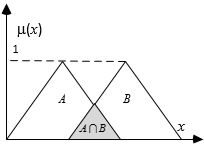
Fuzzy decision

|
|
Fuzzy decision |
|
ЕСЛИ \(x\) равно \(A\) ТОГДА \(y\) равно \(B\),
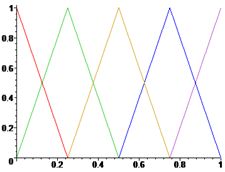
где \(x\) и \(y\) - лингвистические переменные, \(A\) и \(B\) - лингвистические величины, определенные нечеткими множествами на универсумах \(X\) и \(Y\) соответственно.Монотонный выбор значений облачности (в баллах).
А как быть, если правило нечеткого вывода имеет несколько частей?ЕСЛИ погода морозная И лежит снег ТОГДА будет лыжная прогулка.
ЕСЛИ погода хорошая ИЛИ приятная компания ТОГДА пикник удался.
Результатом каждого правила является нечеткое множество, но обычно нам нужно получить единственное число. Другими словами, мы хотим получить точное решение, а не нечеткое. Чтобы получить одно четкое решение для выходной переменной, нечеткая экспертная система вначале агрегирует все выходные нечеткие множества в одно выходное нечеткое множество, а затем собирает полученный нечеткий набор в одно число.Если \(x\) есть \(A_1\) и \(y\) есть \(B_1\), ТО \(z\) есть \(C_1\),
Если \(x\) есть \(A_2\) и \(y\) есть \(B_2\), ТО \(z\) есть \(C_2\).
Алгоритм Mamdani. В системах типа Mamdani база знаний строится из нечетких высказываний вида «z есть α» с помощью связок «И», «ЕСЛИ-ТО». Этапы нечеткого вывода реализуются следующим образом:
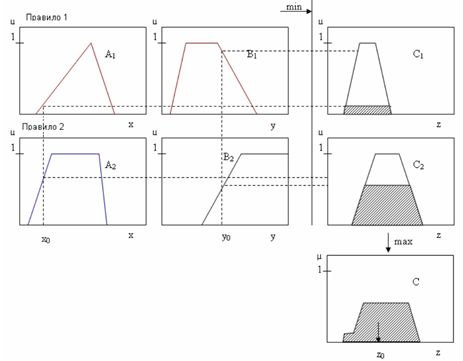
Алгоритм Mamdani.
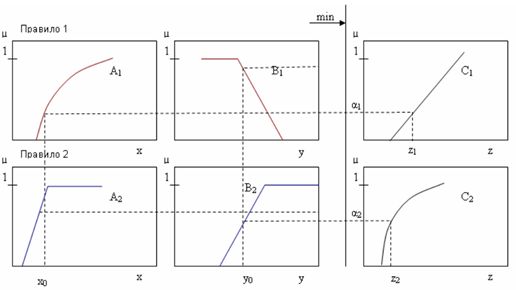
Алгоритм Tsukamoto.
Если \(x\) есть \(A_1\) и \(y\) есть \(B_1\), ТО \(z_1=a_1x+b_1y\),
Если \(x\) есть \(A_2\) и \(y\) есть \(B_2\), ТО \(z_2=a_2x+b_2y\).
Этапы нечеткого вывода:
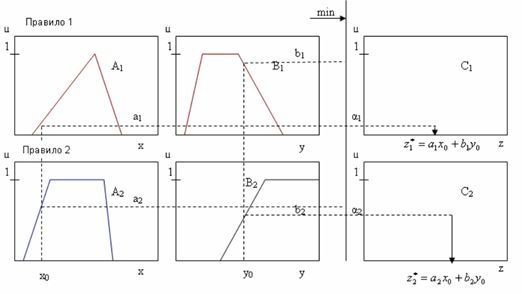
Алгоритм Sugeno.
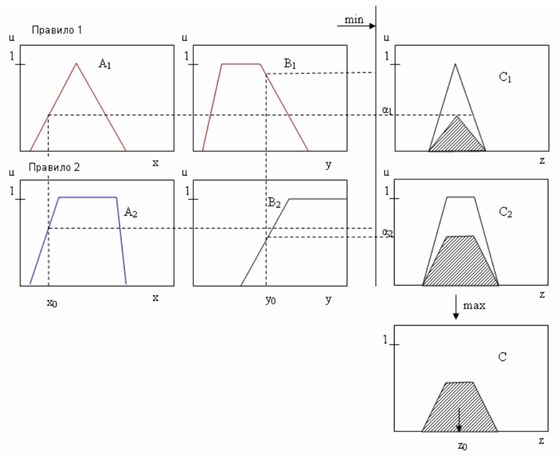
Алгоритм Larsen.
\(\mu_{финансирование = недостаточно}\)(35) = 0,5;
\(\mu_{финансирование = критично}\) (35) = 0,2;
\(\mu_{финансирование = адекватно} \) (35) = 0,0.
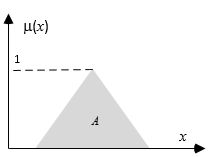
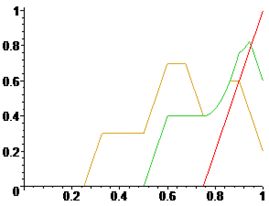
Имеем следующее визуальное представление этой процедуры:
Нечеткое представление финансирования проекта.
Ниже приведены нечеткие значения для проект_штат.\(\mu_{штат= малый}\) (60) = 0,1
\(\mu_{штат= большой}\) (60) = 0,7.
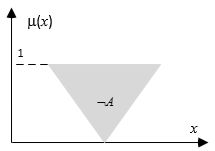
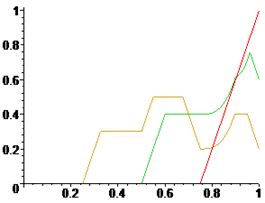
Ниже приведено визуальное представление этой процедуры:Нечеткое представление штата сотрудников проекта.
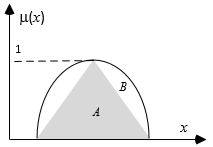
\(\mu_{риск = низкий} = \max [\mu_{финансирование = адекватный}\) (35), \(\mu_{штат= малый}\) (60)\(] = \max[\) 0.0,0.1] = 0.1
Правило 2 - Если финансирование является критичным или штат- большим, то риск нормальный.\(\mu_{риск = нормальный} = \min[\mu_{финансирование = критичное}\) (35), \(\mu_{штат= большой}\) (60)\(] = \min \){0.2, 0.7} = 0.2.
Правило 3 - Если финансирование недостаточно, тогда риск высокий\(\mu_{риск = высокий}\) = 0.5.
Результаты оценки правилаОценка малости риска проекта.
\(\mu_{риск = нормально}\) (z) =0.2
Оценка нормального риска проекта.
\(\mu_{риск = высокий}\) (z) = 0.5
Оценка высокого риска проекта.
Мы выполняем объединение на всех масштабируемых функциях для получения конечного результата. Результат снова отображается зеленым цветом.Оценка общего риска проекта.
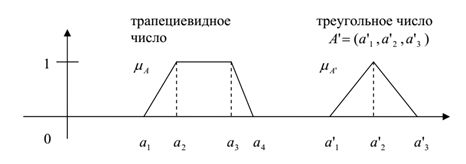
Трапецевидные и треугольные нечёткие числа.
cp(A1) = 10.5 < cp(A3) = 11.75 < cp(A2 ) = 13.25 .
Наилучшим является второй проект, далее следуют третий и первый проекты. Метод Чанга приводит к следующему результатуch(A2 ) = 15 < ch(A1) = 17 < ch(A) = 25.5 ,
то есть второй проект оказывается наихудшим.kg1(A1) = 5.33 < kg1(A3) = 5.83 < kg1(A2) = 6.5 ,
что совпадает с результатом метода Чью-Парка.d1: «Если X1 = НИЗКАЯ и X2=ХОРОШЕЕ, то S=ВЫСОКАЯ»
В общем случае высказывание имеет видdi: «Если X1=A1,i и X2=A2,i и ... Xp=Ap,i, то S=Bi».
Обозначим пересечение \(X_i=A_{1,i}\cap X_2=A_{2,i}\cap\ldots X_p=A_{p,i}\) через \(X=A_i\). Операции пересечения нечетких множеств соответствует нахождение минимума их функций принадлежности \[ \mu_{A_i}(v)=\min_{v\in V}\left\{\mu_{A_{i,1}}(u_1),\mu_{A_{i,2}}(u_2),...,\mu_{A_{i,p}}(u_p)\right\} \] где \(V=U_1\times U_2\times ...\times U_p \), \(v=(u_1,u_2,..., u_p)\), \(\mu_{A_{i,j}}(u_j)\) - значение принадлежности элемента \(u_j\) нечеткому множеству \(A_{i,j}\) . Тогда высказывание примет видdi: «Если X=Ai, то S=Bi»
Обозначим базовое множество (U или V) через W. Тогда Ai - нечеткое подмножество W, в то время как Bi-нечеткое подмножество единичного интервала I.U={ВЫСОКАЯ, ДОСТАТОЧНО ВЫСОКАЯ, СРЕДНЯЯ, ДОСТАТОЧНО НИЗКАЯ, НИЗКАЯ}
Словарь может быть расширен введением модификаторов, таких какОЧЕНЬ, ВПОЛНЕ, БОЛЕЕ-МЕНЕЕ.
Полезность может быть интерпретирована как лингвистическая переменная, значения которой есть термы нечеткого множества, определенного на интервале [0,1]. Знание о полезности задается нечетким отношением Ф из \(D=\{d_i^{(n)}\}\) в \(U=\{u\}\) , являющимся нечетким множеством на декартовом произведении \(D\times U\). Ф характеризуется с помощью функции \(\mu_{\Phi}(d^{(n)},u)\), посредством которой каждой паре присваивается значение из интервала [0,1]. Отношение Ф обычно представляется в виде таблицы, дающей полезность различных точек из D.
Выбор альтернатив с использованием нечеткой логикиВыбрать наиболее подходящего адвоката. |

|