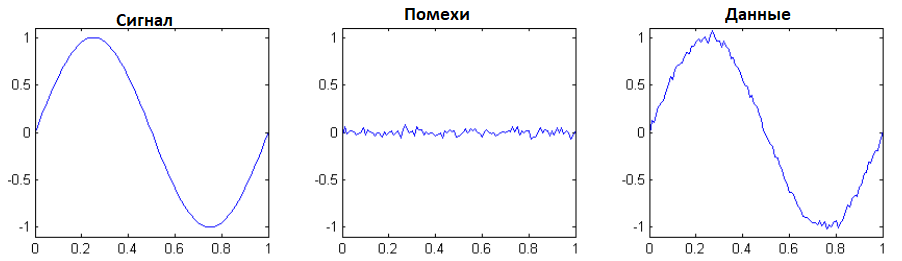
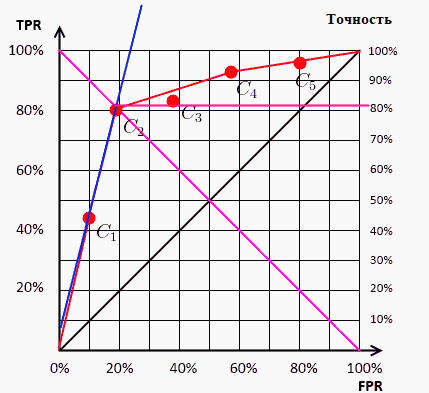
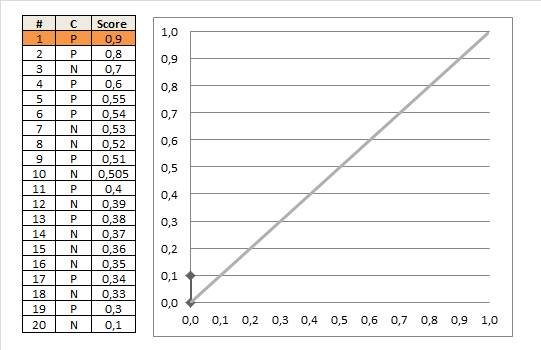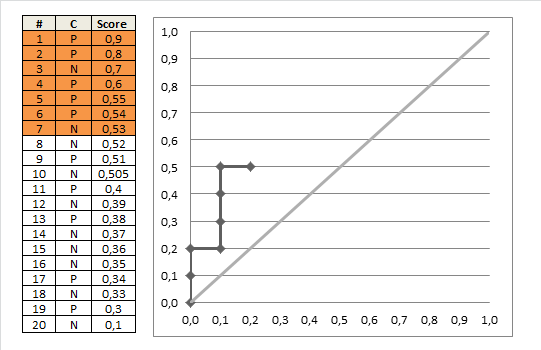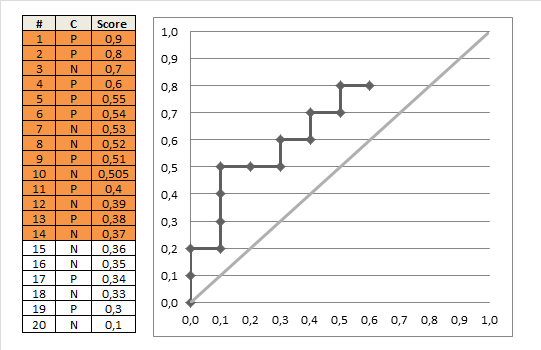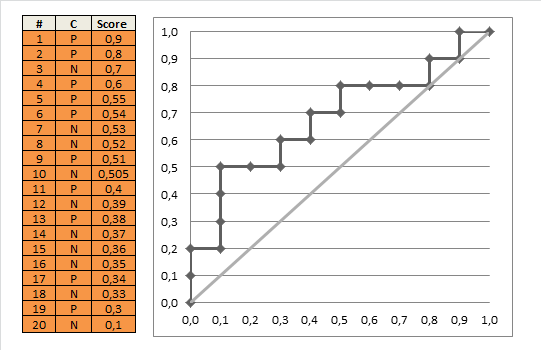
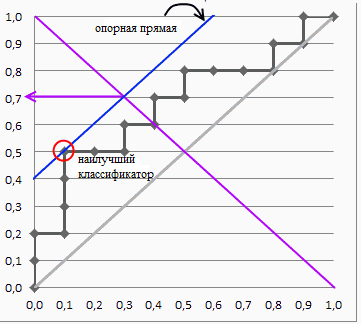
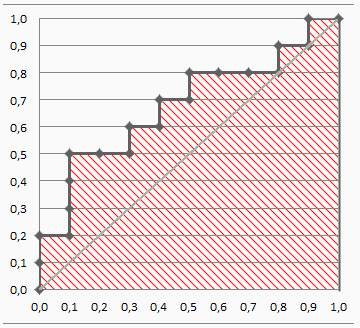
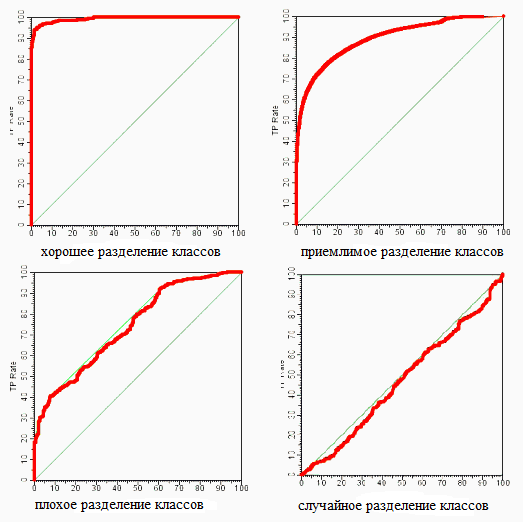
Далее речь пойдет о построении оптимальных (адаптивно- оптимальных для функции \(f(M)\)) фильтров. Естественно,
когда речь идет о построении оптимальных фильтров, нужно определить класс функций, среди которых будем искать
оптимальные. Естественно, чем уже этот класс, тем быстрее будет реализована реконструкция -- так, при использовании
фильтров размером \(3\times 3\), каждый их фильтров представим в виде линейной комбинации не более девяти функций
"ступенек". При этом, если наложить условие симметрии, то число используемых "ступенек" можно существенно уменьшить.
Пусть \(\mathbf{U}^n\) линейное многообразие фильтров размером \(n\). Пусть \(\left\{u^k\right\}_{k=0}^{n-1}\) множество фильтров,
линейная оболочка которых совпадает с \(\mathbf{U}^n\). Тогда \(\forall u\in\mathbf{U}^n\)
\[
u(M)=\sum_{k=0}^{n-1}\alpha_ku^k(M).
\]
\(f(M)\) функция из пространства \(L_2\), кроме того, дан фиксированный набор точек
\(\left\{M_k\right\}_{k=1}^m\) и вес \(p(M)\).
Фильтр \(\widehat{u}\in\mathbf{U}^n\) будем называть оптимальным для функции \(f(M)\) (при фиксированных точках
\(\left\{M_k\right\}_{k=1}^m\), веса \(p(M)\) и класса \(\mathbf{U}^n\)), если для любых \(c_k\) и \(\forall u\in\mathbf{U}^n\)
\begin{equation}\label{9}
\left\|f(\cdot)-\sum_{k=1}^{m}\widehat{c}_k(f,\widehat{u})\widehat{u}(\cdot-M_k)\right\|_2\le
\left\|f(\cdot)-\sum_{k=1}^{m}{c}_k{u}(\cdot-M_k)\right\|_2.
\end{equation}
Перефразируем эту задачу следующим образом. Пусть \(\left\{u^k\right\}_{k=0}^{n-1}\) множество фильтров, линейная
оболочка которых совпадает с \(\mathbf{U}^n\). Нужно найти линейную комбинацию фильтров \(\left\{u^k\right\}_{k=0}^{n-1}\) так,
чтобы в результате получить оптимальный фильтр \(\widehat{u}(M)\), то есть подобрать числа
\(\left\{\beta_k\right\}_{k=1}^{n-1}\) так, чтобы получить фильтр
\[
\widehat{u}(M)=u^0(M)+\sum_{k=1}^{n-1}\beta_ku^k(M),
\]
то есть найти оптимальный фильтр на классе \(\mathbf{U}^n\).
Наши дальнейшие построения будут посвящены определению чисел \(\left\{\beta_k\right\}_{k=1}^{n-1}\).
Пусть \(\left\{\widehat{c}_k(f,u^0)\right\}_{k=1}^{m}\) домен, полученный оптимальной фильтрацией сдвигами фиксированного
фильтра \(u^0(M)\) по системе точек \(\left\{M_k\right\}_{k=1}^m\). Положим далее \(f_\nu(M)\) восстановление
(реконструкция) фильтром \(u^\nu(M)\) по домену \(\left\{\widehat{c}_k(f,u^0)\right\}_{k=1}^{m}\), то есть
\[
f_\nu(M)=\sum_{i=1}^m\widehat{c}_i(f,u^0)u^\nu(M-M_i).
\]
Рассмотрим систему линейных уравнений
\[
\sum_{\mu=1}^{n-1}\beta_\mu\left\lt f_\nu, f_\mu\right\gt= \left\lt f, f_\nu\right\gt - \left\lt f_0, f_\nu\right\gt
\]
для всех \(\nu=1,\ldots,n-1.\)
Решая эту систему, полагаем
\[
u^0(M):=u^0(M)+\sum_{\mu=1}^{n-1}\beta_\mu u^\mu(M).
\]
Для нового фильтра \(u^0(M)\) вновь по сдвижкам \(\left\{M_k\right\}_{k=1}^m\) проведем оптимальную фильтрацию и найдем
новый домен \(\left\{\widehat{c}_k(f,u^0)\right\}_{k=1}^{m}\) и продолжим итерацию, пока коэффициенты домена не
стабилизируются. После этого положим \(\widehat{u}^0(M)=u^0(M)\). Процесс сходится достаточно быстро.
Заметим, что в описанном алгоритме мы не накладываем
никаких условий на фильтр. Если потребовать, чтобы фильтр был симметричным, то качество восстановления, естественно,
несколько ухудшится, но информация о фильтре существенно сократится.
Пусть, теперь даны две системы точек \(\left\{M_k\right\}_{k=1}^m\) и \(\left\{N_k\right\}_{k=1}^m\), а также два множества
фильтров \(\mathbf{U}^n\) и \(\mathbf{V}^n\). При фиксированных \(\left\{M_k\right\}_{k=1}^m\), \(\left\{N_k\right\}_{k=1}^m\), веса
\(p(M)\) и классов \(\mathbf{U}^n\), \(\mathbf{U}^m\), нужно найти такие \(\widehat{u}\in\mathbf{U}^n\) и \(\widehat{v}\in\mathbf{V}^n\), что для любых
\(c_k, b_k\) и \(\forall u\in\mathbf{U}^n, \forall v\in\mathbf{V}^n\)
\begin{equation}\label{10}
\left\|f(\cdot)-\sum_{k=1}^{m}\widehat{c}_k(f,\widehat{u})\widehat{u}(\cdot-M_k)
-\sum_{k=1}^{m}\widehat{b}_k(f,\widehat{v})\widehat{v}(\cdot-N_k)\right\|_2\le
\end{equation}
\[
\left\|f(\cdot)-\sum_{k=1}^{m}{c}_k{u}(\cdot-M_k)-\sum_{k=1}^{m}{b}_k{v}(\cdot-N_k)\right\|_2.
\]
Пусть \(\widehat{u}^0\in\mathbf{U}^n\) фильтр оптимальный для функции \(f(M)\) (при фиксированных точках
\(\left\{M_k\right\}_{k=1}^m\), то есть получен из условий (\ref{9}). Для ошибки восстановления \(\Delta
f(M)=f(M)-f_0(M)\) найдем оптимальный фильтр \(\widehat{v}^0\in\mathbf{V}^n\). Тогда для \(\widehat{u}\in\mathbf{U}^n\) и
\(\widehat{v}\in\mathbf{V}^n\) определяемых условиями (\ref{10}) будет иметь место соотношение
\begin{equation}\label{11}
\left\|f(\cdot)-\sum_{k=1}^{m}\widehat{c}_k(f,\widehat{u})\widehat{u}(\cdot-M_k)
-\sum_{k=1}^{m}\widehat{b}_k(f,\widehat{v})\widehat{v}(\cdot-N_k)\right\|_2\le
\end{equation}
\[
\left\|f(\cdot)-\sum_{k=1}^{m}\widehat{c}_k(f,\widehat{u}^0)\widehat{u}^0(\cdot-M_k)
-\sum_{k=1}^{m}\widehat{b}_k(f,\widehat{v}^0)\widehat{v}^0(\cdot-N_k)\right\|_2.
\]
Ввиду того, что левая часть этого неравенства не намного отличается от правой, то можно построить итерационный процесс,
позволяющий получить оптимальные фильтры \(\widehat{u}\in\mathbf{U}^n\) и \(\widehat{v}\in\mathbf{V}^n\).
Алгоритм выглядит следующим образом.
Используя стартовый фильтр из множества \(\mathbf{U}^n\) при фиксированных точках \(\left\{M_k\right\}_{k=1}^m\), веса \(p(M)\) и
класса \(\mathbf{U}^n\) построим оптимальный фильтр \(u^*(M)\) и, соответственно, домен
\(\left\{\widehat{c}_k(f,u^*)\right\}_{k=1}^{m}\). Реконструкция по полученному фильтру и домену будет иметь вид
\[
f(u^*,M)=\sum_{i=1}^m\widehat{c}_i(f,u^*)u^*(M-M_i).
\]
Используя ошибку восстановления \(\Delta f(M)=f(M)-f(u^*,M)\) в качестве исходных данных, находим оптимальный фильтр
\(v^*(M)\) из множества \(\mathbf{U}^n\) и, соответствующий домен \(\left\{\widehat{c}_k(f,v^*)\right\}_{k=1}^{m}\).
Далее, используя \(f(M)-f(v^*,M)\) в качестве исходных данных и стартовый фильтр \(u^*(M)\), получаем новый фильтр
\(u^*(M)\) и, соответствующий домен \(\left\{\widehat{c}_k(f,u^*)\right\}_{k=1}^{m}\). Повторяя этот процесс, получим пару
оптимальных фильтров \(\widehat{u}(M)\) и \(\widehat{v}(M)\).
В этом случае, наряду с определением оптимальных доменов на каждом уровне итерации заново вычисляются значения
фильтров. В начале последовательно улучшаем, как было показано в предыдущем разделе, коэффициенты \(c_k\) и \(b_k\), потом
"поправляем" фильтр \(u(M)\), находим реконструкцию, и по ошибке реконструкции "поправляем" фильтр \(v(M)\) и т.д.
Для трех базисных функций, вначале находим \(u^*(M)\) и \(v^*(M)\), потом по полученной ошибке
находим функцию \(w^*(M)\) и процесс повторяем.
Этот алгоритм легко обобщается на случай произвольного числа базисных функций.
Заметим, что в результате применения этого алгоритма к полной системе базисных функций, получим ошибку восстановления
равную нулю.
Полученный алгоритм устойчив как по ошибке, так и по коэффициентам оптимальных доменов, но сходимость по фильтрам не
устойчива, что говорит о скрытых внутренних связях фильтров внутри одного класса. Другой особенностью формирования
оптимальных фильтров является зависимость скорости сходимости от вида стартового фильтра. В качестве первого
(низкочастотного) фильтра следует брать центрально-симметричный фильтр Гаусса, а вот относительно вида симметрии
остальных фильтров, то об этом сложно судить. Традиционная теория всплесков в этом случае использует зеркально-
квадратурные функции. Однако в этом случае все зеркально- квадратурные базисные функции восстанавливают исходные данные
практически одинаково. В нашей постановке каждая последующая базисная функция принимает меньшее участие в
восстановлении данных, чем предыдущая, что существенно отличается от используемых детерминированных всплесков.
Проиллюстрируем вышесказанное примерами.

Тестовое изображение Lena.
Для тестового рисунка Lena возьмем фильтр Хаара в качестве стартового
\[
u=\left[
\begin{array}{rrrrrr}
0 & 0 & 0& 0& 0& 0 \\
0 & 0 & 0& 0& 0& 0 \\
0 & 0 & 1& 1& 0& 0 \\
0 & 0 & 1& 1& 0& 0 \\
0 & 0 & 0& 0& 0& 0 \\
0 & 0 & 0& 0& 0& 0 \\
\end{array}
\right],
\]
ошибка фильтрации этим фильтром равна 27692547,0.
После первой итерации получим фильтр
\[
u=\left[
\begin{array}{rrrrrr}
0,044 & 0,0054 & -0,072 & -0,0908 &-0,0179& 0,0386\\
-0,0235& -0,0259 &0,0697 & 0,0931& 0,0031 & -0,0237\\
-0,0973& 0,0697&0,484& 0,5142& 0,1157& -0,0874\\
-0,088 & 0,1157& 0,5181& 0,4836 & 0,0684 & -0,0966\\
-0,0245& 0,0039& 0,0961& 0,0673& -0,0283&-0,021\\
0,0376 & -0,017 & -0,0887& -0,0747& 0,0036& 0,0457\\
\end{array}
\right],
\]
ошибка фильтрации которым равна 13134435.
Пятая итерация приведет к фильтру
\[
u=\left[
\begin{array}{rrrrrr}
0,0343 & -0,0119& -0,0573 &-0,0767& -0,0321& 0,0324\\
-0,0305& -0,0401& 0,0742& 0,1009& 0,0002 & -0,0246\\
-0,0746& 0,1031&0,4387& 0,4704& 0,1542 & -0,0627\\
-0,0617& 0,1576& 0,4751& 0,4359& 0,0997& -0,0742\\
-0,0251& 0,0016 & 0,1035& 0,0703& -0,0416&-0,0265\\
0,0306& -0,0321& -0,0747& -0,0601& -0,0126& 0,037
\end{array}
\right],
\]
ошибка фильтрации которым равна 12463387.
Двадцатая итерация дает фильтр
\[
u=\left[
\begin{array}{rrrrrr}
0,0042 & -0,0351 &-0,0441& -0,0479& -0,0359& 0,0066\\
-0,0431& -0,0369& 0,0624 & 0,084 & 0,0092& -0,0226\\
-0,0091& 0,1513&0,3739& 0,3862& 0,1846& 0,0077\\
0,0153& 0,1983& 0,393 & 0,3631& 0,1395 & -0,0101\\
-0,02& 0,0101& 0,081 & 0,0567& -0,0339&-0,0351\\
0,0045 & -0,0403& -0,0502& -0,0435& -0,0296& 0,009\\
\end{array}
\right],
\]
дающий ошибку фильтрации 1193178.
Приведем в качестве примера полную систему оптимальных непересекающихся фильтров для каждой цветовой компоненты
тестового изображения Lena.
Для компоненты Red полная система оптимальных четырехполосных фильтров имеет вид
\[
u^0_R=\left[
\begin{array}{rrrr}
0,0067 & 0,0751& 0,0734& 0,0124\\
0,1311& 0,2956& 0,2804& 0,1061\\
0,1655& 0,3204& 0,2555& 0,0931\\
0,0357& 0,1067& 0,0535& -0,0079\\
\end{array}
\right],
\]
\[
u^1_R=\left[
\begin{array}{rrrr}
-0,9439& -0,2858& 0,838& -0,3891\\
0,5188 & 0,9338 & 2,2864 & -0,0711\\
-2,4294& -1,7192& 0,4694 & -0,9228\\
-0,6853& 0,1831& 0,9279& 0,7125\\
\end{array}
\right],
\]
\[
u^2_R=\left[
\begin{array}{rrrr}
-0,3753& 0,2395& 0,0279& 0,0815\\
0,0551& 1,121& -0,5542& -0,025\\
-0,1452& 0,1464& -0,238& 0,1437\\
-0,0806& -0,0221&0,1039& -0,2341\\
\end{array}
\right],
\]
\[
u^3_R=\left[
\begin{array}{rrrr}
0,0995& -0,0854& -0,1311& 0,3194\\
-0,2824& 0,2691 & -0,475& 0,17\\
0,3369& -0,1834& 0,8283& -0,7653\\
-0,1554& 0,1689&-0,1051& 0,3738\\
\end{array}
\right].
\]
Для компоненты Green полная система оптимальных четырехполосных фильтров имеет вид
\[
u^0_G=\left[
\begin{array}{rrrr}
0,0102& 0,0727& 0,0933& 0,0362\\
0,0924& 0,2508& 0,2746& 0,1182\\
0,1313& 0,2861& 0,2686& 0,1084\\
0,0537& 0,1182& 0,0823& 0,0159\\
\end{array}
\right],
\]
\[
u^1_G=\left[
\begin{array}{rrrr}
0,2533& -0,7758& 0,8652& -0,5277\\
0,9539 & -0,3739& 1,9352 & -0,6654\\
-0,5798& -1,6429& 1,0226& -0,7823\\
0,041 & -0,6235& 0,447 & -0,0384\\
\end{array}
\right],
\]
\[
u^2_G=\left[
\begin{array}{rrrr}
-0,4064& 0,0352 & 0,1164& -0,0684\\
0,3046 & 1,1586& 0,0993& -0,031\\
-0,1368& -0,0079& -0,0606& 0,0317\\
-0,0621& -0,0314& 0,093& 0,0247\\
\end{array}
\right],
\]
\[
u^3_G=\left[
\begin{array}{rrrr}
0,1203& -0,0223& -0,1971& 0,1383\\
-0,1196& 0,3729& -0,0364& 0,0889\\
0,2533& 0,099& 0,9036& -0,4958\\
-0,1403& 0,0845& -0,1747& 0,2263\\
\end{array}
\right],
\]
и, наконец, для Blue
\[
u^0_B=\left[
\begin{array}{rrrr}
0,0046& 0,0467& 0,0928& 0,0472\\
0,0782& 0,2398& 0,2885& 0,1261\\
0,128 & 0,3071& 0,2766& 0,1016\\
0,0512& 0,1261& 0,0839& 0,0103
\end{array}
\right],
\]
\[
u^1_B=\left[
\begin{array}{rrrr}
0,2816& -0,5954& 0,6991& -0,3253\\
0,4366& -0,5499& 1,4833& -0,4309\\
-0,0143& -0,9492& 0,9337& -0,4406\\
0,2656& -0,4288&0,105& -0,0921
\end{array}
\right],
\]
\[
u^2_B=\left[
\begin{array}{rrrr}
-0,3882& -0,0791& 0,2369& -0,0981\\
0,2607& 0,9908& 0,3763& 0,0716\\
-0,2032& 0,0023& 0,2344& 0,0218\\
0,0062& 0,072&-0,0009& -0,0157
\end{array}
\right],
\]
\[
u^3_B=\left[
\begin{array}{rrrr}
0,0296& 0,0855 & -0,2593 &0,1418\\
-0,1991& 0,4245 & 0,137 & 0,0829\\
0,2737& 0,1023& 0,8866& -0,3345\\
-0,1448& 0,084 & -0,2874& 0,252
\end{array}
\right].
\]