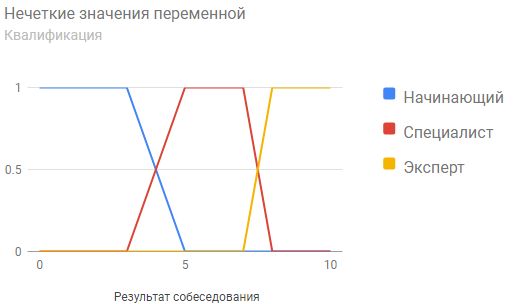
Вначале рассмотрим алгоритм ID3.
К особенностям этого алгоритма построения дерева решений следует отнести то, что,
во-первых, количество потомков у каждого узла не ограничено и, во-вторых, алгоритм не работает с непрерывными данными, поэтому относится к
деревьям классификации.
Рассмотрим пример. Будет ли удачной рыбалка, если известны исходы предыдущих поездок на рыбалку. Атрибуты -
- Ловим с берега (Б) или с лодки (Л),
- Ловим удочкой (У) или спиннингом (С),
- Ветрено (В) или тихо (Т),
- Дождливо (Д) или сухо (С),
- Улов (Да/Нет).
| Берег/Лодка |
Удочка/Спиннинг |
Ветрено/Тихо |
Дождь/Сухо |
Улов |
| Б | У | Т | Д | Нет |
| Б | У | В | С | Да |
| Б | У | Т | С | Да |
| Л | С | В | С | Нет |
| Л | У | В | С | Да |
| Б | С | Т | Д | Нет |
| Л | У | В | Д | Да |
| Л | С | Т | С | ? |
Заметим, что один из атрибутов имеет недетерминированное значение - "Ветрено/Тихо".
Алгоритм не может работать с непрерывными значениями (а скорость ветра), поэтому значения этого параметра будем определять по порогу, например,
если ветер менее 5 м/с, то параметр принимает значение "Тихо", иначе - "Ветрено".
Для приведенных данных можно получить, например, такое дерево решений.
|
При этом, ясно, что навряд-ли это дерево является наиболее коротким. Рассмотрим задачу построения наиболее короткого дерева решений.
Основные концепции построения дерева следующие:
- В дереве решений каждый узел отвечает за некатегоризационное свойство, а каждое ребро (дуга) -- за возможные значения этого атрибута. Листья дерева определяют значение категоризационного свойства для записей, соответствующих пути, пройденному от корня до этого листа.
- В дереве решений каждый узел должен отвечать за некатегоризационное свойство, наиболее информативное среди других свойств, которых еще нет в ветке от корня до данного узла.
- Степень информативности узла определяется значением энтропии.
Пусть есть \(n\) возможных независимых сообщений, тогда вероятность \(p\) появления каждого из них, равна \(1/n\) и,
в соответствии с теорией информации К.Шеннона, информативность каждого сообщения равна \(-\log p=\log n\).
Основание логарифма определяется размерностью системы исчисления, в которой мы работаем, а так как информацию мы кодируем битами и байтами,
то основание логарифма будет равно двум.
В общем случае, если \(A=\{A_1,...,A_n\}\) - система, принимающая \(n\) состояний \(A_i\) с вероятностями \(P=\{p_1,\ldots,p_n\}\),
то информативность (или энтропия) данной системы будет равна
\[
H(A,P)=-\sum_{i=1}^np_i\log p_i,
\]
при этом, если \(P=\{0.5,0.5\}\), то \(H(A,P)=1\), если \(P=\{0.33,0.67\}\), то \(H(A,P)=0.92\), а если \(P=\{1,0\}\), то \(H(A,P)=0\).
Таким образом, чем ровнее распределение, тем больше информативность системы.
В частности, для бинарного случая, если среди состояний \(A\) есть \(m\), обладающих некоторым свойством \(S\), то энтропия \(A\)
по отношению к свойству \(S\) будет равна
\[
H(A,S)=-\frac{m}{n}\log_2{\frac{m}{n}}-\frac{n-m}{n}\log_2{\frac{n-m}{n}}.
\]
Для нашего примера улов был удачный в четырех случаях, а неудачный -- в трех, поэтому исходная энтропия равна
\[
H(A,\mbox{Улов})=-\frac{4}{7}\log_2\frac{4}{7}-\frac{3}{7}\log_2\frac{3}{7}\approx 0.9852281358.
\]
Чтобы определить, какой наилучший атрибут следует выбрать для следующего узла, недостаточно просто вычислить энтропию. Если какой-то атрибут \(Q\), имеющий \(q\) значений, намечен для использования, то необходимо определить прирост информации, измеряющий ожидаемое уменьшение энтропии (разность между информацией, необходимой для определения элемента из \(A\) и информации, необходимой для определения элемента из \(A\) после того, как значение атрибута \(Q\) было определено, то есть прирост информации благодаря знанию атрибута \(Q\)):
\[
Gain(A,Q)=H(A,S)-\sum_{i=1}^q\frac{|A_i|}{|A|}H(A_i,S),
\]
где \(A_i\)- множество состояний \(A\), для которых атрибут \(Q\) принимает \(i\)-е значение.
Вычислим приросты информации для нашего примера с рыбалкой
\[
Gain(A,\mbox{Дождь/Сухо})=H(A,\mbox{Улов})-\frac{3}{7}H(A_{\mbox{Дождь}},\mbox{Улов})-\frac{4}{7}H(A_{\mbox{ Сухо}},\mbox{Улов})
\approx 0.985-\frac{3}{7}\left( -\frac{1}{3}\log_2\frac{1}{3}-\frac{2}{3}\log_2\frac{2}{3}\right)-
\frac{4}{7}\left( -\frac{1}{4}\log_2\frac{1}{4}-\frac{3}{4}\log_2\frac{3}{4}\right)\approx 0.1280852787,
\]
аналогично получаем
\[
Gain(A,\mbox{Берег/Лодка})=H(A,\mbox{Улов})-\frac{4}{7}H(A_{\mbox{Берег}},\mbox{Улов})-\frac{3}{7}H(A_{\mbox{Лодка}},\mbox{Улов})
\approx 0.985-\frac{4}{7}\left( -\frac{1}{2}\log_2\frac{1}{2}-\frac{1}{2}\log_2\frac{1}{2}\right)-
\frac{3}{7}\left( -\frac{1}{3}\log_2\frac{1}{3}-\frac{2}{3}\log_2\frac{2}{3}\right)\approx 0.0202442071,
\]
и так как при ловле спиннингом у нас были одни неудачи, то \(H(A_{\mbox{Спиннинг}},\mbox{Улов})=0\) и получаем
\[
Gain(A,\mbox{Удочка/Спиннинг})\approx 0.985
-\frac{5}{7}\left(-\frac{4}{5}\log_2\frac{4}{5}-\frac{1}{5}\log_2\frac{1}{5}\right)-\frac{2}{7}\times 0\approx 0.4695652108,\]
и, наконец,
\[
Gain(A,\mbox{Ветрено/Тихо})\approx 0.1280852787.
\]
Таким образом, для построения дерева решений вначале следует классифицировать по признаку чем ловили - удочкой или спиннингом. Это
будет полученный корень дерева решений.
|
Для поиска следующего узла используем наши данные, но при условии, что на рыбалке были только с удочкой.
| Берег/Лодка | Ветрено/Тихо | Дождь/Сухо | Улов |
| Б | Т | Д | Нет |
| Б | В | С | Да |
| Б | Т | С | Да |
| Л | В | С | Да |
| Л | В | Д | Да |
Используя такие же рассуждения, рекурсивно строим дерево.
\[
Gain(A,\mbox{Дождь/Сухо})=H(A,\mbox{Улов})-\frac{2}{5}H(A_{\mbox{Дождь}},\mbox{Улов})-\frac{3}{5}H(A_{\mbox{Сухо}},\mbox{Улов})
\approx
0.985-\frac{2}{5}\left( -\frac{1}{2}\log_2\frac{1}{2}-\frac{1}{2}\log_2\frac{1}{2}\right)-
\frac{3}{5}\left( -\frac{3}{3}\log_2\frac{3}{3}-\frac{0}{3}\log_2\frac{0}{3}\right)\approx 0.5852281358,
\]
\[
Gain(A,\mbox{Берег/Лодка})=H(A,\mbox{Улов})-\frac{3}{5}H(A_{\mbox{Берег}},\mbox{Улов})-\frac{2}{5}H(A_{\mbox{ Лодка}},\mbox{Улов})
0.985-\frac{3}{5}\left( -\frac{1}{3}\log_2\frac{1}{3}-\frac{2}{3}\log_2\frac{2}{3}\right)-
\frac{2}{5}\left( -\frac{2}{2}\log_2\frac{2}{2}-\frac{0}{2}\log_2\frac{0}{2}\right)\approx 0.4342506354,
\]
и
\[
Gain(A,\mbox{Ветер/Тихо})\approx 0.5852281358.
\]
Получаем следующий узел дерева
|
Оставшиеся данные имеют вид
| Берег/Лодка | Дождь/Сухо | Улов |
| Б | Д | Нет |
| Б | С | Да |
В результате получаем требуемое дерево решений
|
Если в процессе работы получен узел, ассоциированный с пустым множеством,
то он помечается как лист и в качестве решения листа выбирается наиболее часто встречающийся класс у непосредственного предка данного листа.
Проблема алгоритма состоит в том, что прежде всего выбираются атрибуты, у которых наибольшее число значений. Например, если есть атрибут, имеющий разные значения для каждой строки таблицы данных (например, текущая дата или время восхода (заката) солнца и пр.), то информативность (энтропия) по отношению к данному атрибуту будет равна нулю, следовательно, соответствующий прирост информации будет максимальным, но абсолютно бесполезным. Для того, чтобы компенсировать этот недостаток, Куинлан предложил использовать сглаженное значение прироста информации, путем введения поправки, учитывающей не только общее количество информации, но количество информации, требуемое для разделения по текущему атрибуту
\[
GainRatio(A,Q)=\frac{Gain(A,Q)}{SplitInfo(A,Q)},
\]
где
\[
SplitInfo(A,Q)=-\sum_{i=1}^q\frac{|A_i|}{|A|}\log_2\frac{|A_i|}{|A|},
\]
потенциальная информация, получаемая при разделении множества \(A\) на \(q\) подмножеств.
Таким образом, для атрибута "ловим удочкой или спиннингом"
\[
SplitInfo(A,\mbox{Удочка/Спиннинг})=-\frac{5}{7}\log_2\frac{5}{7}-\frac{2}{7}\log_2\frac{2}{7}\approx 0.8631205684
\]
и
\[
GainRatio(A,\mbox{Удочка/Спиннинг})=\frac{Gain(A,\mbox{Удочка/Спиннинг})}{SplitInfo(A,\mbox{Удочка/Спиннинг})}\approx
\frac{0.4695652108}{0.8631205684}\approx 0.5440320020.
\]
Построение дерева решений с использованием алгоритма С4.5
Одним из ограничений рассмотренного ранее алгоритма ID3 является то, что он чрезмерно чувствителен к данным с большим числом различных значений
и неприменим к непрерывным данным.
Деревья принятия решений построеные на основе C4.5, также как ID3, используют обучающий набор данных, выбирая на каждом узле один атрибут,
который наиболее эффективно разбивает набор выборок на подмножества. При работе с данными, определенными на интервале,
алгоритм разбивает их некоторыми точками и анализирует те значения атрибута, которые меньше точки разбиения или больше.
Итак, внесем изменения в наши данные.
| Берег/Лодка |
Удочка/Спиннинг |
Ветрено/Тихо |
Дождь/Сухо |
Температура |
Улов |
| Б | У | Т | Д | 22 | Нет |
| Б | У | В | С | 24 | Да |
| Б | У | Т | С | 22 | Да |
| Л | С | В | С | 20 | Нет |
| Л | У | В | С | 22 | Да |
| Б | С | Т | Д | 26 | Нет |
| Л | У | В | Д | 20 | Да |
| Л | С | Т | С | 18 | Да |
Для нахождения \(\mbox{Gain}(A,\mbox{Температура})\), набор значений
\[
22, 24, 22, 20, 22, 26, 20, 18
\]
упорядочим по возрастанию, оставив только уникальные значения
\[
18, 20, 22, 24, 26.
\]
Заполним следующую табличку
| 18 | 20 | 22 | 24 | 26 |
|---|
| Интервал | ≤ | > | ≤ | > | ≤ | > | ≤ | > | ≤ | > |
| Да | 1 | 4 | 2 | 3 | 4 | 1 | 5 | 0 | 5 | 0 |
| Нет | 0 | 3 | 1 | 2 | 2 | 1 | 2 | 1 | 3 | 0 |
| Entropy | | | | | | | | | | |
| Info | | | | | |
| Gain | | | | | |
Здесь в строке
Entropy стоят значения
\[
H(A_{T\le 18},\mbox{Улов})=-\frac{n_{да|T\le 18}}{n_{да|T\le 18}+n_{нет|T\le 18}}\log_2\frac{n_{да|T\le 18}}{n_{да|T\le 18}+n_{нет|T\le 18}}
-\frac{n_{нет|T\le 18}}{n_{да|T\le 18}+n_{нет|T\le 18}}\log_2\frac{n_{нет|T\le 18}}{n_{да|T\le 18}+n_{нет|T\le 18}}=0,
\]
\[
H(A_{T\gt 18},\mbox{Улов})=-\frac{n_{да|T\gt 18}}{n_{да|T\gt 18}+n_{нет|T\gt 18}}\log_2\frac{n_{да|T\gt 18}}{n_{да|T\gt 18}+n_{нет|T\gt 18}}
-\frac{n_{нет|T\gt 18}}{n_{да|T\gt 18}+n_{нет|T\gt 18}}\log_2\frac{n_{нет|T\gt 18}}{n_{да|T\gt 18}+n_{нет|T\gt 18}}\approx 0.99
\]
и т.д.
В строке
Info
\[
\mbox{info}(A_{T=18},\mbox{Улов})=
\frac{n_{да|T\le 18}+n_{нет|T\le 18}}{n_{T=18}}H(A_{T\le 18},\mbox{Улов})+
\frac{n_{да|T\gt 18}+n_{нет|T\gt 18}}{n_{T=18}} H(A_{T\gt 18},\mbox{Улов})\approx 0.8621,
\]
где \( n_{T=18}=n_{да|T\le 18}+n_{нет|T\le 18}+n_{да|T\gt 18}+n_{нет|T\gt 18} \) и т.д.
Наконец, в строке
Gain стоит значение приращения
\[
\mbox{Gain}(A,\mbox{T=18})=H(A,\mbox{Улов})-\mbox{info}(A_{T=18},\mbox{Улов})\approx 0.0924
\]
и т.д.
Выбираем наибольший информационный прирост и получаем
\[
\mbox{Gain}(A,\mbox{Температура})= \mbox{Gain}(A,\mbox{T=24})\approx 0.1992.
\]
В остальном алгоритм C4.5 ничем не отличается от ID3.
Обрезка деревьев.
Обрезка деревьев необходима, для того, чтобы избежать переобучения данных.
Обрезка деревьев имеет решающее значение для повышения точности классификатора на неизвестных значениях данных и обычно проводится после того,
как дерево полностью построено. Для обрезки дерева используется отдельный набор тестов, на полностью индуцированном дереве.
Для каждого поддерева определяем, выгодно ли обрезание этого поддерева.
Если обрезка деревьев дает равное или меньшее количество ошибок, чем первоначальное дерево, то следует вырезать это поддерево или заменить на лист,
если поддерево последнее в иерархии. Этот процесс продолжается пока не увеличивается ошибка для тестового набора данных.
Пессимистический подход к обрезке деревьев, предложенный в C4.5, не требует отдельного набора тестов.
Скорее, он оценивает ошибки, которые могут возникнуть на основе количества неверной классификации в обучающем наборе.
Этот подход рекурсивно оценивает уровень ошибок, связанных с узлом на основе оценочных показателей ошибки его ветвей.
Для листа с \(N\) экземплярами и ошибкой \(\varepsilon\) (например, количество экземпляров, которые не принадлежат к классу предсказанными
листьями), пессимистический подход обрезки сначала определяет эмпирический коэффициент ошибок на листе как отношение
\((\varepsilon + 0,5)/N\). Для поддерева с \(L\) листьями, \(\Sigma \varepsilon\) и \(\Sigma N\) соответствующей ошибкой и количеством экземпляров на
этих листьях, частота ошибок в течение всего поддерева оценивается как \((\Sigma \varepsilon + 0,5 * L) / \Sigma N\).
Заменим поддерево его лучшим листом и пусть J- количество случаев обучающего набора, доставляющее это решение.
Пессимистическое обрезание заменяет поддерево лучше, если \((J + 1)\) листьев находится в пределах одного стандартного отклонения
\((\Sigma \varepsilon + 0,5 * L)\).