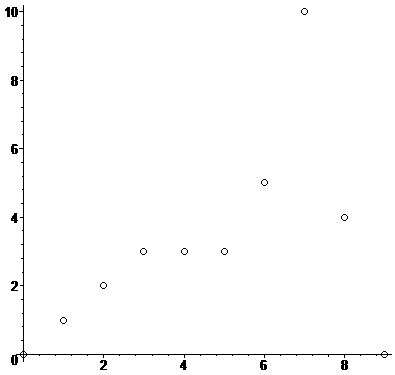
Для данных смеси \(x_i\) \(i=0,1,...,N\), где \(N=10\)
построим разделение этой смеси линейной комбинацией двух функций Гаусса
\[
P(t)=\omega_0\frac{1}{\sqrt{2\pi}\sigma_0}\exp\left(-\frac{(t-\mu_0)^2}{2\sigma^2_0}\right)+
\omega_1\frac{1}{\sqrt{2\pi}\sigma_1}\exp\left(-\frac{(t-\mu_1)^2}{2\sigma^2_1}\right).
\]
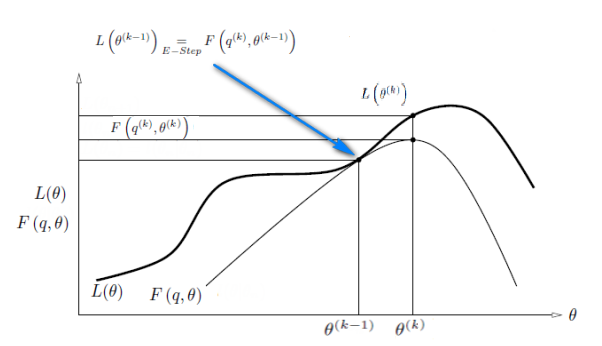
Данная задача представляет собой задачу разделения гистограмм, постановка которой несколько отличается от классической задачи разделения смеси распределений вероятностей, поэтому используем модификацию ЕМ-алгоритма, с учетом этих особенностей.
Вначале проведем инициализацию
\[
g_{0,i}=\left\{
\begin{array}{ll}
1, & \hbox{ для } i=0,...,N/2-1 \\
0, & \hbox{ для } i=N/2,...,N-1,
\end{array}
\right.
g_{1,i}=\left\{
\begin{array}{ll}
0, & \hbox{ для } i=0,...,N/2-1 \\
1, & \hbox{ для } i=N/2,...,N-1.
\end{array}
\right.
\]
| g_0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
|---|
| g_1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 |
|---|
| i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|
M-шаг
Вычислим веса
\[
\omega_j=\frac{1}{N}\sum_{i=0}^{N-1}g_{j,i}x_i, j=0,1.
\]
Получаем \(\omega_0=0.9\) и \(\omega_1=2.3\), далее найдем матожидание и дисперсию
\[
\mu_j=\frac{1}{N}\sum_{i=0}^{N-1}\frac{g_{j,i}i}{\omega_j}x_i,
\sigma^2_j=\frac{1}{N}\sum_{i=0}^{N-1}\frac{g_{j,i}(i-\mu_i)^2}{\omega_j}x_i, j=0,1.
\]
\(\mu_0=\frac{26}{9}\), \(\mu_1=\frac{153}{23}\) и \(\sigma^2_0=\frac{80}{81}\), \(\sigma^2_1=\frac{442}{529}\).
На следующем шаге найдем приближенное значение смеси
\[
P_i=\sum_{j=0}^1\omega_jp_{j,i},i=0,1,...,N-1,
\]
где
\[
p_{j,i}=\frac{1}{\sqrt{2\pi}\sigma_j}\exp\left(-\frac{(i-\mu_j)^2}{2\sigma^2_j}\right),i=0,...,N-1,j=0,1.
\]
Отсюда
| P | 0.005283916006 | 0.05934794968 | 0.2421790495 | 0.3593770365 | 0.2338353195 |
0.2082958290 | 0.9337804754 | 0.7809344621 | 0.3384793202 | 0.03707425040 |
|---|
| i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|
E-шаг
Обновим значения
\[
g_{j,i}=\frac{\omega_jp_{j,i}}{P_i}
\]
| g_0 | 0.9999999994 | 0.9999999158 | 0.9999901639 | 0.9990458670 | 0.9284007156 |
0.1618314989 | 0.003445026 | 0.0000744 | 0.00000193 | 0.00000006 |
|---|
| g_1 | 0.0000000006 | 0.0000000842 | 0.00000983 | 0.0009541 | 0.07159928445 |
0.8381685009 | 0.9965549736 | 0.9999255828 | 0.9999980734 | 0.9999999401 |
|---|
| i | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|
Далее переходим к следующей итерации, проводя М-шаг, потом Е-шаг и так далее.
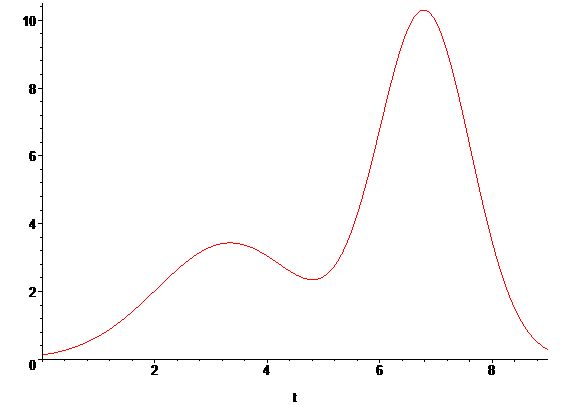
Уже после десятой итерации имеем \(\omega_0=1.114632089\), \(\omega_1=2.085367911\),
\(\mu_0=3.340349207\), \(\mu_1=6.798195901\), \(\sigma^2_0=1.693040680\), \(\sigma^2_1=0.6711715483\).
Получаем
\[
P(t)=\omega_0\frac{1}{\sqrt{2\pi}\sigma_0}\exp\left(-\frac{(t-\mu_0)^2}{2\sigma^2_0}\right)+
\omega_1\frac{1}{\sqrt{2\pi}\sigma_1}\exp\left(-\frac{(t-\mu_1)^2}{2\sigma^2_1}\right)=
0.3417495181\exp\left(-\frac{(t-3.340349207)^2}{3.386081360}\right)+
1.015490777\exp\left(-\frac{(t-6.798195901)^2}{1.342343097}\right).
\]
Остается провести масштабирование (так как мы восстанавливали не вероятности, а, по сути, гистограмму).
Для этой цели найдем масштабирующий коэффициент S, который выбирается так, чтобы площадь полученной смеси была равна площади гистограммы, то есть
\[
S=\frac{\sum_ix_i}{\int_0^NP(t)dt}=\frac{32}{3.186774135}=10.04150236,
\]
и получим результат
\[
S\left(\omega_0\frac{1}{\sqrt{2\pi}\sigma_0}\exp\left(-\frac{(t-\mu_0)^2}{2\sigma^2_0}\right)+
\omega_1\frac{1}{\sqrt{2\pi}\sigma_1}\exp\left(-\frac{(t-\mu_1)^2}{2\sigma^2_1}\right)\right)=
3.431678591\exp\left(-\frac{(t-3.340349207)^2}{3.386081360}\right)+
10.19705303\exp\left(-\frac{(t-6.798195901)^2}{1.342343097}\right).
\]