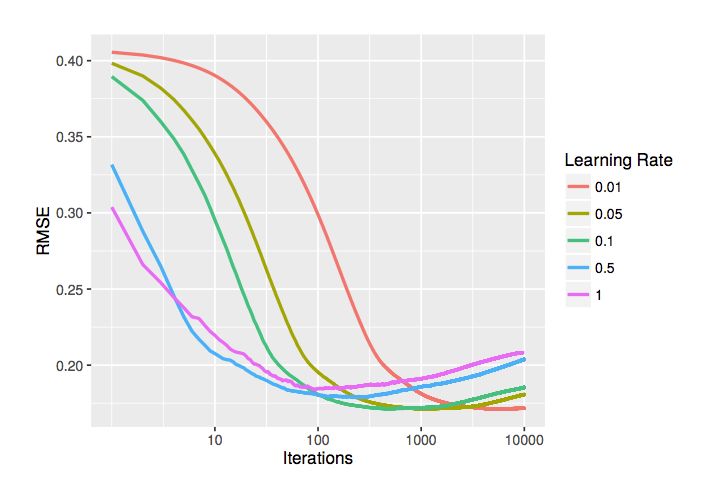
Слово bootstrap (самовытягивание) происходит от выражения: «To pull oneself over a fence by one’s bootstraps» (дословно — «перебраться через ограду,
потянув за ремешки на ботинках». В вольном переводе -"сделать из дерьма конфетку (получить из ничего - что-то)."
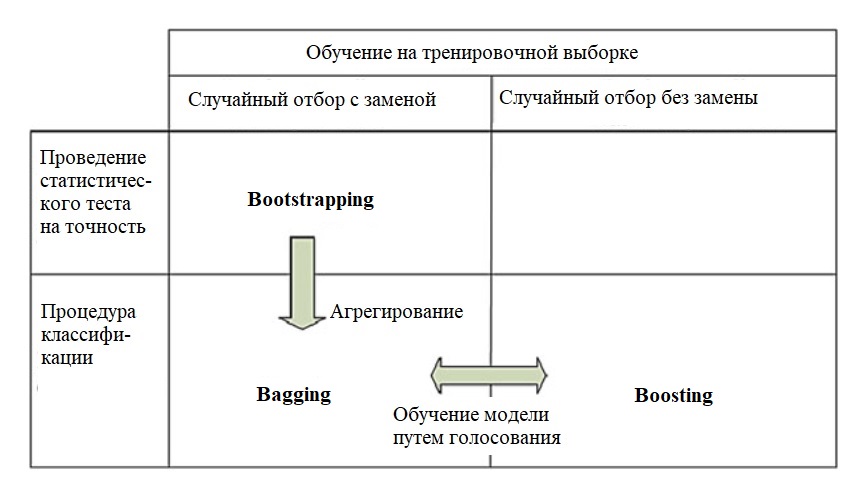
Это статистический метод общего назначения на основе выборок нескольких (непересекающихся) обучающих наборов, полученных случайным образом,
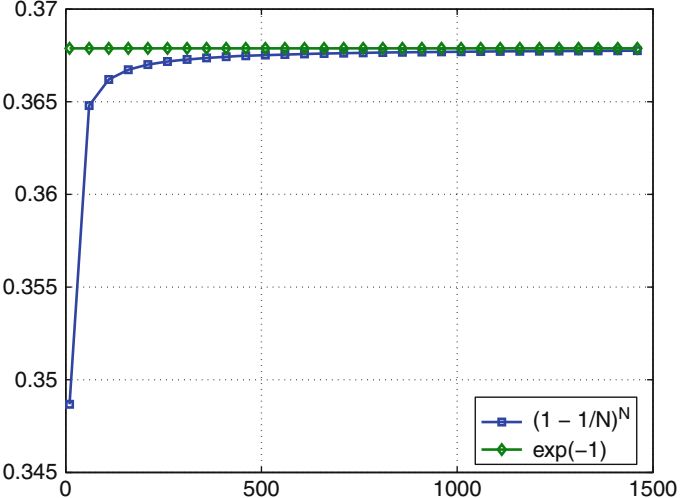
из одного базового набора данных. В наборе данных с N выборками, каждый экземпляр выбран с вероятностью 1 / N, следовательно, после N
розыгрышей (с большим N), вероятность того, что данный экземпляр не был выбран
\[
\left(1-\frac{1}{N}\right)^N\approx \exp(-1)\approx 0.368.
\]
Это означает, что каждый образец содержится примерно в 63,2% случаев наборов.
Классически, bootstrap используется для получения некоторой статистики T (P) о (скажем, бесконечно большой) совокупности P из N выборок
из: \(Z = \{z_1, ..., z_N\}\). Идея чтобы получить B множеств \(Z^*_b\subseteq Z\), для \( b = 1, ..., B\), каждая из которых содержит N
случайных выборок из Z, из которого получены оценки B (P). Эти оценки затем усредняются в окончательную оценку; также возможно получить
оценки дисперсии или доверительные интервалы.
Алгоритм Bootstrap
Ввод.
Исходные данные: выборка размером N: \(Z = \{z_1, z_2, ..., z_N\}\) (потенциально бесконечной) совокупности P.
B - номер бутстрап выборки.
Вывод: Оценка T (P) статистики P.
- for b=1 do
- Выбрать (с заменой) N наборов из Z, получив b-й бутстрап \(Z^*_b\).
- Вычислить для каждой выборки \(Z^*_b\) статистику \(\hat{T}(Z^*_b).\)
- end for
- Вычислить начальную оценку \(\hat{T} (P)\) как среднее значение \(\hat{T}(Z^*_1),\hat{T}(Z^*_2),...,\hat{T}(Z^*_B)\).
- Вычислить точность оценки, используя, например, дисперсию \(\hat{T}(Z^*_1),\hat{T}(Z^*_2),...,\hat{T}(Z^*_B).\)
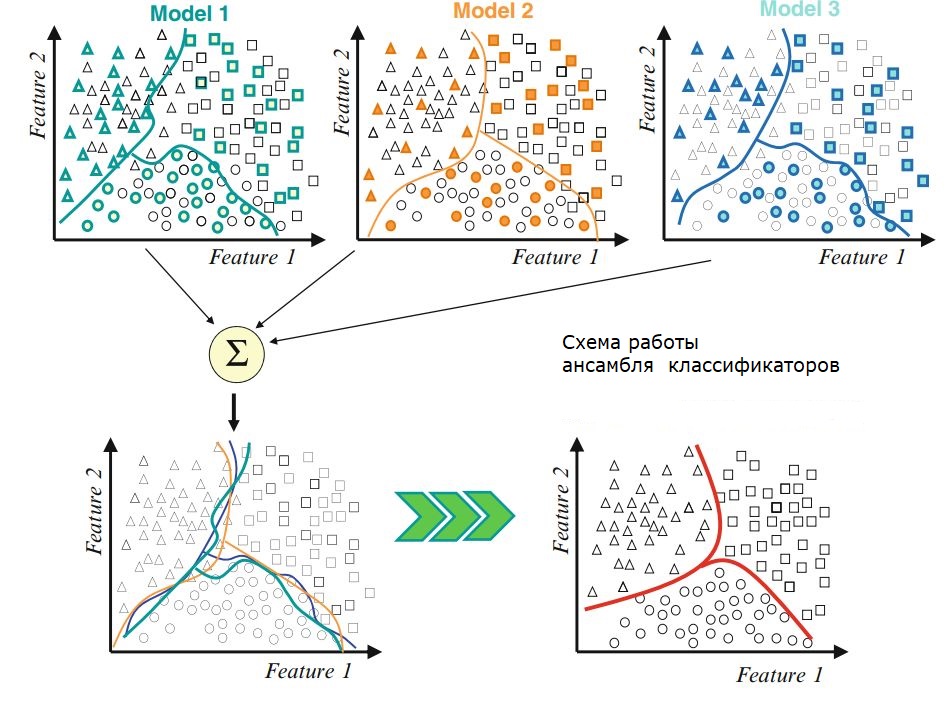
Bagging (агрегация бутстрэп) - это метод, который использует усреднение выборки для уменьшения дисперсии и / или повышения точности
некоторых алгоритмов (может использоваться в классификации и регрессии).
Рассмотрим набор данных размера N: \(Z = \{z_1, z_1, ..., z_N\}\), где \(z_i = (x_i, y_i)\), и \(y_i\) - метка класса в задаче классификации
или действительное число, в задаче регрессии.
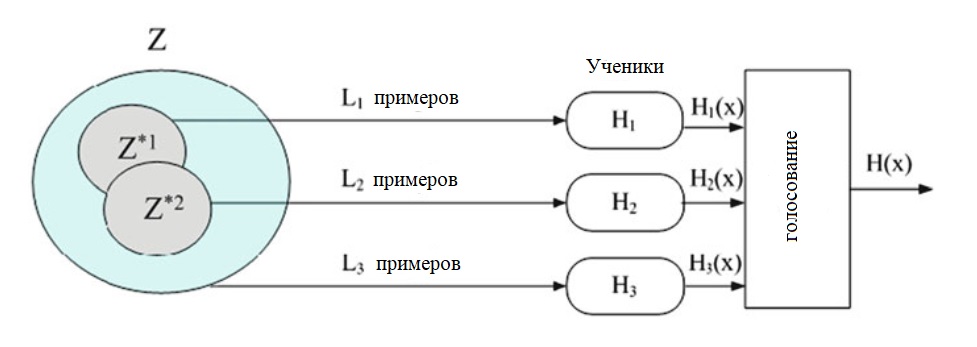
Цель bagging в получении набора В предикторов (каждый из bootstrap выборки \(Z^*_b\subseteq Z\), для \( b = 1, ..., B\))
а затем создать окончательный предиктор путем объединения (путем усреднения, в регрессии или большинство голосов, в классификации).
По сравнению с полным обучающим набором, у агрегации есть два основных преимущества:
- повышает стабильность и точность классификатора;
- уменьшает дисперсию классификатора.
Использование агрегации улучшает результаты классификации всякий раз, когда
базовые классификаторы нестабильны, и это является основной причиной, по которой этот подход
хорошо работает для классификации.
Процедура Bagging для задачи бинарной классификации.
Ввод.
Исходные данные: выборка размером N: \(Z = \{z_1, z_2, ..., z_N\}\), где \(z_i = (x_i, y_i)\), \(x_i\in \mathfrak{X}\) и \(y_i\in \{-1,+1\}\),
B - номер бутстрап выборки.
Вывод: Полученный классификатор \(H:\mathfrak{X}\to \{-1,+1\}\).
- for b=1 do
- Выбрать (с заменой) N наборов из Z, получив b-й бутстрап \(Z^*_b\).
- Вычислить для каждой выборки \(Z^*_b\) обучить классификатор \(H_b\).
- end for
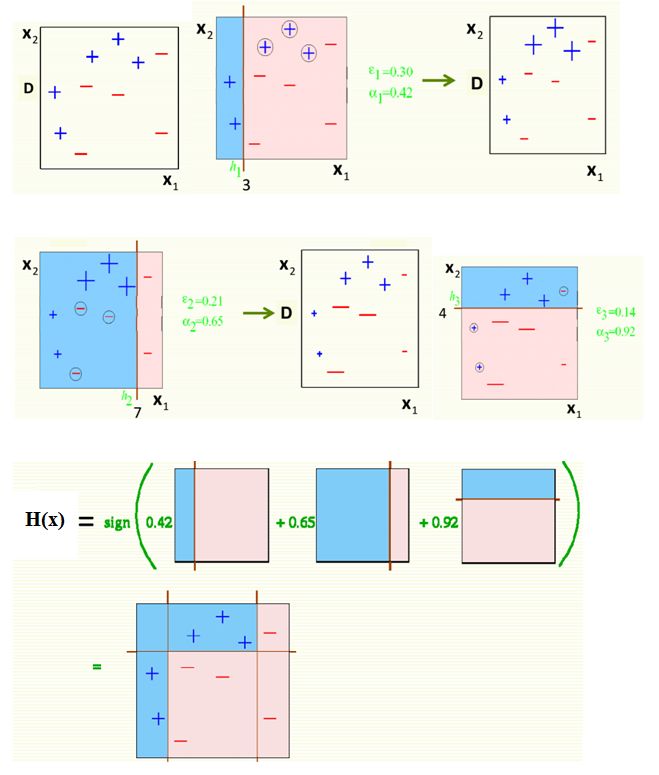
- Найти окончательный классификатор большинством голосов из \(H_1,...,H_B\), то есть
\(H(x)=\textrm{sign} \left(\sum_{b=1}^BH_b(x)\right).\)
Окончательное решение о классификации производится на выходе большинством голосов слабых учеников.