Многие предприятия накапливают большие объемы данных о своей повседневной деятельности. Например, на кассах продуктовых магазинов ежедневно собираются огромные объемы покупательских данных, называемых транзакциями
в покупательской корзине, каждый банк сохраняет информацию об услугах, предоставляемых клиентам, деятельность страховых компаний неразрывно связана с анализом страховых рисков, а уж если говорить о такой сфере жизнедеятельности
как медицина, то на каждого из нас существует множество результатов всяческих анализов и так далее.
Среди этих всех данных существуют скрытые связи, выявление которых позволяет сделать методология, известная как анализ ассоциаций. Это полезно для обнаружения интересных отношений, скрытых в больших наборах данных.
Некоторые из этих ассоциаций достаточно тривиальны - "пиво без водки - деньги на ветер", иные достаточно неожиданные и требуют дополнительного исследования. Одна из наиболее "забавных" и неожиданных ассоциаций приведена
в статье D.J. Power «Ask Dan!».
В 1992 году группа по консалтингу компании Teradata под руководством Thomas Blischok, CEO of MindMeld, Inc. провела исследование 1.2 миллиона транзакций в 25 магазинах для ритейлера Osco Drug.
После анализа всех этих транзакций самым сильным правилом получилось «Между 17:00 и 19:00 чаще всего пиво и подгузники покупают вместе».
Такое правило показалось руководству Osco Drug настолько неконструктивным, что принять решение о том, чтобы пставить подгузники на полках рядом с пивом они не решились.
После подробного исследования данного феномена, объяснение паре пиво-подгузники оказалось вполне логичным: после окончания рабочего дня и возвращения с работы домой (как раз где-то, к 17 часам), жены обычно отправляли
мужей за подгузниками в ближайший магазин. Посланные волей жены, мужья, не долго думая, совмещали приятное с полезным — покупали подгузники по заданию жены и пиво для собственного вечернего времяпрепровождения.
Помимо информации о корзине, анализ ассоциаций также применим к данным из других областей, таких как биоинформатика, медицинская диагностика, веб-анализ и анализ научных исследований.
Например, при анализе данных науки о Земле, закономерности ассоциаций могут выявить интересные связи между океаном, сушей и атмосферными процессами (вспомним феномен Эль-Ниньо, где среди всего прочего, Эль-Ниньо вызывает
экстремальные погодные условия, связанные с циклами частоты возникновения эпидемических заболеваний). Такая информация может помочь лучше понять, как различные элементы
системы Земли взаимодействуют друг с другом.
Приведем некоторые области применения ассоциативных правил:
анализ рыночной корзины;
представление рекомендованных покупок в интернет-магазинах и т.п.;
поиск ошибок в базах данных;
медицинская диагностика;
биохомия, чв частности, анализ белковых последовательностей;
анализ данных переписи населения;
анализ рождаемости;
анализ погодных явлений;
анализ показателей жизнедеятельности человека (по фитнес-трекерам и т.п.).
Существуют две ключевые проблемы, которые необходимо учитывать при применении анализа ассоциаций.
Во-первых, обнаружение шаблонов из большого набора данных транзакций может быть вычислительно дорогим.
Во-вторых, некоторые из обнаруженных паттернов могут быть ложными (случаются просто случайно), и даже для не фиктивных паттернов некоторые более интересны, чем другие.
Ассоциативные правила представляют собой механизм нахождения логических закономерностей между связанными элементами (событиями или объектами). Пусть имеется \(\mathbf{A} = \{a_1, a_2, a_3, \dots, a_n\}\)- конечное
множество уникальных элементов (list of items). Из этих компонентов может быть составлено множество наборов \(\mathbf{T}\) (sets of items), т.е. \(\mathbf{T} \subseteq \mathbf{A}\).
Ассоциативные правила \(\mathcal{A} \rightarrow \mathcal{T}\) имеют следующий вид: если <условие> то <результат>, где в отличие от деревьев классификации, <условие> - не логическое
выражение, а набор объектов из множества \(\mathbf{A}\), с которыми связаны (ассоциированы) объекты того же множества, включенные в <результат> данного правила. Например, ассоциативное правило если
(лес, вода) то (лягушки) означает, что если в лесу встретилось болотце или ручей, то рядом будут лягушки.
Понятие “вид элемента \(a_k\)” легко может быть обобщено на ту или иную его категорию или вещественное значение, т.е. концепция ассоциативного анализа может быть применена для комбинаций любых переменных.
Например, при прогнозировании погоды одно из ассоциативных правил может выглядеть так: 'утром обильная роса' -> 'днем солнечно' = TRUE
Выделяют три вида правил:
полезные правила, содержащие действительную информацию, которая ранее была неизвестна, но имеет логическое объяснение;
тривиальные правила, содержащие действительную и легко объяснимую информацию, отражающую известные законы в исследуемой области, и поэтому не приносящие какой-либо пользы;
непонятные правила, содержащие информацию, которая не может быть объяснена (такие правила или получают на основе аномальных исходных данных, или они содержат глубоко скрытые закономерности, и поэтому для интерпретации непонятных правил нужен дополнительный анализ).
Поиск ассоциативных правил обычно выполняют в два этапа:
в пуле имеющихся признаков \(\mathbf{A}\) находят наиболее часто встречающиеся комбинации элементов \(\mathbf{T}\);
из этих найденных наиболее часто встречающихся наборов формируют ассоциативные правила.
Для оценки полезности и продуктивности перебираемых правил используются различные частотные критерии, анализирующие встречаемость кандидата в массиве экспериментальных данных. Важнейшими из них являются поддержка (support) и достоверность (confidence). Правило \(\mathcal{A} \rightarrow \mathcal{T}\) имеет поддержку \(s\), если оно справедливо для \(s\%\) взятых в анализ случаев:
Достоверность правила показывает, какова вероятность того, что из наличия в рассматриваемом случае условной части правила следует наличие заключительной его части (т.е. из \(\mathcal{A}\) следует \(\mathcal{T}\)):
Алгоритмы поиска ассоциативных правил отбирают тех кандидатов, у которых поддержка и достоверность выше некоторых наперед заданных порогов: minsupport и minconfidence. Если поддержка имеет большое значение, то алгоритмы будут находить правила, хорошо известные аналитику или настолько очевидные, что нет никакого смысла проводить такой анализ. Большинство интересных правил находят именно при низком значении порога поддержки. С другой стороны, низкое значение minsupport ведет к генерации огромного количества вариантов, что требует существенных вычислительных ресурсов или ведет к генерации статистически необоснованных правил.
Используются и другие показатели - подъемная сила, или лифт (lift), которая показывает, насколько повышается вероятность нахождения \(\mathcal{T}\) в анализируемом случае, если в нем уже имеется \(\mathcal{A}\):
и усиление (leverage), которое отражает, насколько интересной может быть более высокая частота \(\mathcal{A}\) и \(\mathcal{T}\) в сочетании с более низким подъемом:
Для иллюстрации рассмотрим простой случай построения ассоциативных правил для пары элементов транзакций. Очевидно, что аналогично можно построить ассоциативные правила для троек элементов и так далее.
Вначале выпишем матрицу частот парного сочетания товаров \(x_i\) и \(x_j\): \(\sigma(x_i\cup x_j)\)
Support (поддержка)
Это нормированное значение парного сочетания товаров
\[
supp(x_i\cup x_j)=\frac{\sigma(x_i\cup x_j)}{|T|},
\]
где \(|T|-\) общее число транзакций.
Confidence (достоверность)
Данный показатель характеризует насколько часто срабатывает наше правило:
\[
conf(x_i\cup x_j)=\frac{supp(x_i\cup x_j)}{supp(x_i)}.
\]
Lift (поддержка)
Показатель поддержки представляет собой отношение "зависимости" элементов транзакции к их "независимости" и, естественно, показывает насколько эти элементы зависят один от другого
\[
lift(x_i\cup x_j)=\frac{supp(x_i\cup x_j)}{supp(x_i)\times supp(x_j)}.
\]
Если значение \(lift(x_i\cup x_j)=1\), то транзакции с \(x_i\) и \(x_j\) независимы и правил их совместной покупки нет. Если значение
\(lift(x_i\cup x_j)>1\), то значение \(lift(x_i\cup x_j)-1\) характерирует ассоциативное правило, чем это значение больше, тем правило "правильнее",
если же \(lift(x_i\cup x_j)\lt 1\), то покупка \(x_j\) негативно сказывается на покупке \(x_i\).
Conviction (убедительность)
Величина
\[
conv(x_i\cup x_j)=\frac{1-supp(x_j)}{1-conf(x_i\cup x_j)}
\]
характеризует ошибки ассоциативного правила. Чем результат действия больше единицы, чем более надежно правило. Если значение равно Infinity, то
правило тривиальное.
Leverage (усиление)
Показатель усиления характеризует насколько интересной может быть более высокая частота выпадения элементов в транзакции в сочетании с более низким подъемом
\[
lever(x_i\cup x_j)=supp(x_i\cup x_j)-supp(x_i)\times supp(x_j).
\]
Для поиска устойчивого ассоциативного правила напомним терминологию -
Кортежи - это транзакции, пары атрибут-значение - элементы.
Правило ассоциации : {A, B, C, D, ...} => {E, F, G, ...}, где A, B, C, D, E, F, G, ... являются элементами ,
Достоверность(точность) A => B: P (B | A) = (количество транзакций, содержащих как A, так и B) / (количество транзакций, содержащих A).
Поддержка (покрытие) A => B: P (A, B) = (количество транзакций, содержащих как A, так и B) / (общее количество транзакций)
Мы ищем правила, которые превышают заранее определенную поддержку (минимальную поддержку ) и имеют высокую степень достоверности.
Частые наборы элементов представляют собой наборы с желаемой минимальной поддержкой.
Заметим, что если {A, B} является частым набором элементов, то и A, и B также являются частыми наборами элементов. Обратное, однако, неверно.
Первый алгоритм поиска ассоциативных правил был разработан в 1993 г. сотрудниками исследовательского центра IBM, что сразу возбудило интерес к этому направлению. Каждый год появлялось несколько новых алгоритмов
(DHP, Partition, DIC и др.), из которых наиболее известным остался алгоритм “Apriori” (Agrawal, Srikant, 1994).
Полный перебор (метод «грубой силы» -brute force).
Ясно, что полным перебором можно решить любую задачу, решение которой лежит в ограниченном множестве (сила есть - ума не надо). Другое дело - цена вопроса.
Для небольшого числа транзакций вполне можно воспользоваться следующим алгоритмом.
Сгенерировать все возможные подмножества наборов элементов, за исключением пустого набора (\(2^n - 1\)), и используйте их как следствия правила
(остальные элементы использовать в качестве априорных данных).
Вычислите доверие: разделите поддержку элемента, установленную на поддержку предшествующего элемента.
Выберите правила с высокой достоверностью (используя порог).
Можно этот алгоритм слегка улучшить.
Лучший способ: итеративная генерация правил с минимальной точностью.
Наблюдение: если выполняется n-последовательное правило, то также выполняются все соответствующие (n-1) -концептивные правила.
Алгоритм: генерировать n-последовательных правил-кандидатов из (n-1) -концептивных правил (аналогично алгоритму для наборов элементов).
Apriory
Частые наборы предметов: наборы предметов с желаемой минимальной поддержкой.
Замечание: если {A, B} является частым набором элементов, то и A, и B также являются частыми наборами элементов. Обратное неверно.
Основная идея (алгоритм Apriori):
Найти все наборы из n предметов. Пример (n = 2): L2 = {{A, B}, {A, D}, {C, D}, {B, D}}
Генерация (n + 1) наборов элементов путем объединения наборов из n элементов. L3 = {{A, B, C}, {A, C, D}, {A, B, D}, {B, C, D}}.
Проверьте вновь сгенерированные наборы (n + 1) -элементов на минимальную поддержку.
Из L3 исключите наборы, которые содержат нечастые наборы из 2 предметов.
Протестируйте оставшиеся наборы элементов на минимальную поддержку, посчитав их вхождения в данные.
Увеличивайте n и продолжайте, пока не будут сгенерированы более частые наборы элементов.
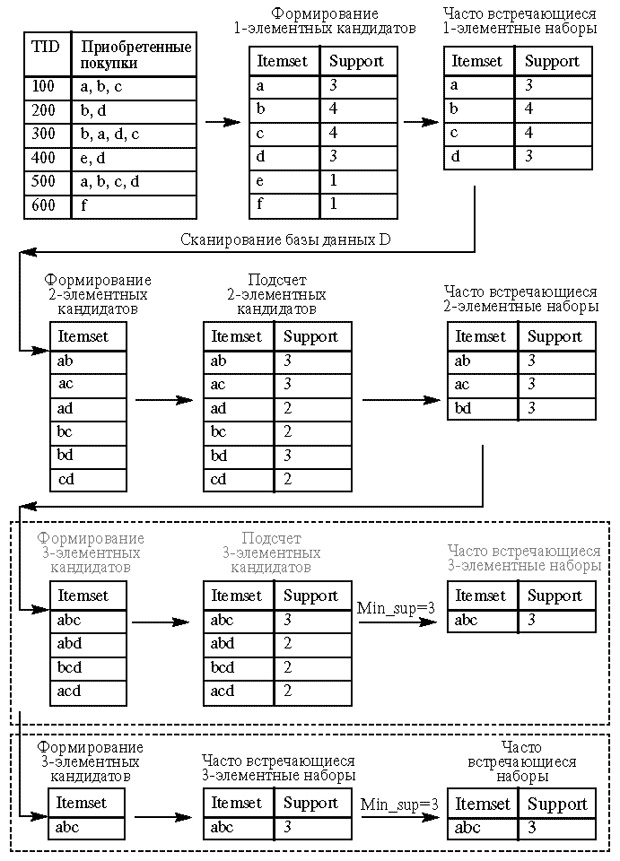
Схематически алгоритм выглядит следующим образом (значение поддержки-support можно не нормировать).
Рассмотрим пошаговое применение Apriory к рассматриваемому примеру.
Наиболее часто встречаемые одноэлементные наборы по порогу 2.
Далее из этих элементов сформируем наиболее часто встречающиеся по порогу 2 двухэлементные наборы .
Значение confidence (достоверность) характеризует насколько часто срабатывает правило. Если confidence=1, то правило срабатывает всегда. Тривиальный случай.
Если Lift>1, то приобретение одного товара, способствует приобретению другого.
Значение Conviction>1 характеризует надежность правила.
Исходя из этих характеристик, выберем наиболее надежные правила.
Далее из элементов, входящих в данные пары, сформируем тройки. Заметим, что в этом случае
\(
conf(x_i\cup x_j\cup x_k)=\frac{supp(x_i\cup x_j\cup x_k)}{supp(x_i\cup x_j)}.
\)